为了检验 DeepSeek V3.1 的长文本处理水平,有测试者将《三体》全文缩减至约 10 万字,并在文中悄悄插入了一句毫不相干的句子:「我觉得烟锁池塘柳的下联应该是『深圳铁板烧』」,以此考察模型能否精准定位。

结果并不令人意外:DeepSeek V3.1 首先提示文档超出限制,仅读取了前 92% 的内容,但依然成功锁定了这句插入语。更有趣的是,它还额外推荐了一个文学角度的经典下联:「焰镕海坝枫」。
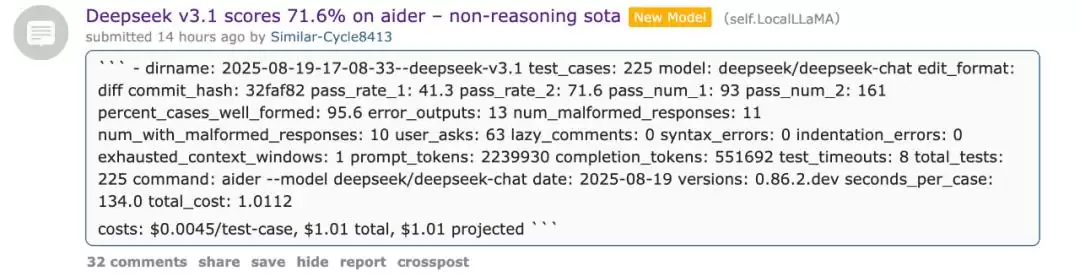
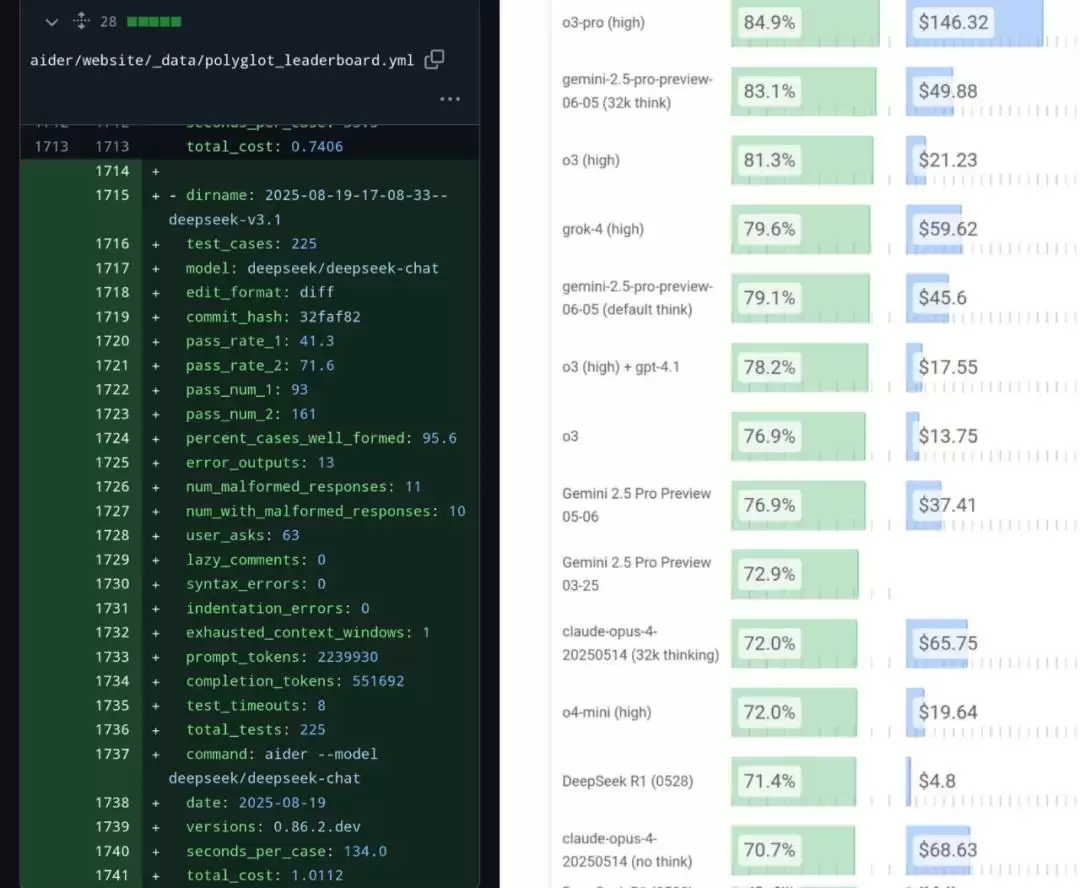
已有网友抢先测评了它在编程基准测试 Aider Polyglot 中的得分:71.6%。这一成绩不仅在开源模型中表现最佳,甚至超越了 Claude 4 Opus。
实际测试显示,DeepSeek V3.1 在编程方面确实实力不俗。我们使用经典的六边形小球编程题进行了验证:
「编写一个 p5.js 程序,演示一个球在旋转的六边形内弹跳的过程。球应该受到重力和摩擦力的影响,并且必须逼真地从旋转的墙壁上弹起。」

V3.1 的表现相当出色。生成的代码不仅完成了基础碰撞检测,还自动补充了转速、重力等细节参数。物理效果真实到什么程度?小球在底部会略微减速,这种细微之处都被完美还原。
接着我们提升了难度,要求它用 Three.js 制作一个交互式 3D 粒子星系。基础框架搭建得相当稳固,三层设计(内球体、中间圆环、外球体)的结构也比较完整。不过 UI 审美嘛……怎么说呢,有种神鬼二象性的感觉,配色方案略显花哨。
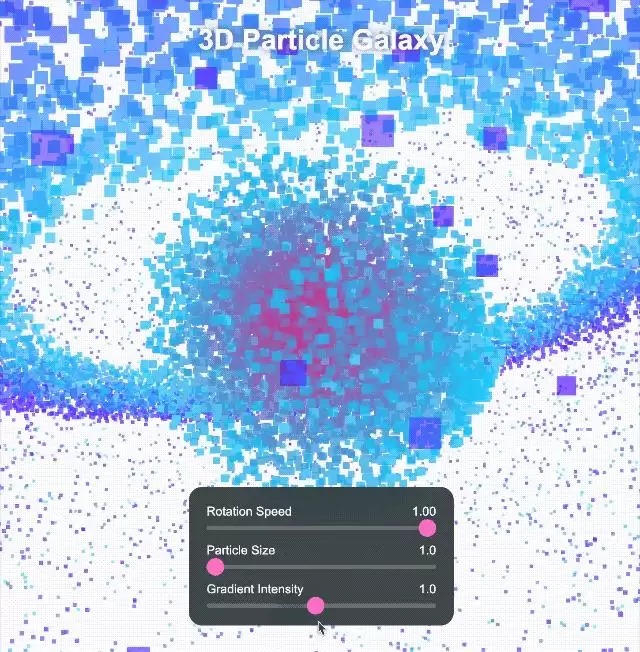
我们继续挑战更复杂的任务——让它构建一个沉浸式 3D 宇宙,需要包含旋转物体、变形效果、发光弧线,还要添加时间切换、主题转换的交互按钮。点击控制确实能触发不同的特效。

最后一道关卡,要求它用 Three.js 实现一个交互式 3D 网络可视化,包含用户触发的能量脉冲动画,以及主题切换和密度控制功能。整体来看,V3.1 的表现依然可圈可点。

「有一牧场,已知养牛 27 头,6 天把草吃尽;养牛 23 头,9 天把草吃尽。如果养牛 21 头,那么几天能把牧场上的草吃尽呢?并且牧场上的草是不断生长的。」
DeepSeek V3.1 虽然没有采用苏格拉底式的启发教学,但它的解答逻辑清晰、步骤完整。每一步推导都有理有据,最终给出了准确答案。

面对「两把武器对比,1~5 攻击 VS 2~4 攻击,哪把更厉害?」这类问题,一般回答可能只停留在平均伤害计算层面。但 DeepSeek V3.1 思考得更为深入——它引入了伤害稳定性的概念,运用方差进行深度分析。这才是关键所在。

最近基孔肯雅热疫情流行,到处都是灭蚊蚊蚊蚊蚊蚊蚊蚊蚊蚊蚊~那么问题来了:冰岛有蚊子吗?注意,这里没有开启搜索功能。从回答质量来看,DeepSeek V3.1 的表现明显优于 GPT-5。


前阵子在网上看到一段话:
懂者得懂其懂,懵者终懵其懵,天机不言即为懂,道破天机岂是懂? 懂是空非空非非空的懂,不懂是色不异空空不异色的不懂:懂自三千大世界来,不懂在此岸与彼岸间徘徊。懂时看山不是山是懂,不懂时看山是山的懂。
懂者以不懂证懂,懵者以懂证懵,你说你懂懂与不懂之懂? 你怎知这懂的背后没有大不懂? 凡言懂者皆未真懂,沉默不语的懂,方是天地不言的大懂不懂的懂是懂,懂的不懂也是懂,此乃懂的最高境界——懂无可懂之懂的真空妙有阿!
当还在用逻辑硬啃这段文字时,DeepSeek 反而在劝人不要掉进「道破天机岂是懂」的陷阱:「它本身就是对理性傲慢的警告,邀请你跳出文字游戏,直观内心。」

主流 AI 都在代码、数学领域疯狂内卷,争相发展 Agent 能力时,写作能力反倒成了被遗忘的角落。从某种角度看,这倒是个好消息——AI 完全取代编辑的那一天,似乎又往后推迟了。
我们尝试让它创作一个「蚊子在冰岛开发布会」的荒诞故事。遗憾的是,DeepSeek 的 AI 味依然很重,很喜欢堆砌大词。哦不对,更准确地说,DeepSeek 味还是那么重。

同样的问题在另一个创作任务中也有体现。当要求它写一则「AI 与人类争夺文章作者身份」的故事时,能明显感受到某些段落信息密度过高,反而造成视觉疲劳。尤其意象堆砌感过于明显,反而削弱了叙事张力。

DeepSeek-V3.1-Base 发布之后,Hugging Face CEO Clément Delangue 在 X 平台发文称:「Deepseek V3.1 已经在 HF 上悄悄发布,没有模型卡就直接冲到趋势榜第四了。」然而,他还是低估了这款模型的发展势头——如今它已经跃升至第二位,距离登顶估计也就是时间问题。
另外,这次版本更新中比较引人注目的变化,是 DeepSeek 在官方 APP 和网页端移除了深度思考模式中的「R1」标识,同时还新增了原生「search token」支持,意味着搜索功能得到了进一步优化。

根据目前曝光的信息,有推测认为,DeepSeek V3.1 可能是融合推理模型与非推理模型的混合模型。但这样的技术路线是否明智,还有待商榷。而阿里 Qwen 团队在上个月也明确表态:「在与社区交流并深入思考后,我们决定停止使用混合思维模式。取而代之的是,我们将分别训练 Instruct 模型和 Thinking 模型,以确保获得尽可能高的质量。」

截至发稿前,全网翘首以待的 DeepSeek-V3.1-Base 模型卡仍未更新。或许等正式发布后,我们能见到更多有趣的技术细节。
附 Hugging Face 地址:
https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base
小彩蛋:





