人人拥有贾维斯?浙大团队OS Agents综述讲明白了
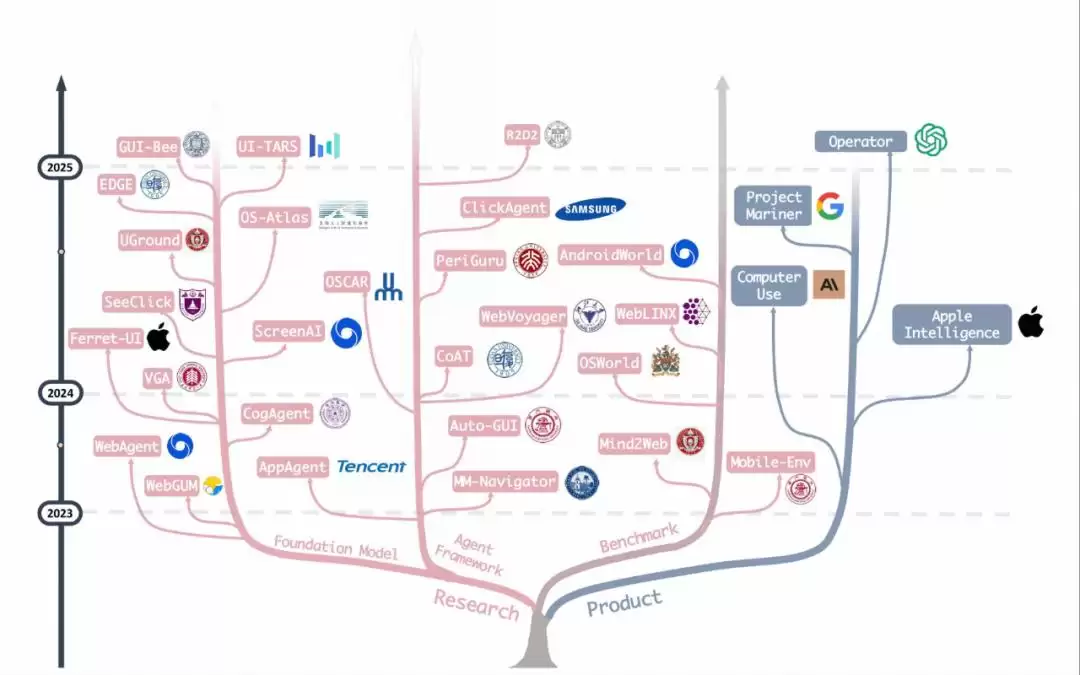
图|OS Agents 领域在近些年的发展进程,包括基础模型、Agent 框架、基准测试和产品等。
如果一年前有人跟你说,AI不仅能聊天,还能直接替你在电脑上点外卖、填报销单、订酒店,你会不会觉得这离现实还有点远?但过去这一年,AI圈里一个叫“OS Agents”的新方向,正把这类场景从一个概念,变成可落地的产品。
简单来说,OS Agents 就是能直接“上手干活”的智能体——它存在于你的电脑、手机或浏览器里,接到指令后自动执行多步操作。不同于偏重对话的 Chatbot,这类Agent让“帮我干活”从口号变成了实际行动。
它指向的,是AI行业的下一个趋势:从“回答问题”升级为“全能操作员”。未来,每个人或许都能拥有一个属于自己的AI操作系统,跨平台完成任务,让工作和生活效率成倍提升。
最近,浙江大学团队与合作者发布了一篇关于OS Agents的综述,内容十分扎实,堪称入门必备。如果你正想了解这个领域的发展脉络、技术细节和未来方向,这份报告值得仔细看看。
综述基于多模态大语言模型(MLLM)的视角,系统梳理了Agent如何在不同平台和任务环境中发挥作用,也坦率指出了当前的技术瓶颈和潜在突破口。

论文链接:https://arxiv.org/abs/2508.04482
我们离JARVIS还有多远?
几乎每个看过《钢铁侠》的人,都幻想过拥有一个像J.A.R.V.I.S.那样的超级AI助手——能无缝操控各种系统、自动完成复杂任务。在AI行业,这种实体被称为OS Agents。它们通过操作系统提供的界面(比如图形用户界面GUI),在计算机或移动终端上完成用户交给的任务。如果这种Agent能大规模落地,全球数十亿用户的日常效率将迎来质变。
想象一下:网购、行程安排、文档处理……这些琐事都由Agent默默完成,而你只需要动下嘴或敲一行指令。这听起来像科幻,但基础已经铺开。
过去,Siri、Google Assistant这些虚拟助手曾让我们瞥见一点曙光,但受限于模型的理解能力,它们缺乏上下文理解,功能残缺,并未真正进入“袋里”阶段。
幸运的是,MLLM的快速进化改写了剧本。这些模型强大的理解与生成能力,让OS Agents能够琢磨透复杂任务,并精准操控计算设备去执行。
OS Agents是什么?
OS Agents利用操作系统提供的一切输入输出接口,通过计算设备回应你设定的目标。它的核心使命,就是自动化执行系统内部的任务,借助MLLM的理解与生成能力,把用户体验和操作效率拉上一个台阶。
实现这个目标,需要三个关键组成部分:环境、观察空间和动作空间。三者共同支撑Agent与操作系统之间的高效交互。
- 环境:Agent运行的平台或系统,可以是桌面系统、移动端或网页端。不同环境下任务各异,要求Agent能在多个界面间进行规划和推理。
- 观察空间:Agent能访问到的系统状态和用户活动信息。通过这些观察,Agent理解当前环境,做出明智决策,并决定下一步怎么走才能达成目标。
- 动作空间:Agent通过操作系统的输入接口来操控环境的所有可能方式。简单说,就是它能“按什么按钮”“点哪里”“怎么操作”。
除此之外,OS Agents还需要三项核心能力:理解、规划和grounding。理解能力让Agent看懂复杂的操作系统环境,这是完成信息检索和各类任务的基础。规划能力让它能把复杂目标拆解成可管理的子任务,并制定出执行序列。而grounding,则是将文本指令或计划转化为可执行的具体动作——说白了,就是把“怎么做”落地到界面上。
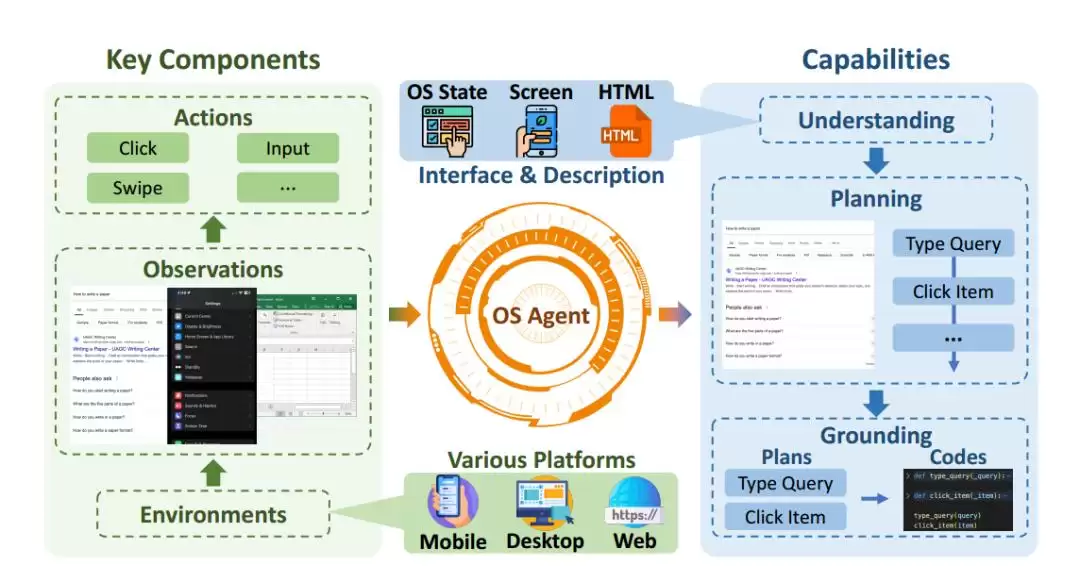
图|OS Agents 的基础原理。
构建“能用”的OS Agents
要让OS Agents真正“能用”,基础模型的建设是关键。这涉及两大方面:模型架构和训练策略。前者决定了模型在操作系统中如何处理输入输出,后者赋予模型完成复杂任务的能力。
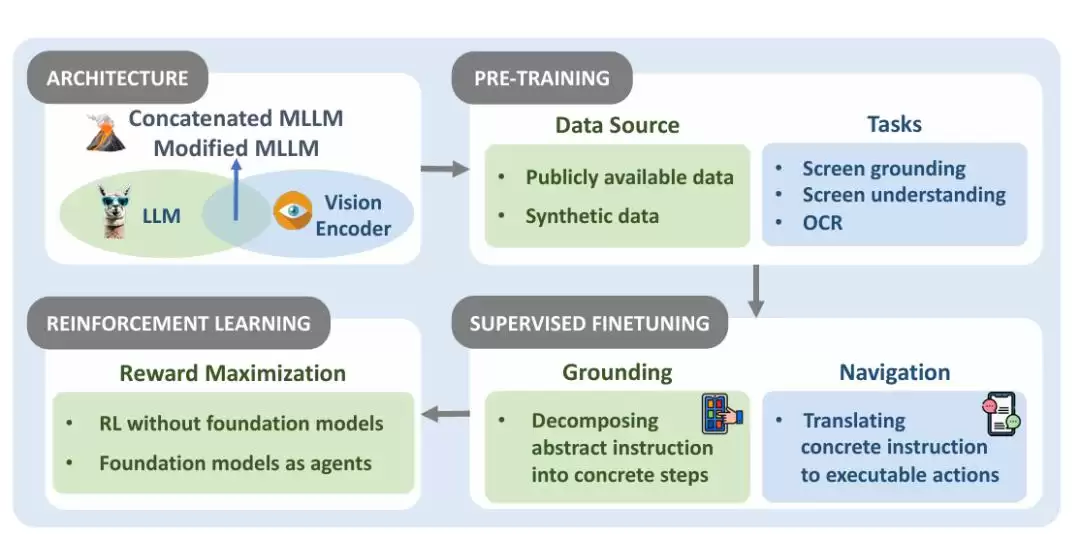
图|在基础模型构建中应用的训练策略
训练策略主要包括预训练、有监督微调和强化学习。近期应用于OS Agents的主流架构和策略可用下表概括:
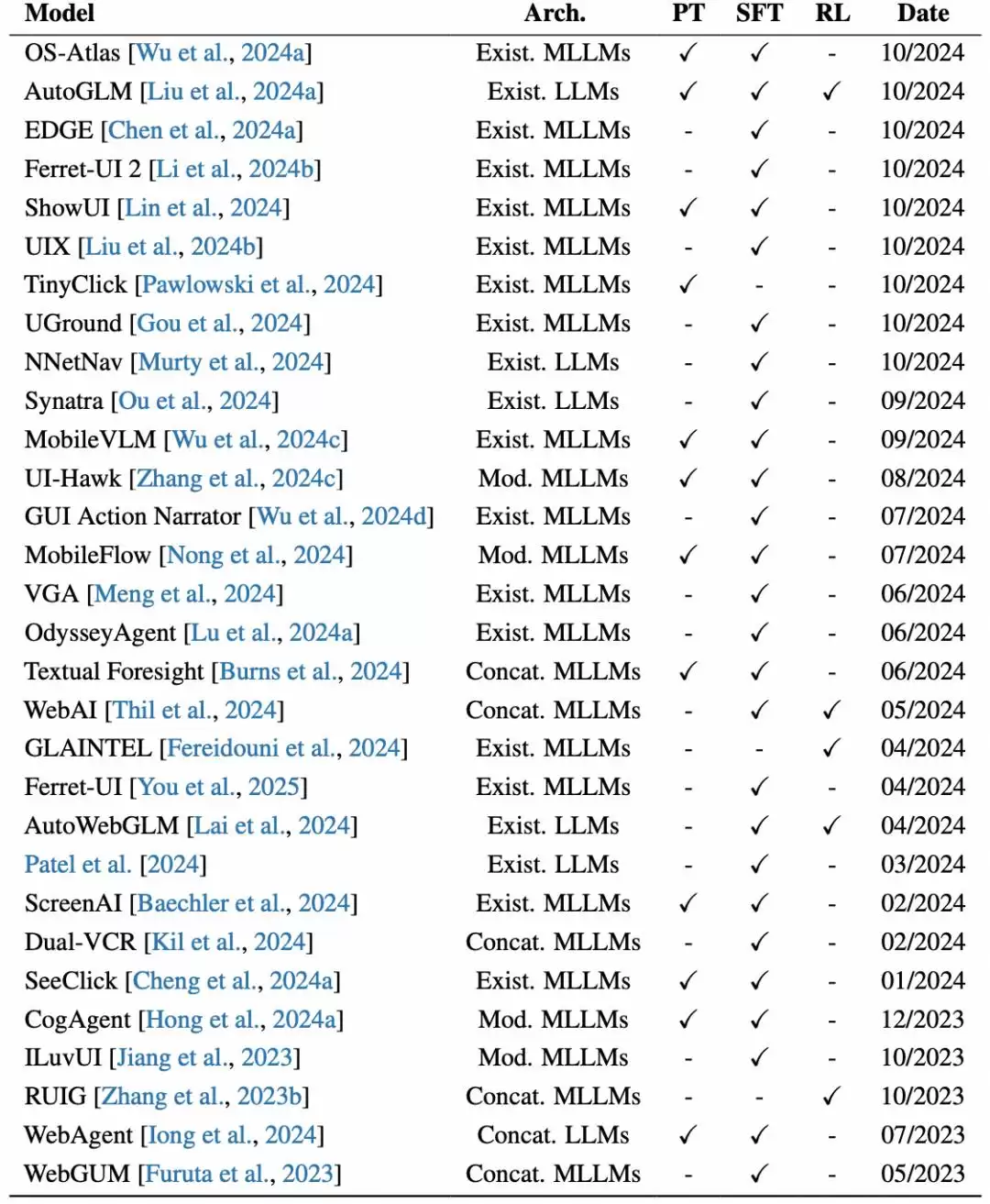
图|OS Agents 基础模型。Arch:架构,Exist:现有,Mod:修改,Concat:拼接,PT:预训练,SFT:监督微调,RL:强化学习
一个典型的OS Agents框架由四个核心组件构成:感知、规划、记忆和行动。感知模块负责收集和分析环境信息;规划模块负责任务分解与行动序列生成;记忆模块用于存储信息和积累经验;行动模块则负责执行具体的操作指令。这四个模块协同工作,才让Agent具备了理解、规划、记忆和与系统交互的完整能力。
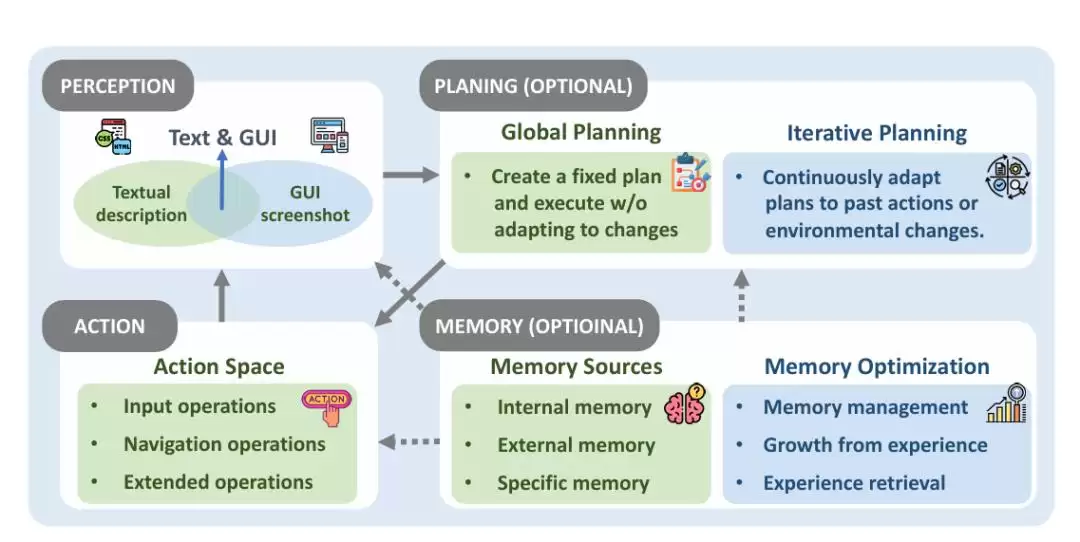
在实际实现中,不同框架会在这四个模块基础上衍生出具体的技术特征和实现方式。
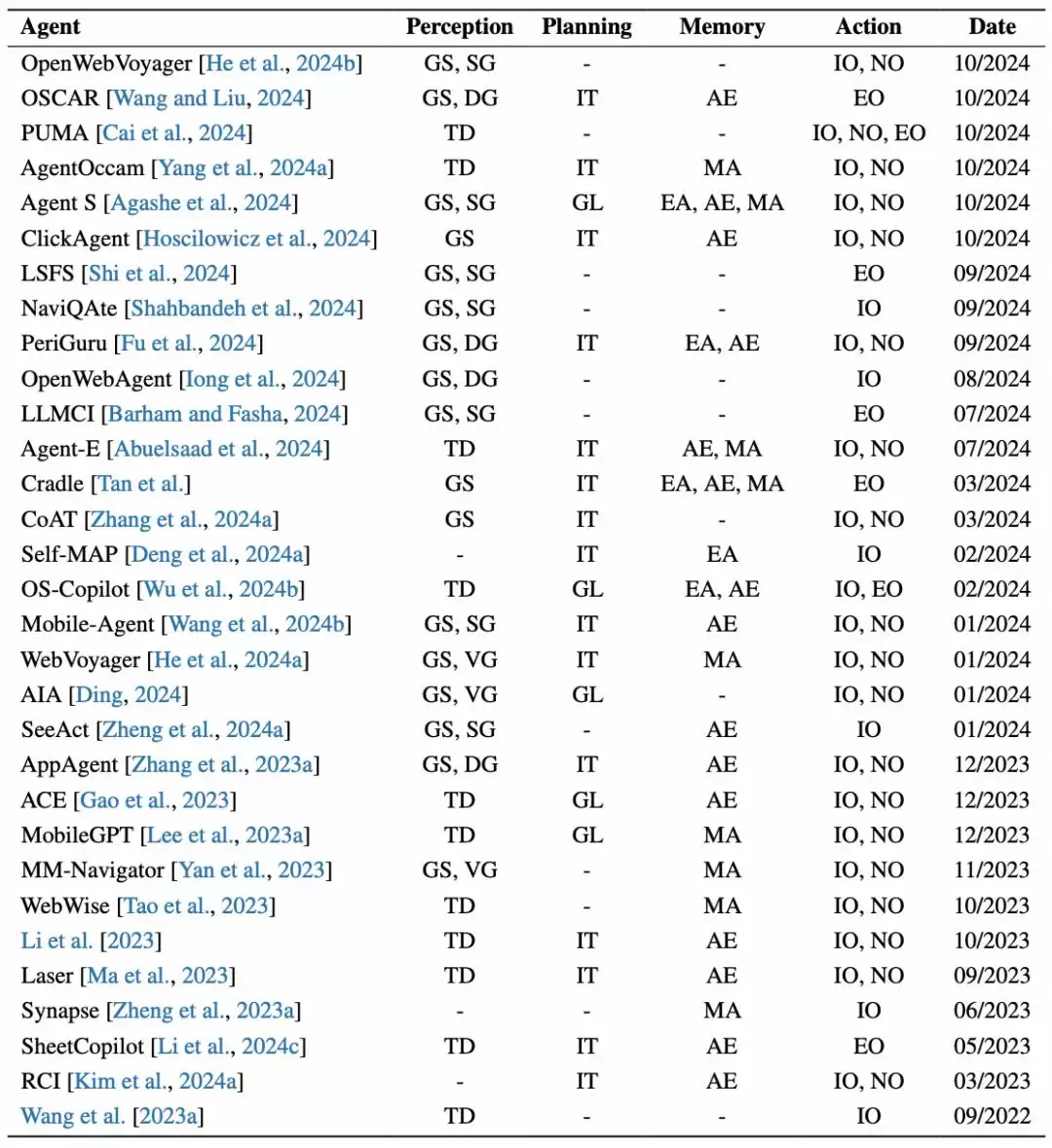
图|用于 OS Agents 的 Agents 框架,TD:文本描述,GS:GUI 屏幕截图,VG:视觉定位,SG:语义定位,DG:双重定位,GL:全局,IT:迭代,AE:自动化探索,EA:经验增强,MA:管理,IO:输入操作,NO:导航操作,EO:扩展操作。
评估是OS Agents开发中不可或缺的一环。它能帮助衡量Agent在不同场景下的表现和有效性。当前研究采用了多种评估技术,具体环境不同,评估方式也各不相同。评估的关键在于原则和方法,需要多角度、多技术结合,才能全面了解Agent的能力与局限。整个评估分为客观评估和主观评估,重点考察理解、规划和grounding三方面的能力。
为了全面测评,研究人员开发了多种基准测试。这些测试基于不同平台和配置,构建了多样的评估环境,覆盖了各类任务类型。
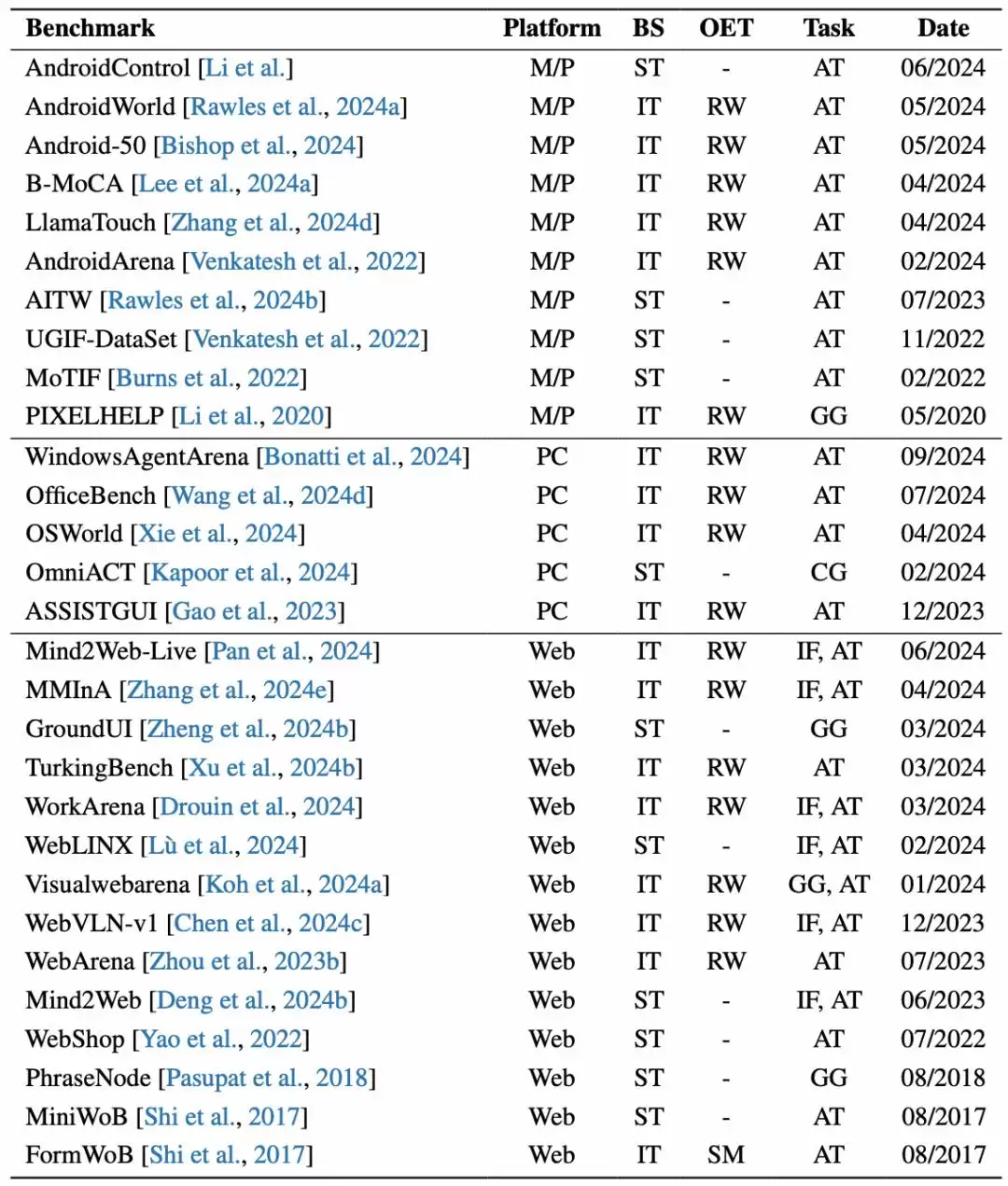
图|OS Agents 基准测试
挑战与未来
尽管OS Agents的进展令人兴奋,但该领域仍然面临不少硬骨头。
安全是落地时绕不开的红线。学术界已经开始了针对OS Agents的对抗攻击研究,一些团队也着手构建LLM Agents的安全框架与策略。未来的重点,是开发全面且可扩展的安全解决方案。而除了安全,隐私同样是不可忽视的隐忧。
正如电影里J.A.R.V.I.S.会根据Tony Stark的偏好提供个性化服务一样,开发个性化的OS Agents是AI研究的长期目标。目前,一些大模型(比如OpenAI的memory功能)已经开始朝这个方向迈出半步——让模型拥有“记住”的能力。但整体来看,多数(M)LLM在提供个性化体验和在人机交互中自我进化方面,还远远不够。
另一个重大挑战是记忆的模态扩展:从文本扩展到图像、语音,以及如何高效管理和检索这些记忆,都是摆在面前的技术难题。
研究人员相信,一旦攻克这些关卡,OS Agents就能提供更具个性化、动态且具备上下文感知能力的帮助。它们还将具备更复杂的自我进化机制,能够持续适应用户的需求和偏好。
MLLM的快速发展正在为OS Agents打开一扇扇新的大门。那个“人人拥有贾维斯”的梦想,正在一步步靠近现实。




