硅谷AI圈今年夏天的这场“诸神之战”,终于在5日晚上正式拉开了序幕。OpenAI在GPT-2之后,时隔多年再次拥抱开源,发布了一个号称“最强”的开源推理大模型gpt-oss。

谷歌这边自然也没闲着,直接丢出了一个“开天辟地”式的大杀器——Genie 3。这个模型可以让用户用一句话就生成一个长达数分钟的、可以交互的三维虚拟世界,效果相当炸裂。
而OpenAI的老冤家,那个不认AGI、只埋头在AI编程赛道上狂奔的Anthropic,同样不甘寂寞。它更新了自己最顶(gui)级的大模型:Claude Opus 4.1,将AI编程能力的上限又往上推了一把。

虽然从不同的维度来看,这三款新产品的发布都具有相当重要的意义,但这还只是未来几天硅谷AI圈“神仙打架”的序幕,好戏还在后头呢。
而且,就像这三家之前发布的所有产品一样,背后团队中,华人依然是中流砥柱。所以,就连硅谷的吃瓜群众,也在期待来自东方的DeepSeek和Qwen。希望国内的AI力量,不会缺席这场夏末的AI盛宴。

01 OpenAI终于迎来了他的DeepSeek时刻
OpenAI时隔6年,首次推出了“开放权重”的大语言模型:gpt-oss-120b和gpt-oss-20b。两个模型都采用了Transformer架构,并融入了MoE设计。其中gpt-oss-120b总参数1170亿,激活参数51亿;gpt-oss-20b总参数210亿,每token激活36亿参数。
模型采用了分组多查询注意力机制,组大小为8,以及旋转位置编码(RoPE),原生支持128k上下文。
从性能上看,OpenAI官方的说法是,这已经是目前同体量下开源推理模型中的SOTA了。
具体来说,gpt-oss-120b模型在核心推理基准测试中,已经能够实现与OpenAI o4-mini接近的性能,而且可以在单张80 GB GPU上高效运行。gpt-oss-20b在常见基准测试中能达到与OpenAI o3-mini类似的性能,可以在仅拥有16 GB内存的端侧设备上运行。
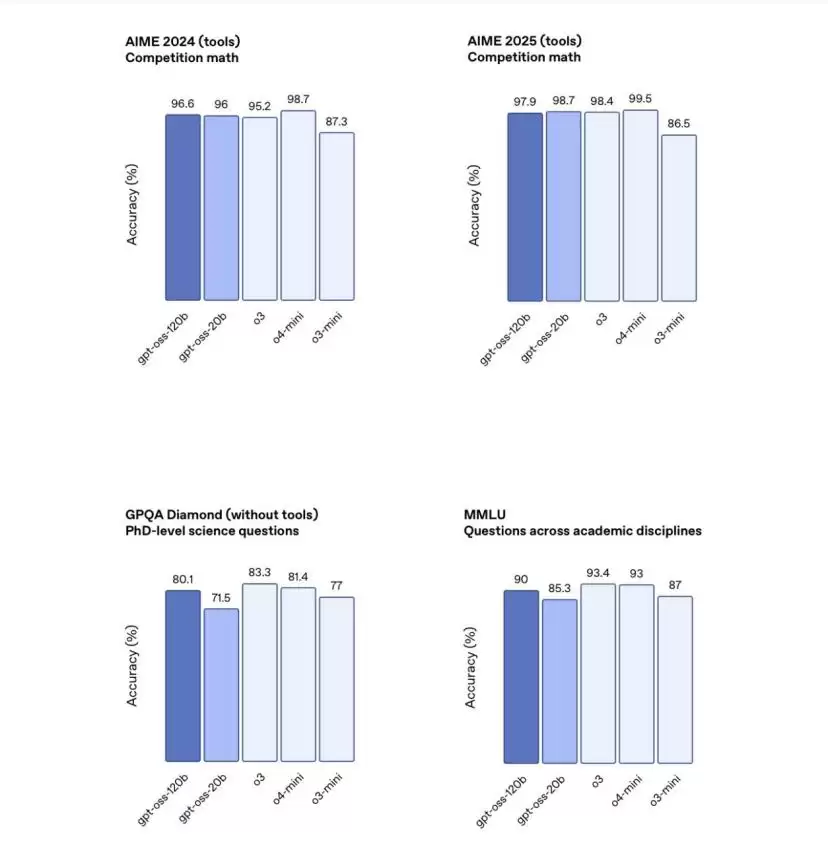
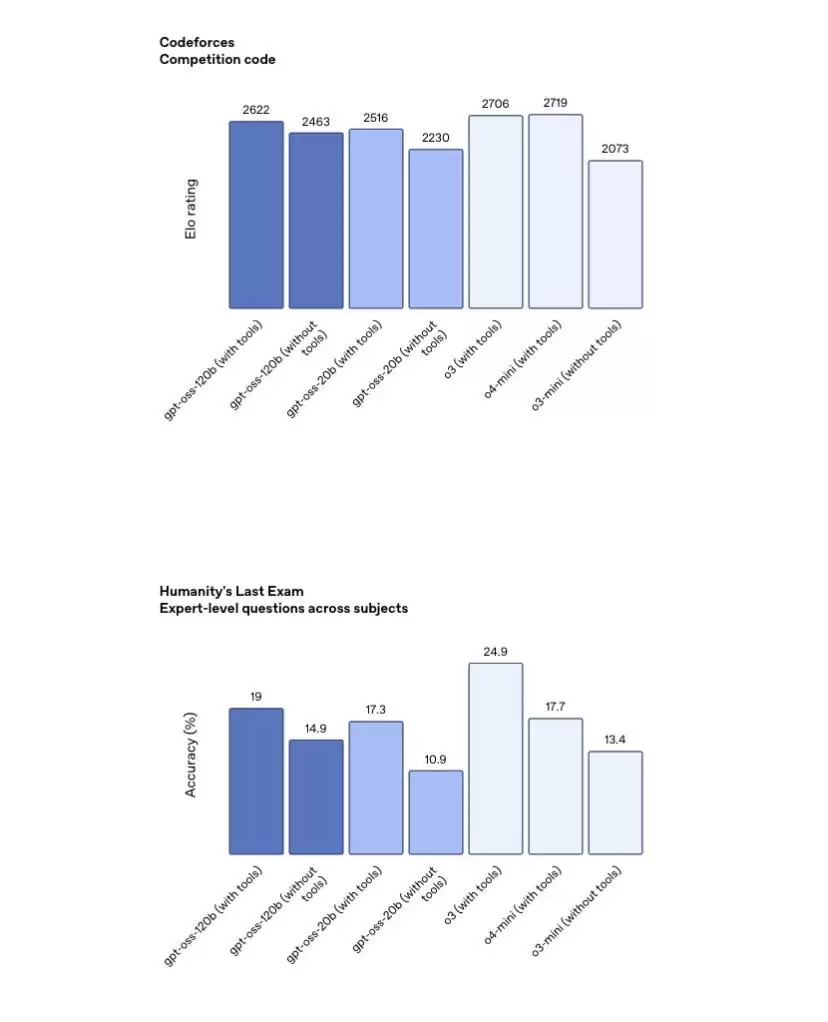
从模型体量来看,OpenAI这次放出的两个模型,明显是针对本地部署的需求和市场,补齐了之前产品层面的一个短板。不过在许可证里,依然很鸡贼地做了限制:不允许年收入高于1亿美元或者日活超过100万的实体进行商用。
发布之后,网友们也迫不及待地进行了本地化部署,从反馈来看,性能还不错。

在RTX5090上运行20B的版本,每秒能达到160-180tokens的输出速度。
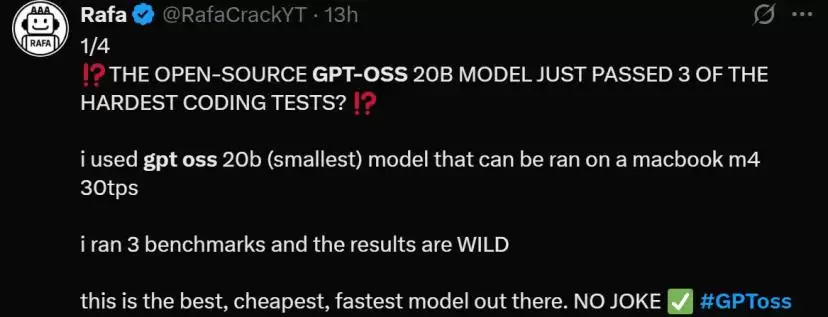
从模型的能力上看,用户的实际反馈也都不错。有网友在M4 MacBook上,一次就通过了3个常用的编程能力测试。
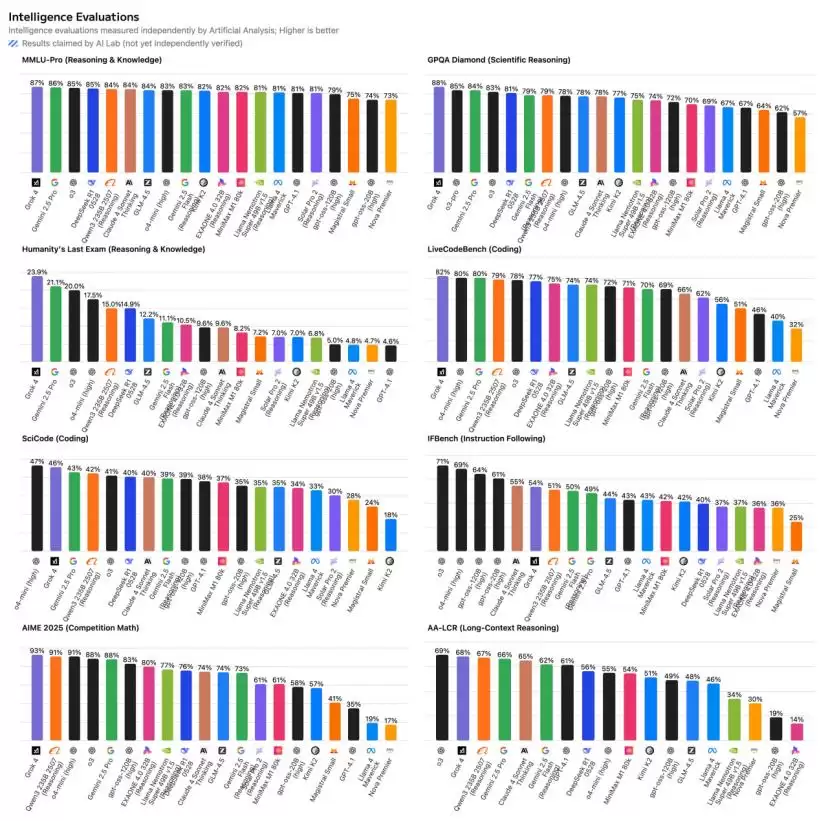
根据大模型能力测试机构Intelligence Evaluation公布的众测结果,OpenAI这两款模型在体量远小于DeepSeek R1和Qwen 3的情况下,性能却已经非常接近这两个中国的开源模型了。
客观地说,这次模型发布最大的意义,在于让OpenAI重新回到了开源牌桌上,也让用户多了一个可以方便单机本地部署、能力还不错的模型可以选择。不过,这也只能算是一次“补作业式”的发布。所有人对OpenAI的期待,依然落在之后到来的GPT-5上。到底OpenAI能给业界带来多大的震撼,我们拭目以待。
02 谷歌Genie 3:炸裂,但是期货
既然OpenAI没有放出GPT-5,谷歌自然也不会让OpenAI独吞流量,发布了一个非常“战未来”的模型——Genie-3。
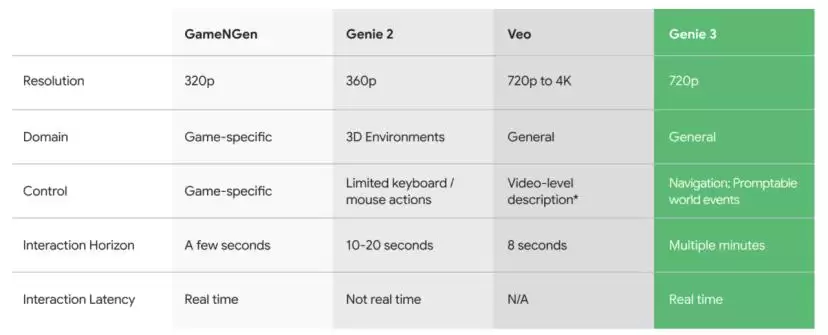
就像文章开头的视频展示的那样,这是一个文生虚拟世界的模型。用户可以用文字生成一个720p清晰度、24 FPS流畅度的动态世界,并且能够实时交互,具有非常好的一致性和真实感。用户可以通过文字或按钮的方式,自由控制、探索这个世界中的各个细节。

图注:走到一个铝架子旁边,然后走到那个大型的红色工业搅拌机旁边。
通俗一点来说,如果说像Sora或Veo 3这样的文生视频模型对应的是电影,那么Genie-3生成的就是一个游戏,或者说一个虚拟剧本杀。用户不仅是在屏幕前看这个世界,更可以主动地通过自己的行为,和这个生成的世界进行互动。
不同于视频模型的是,这样的“世界模型”需要对用户的行进进行实时的反馈和互动,而且还必须符合现实世界的基本逻辑规律。比如,你用手向后推一个漂浮的气球,气球不能向天上飞,而要向后飞;你用手轻推一辆汽车,它不能马上就高速跑起来。
所以,如果用户对于视频模型中一些小的瑕疵还能接受,那么世界模型就一定要对物理反馈处理得非常精准。虽然不一定能达到LeCun要求的“理解物理世界”的水平,但相比于视频模型生成的一闪而过的画面,如果生成的虚拟世界处理不好这些物理交互逻辑,那它就没有意义。
而从谷歌提供的Demo中可以看到,随着用户输入不同的指令,世界会实时给出不同的反馈,生成不同的内容。想要做到这一点,需要处理的技术问题是非常有挑战性的。

如果未来谷歌真的能把这路彻底跑通,且不说“世界模型”背后的技术对机器人和自动驾驶领域会不会产生碘伏性的改变,就算对VR、游戏以及文生视频赛道的影响,也将是难以想象的。
可惜的是,虽然Genie 3看起来足够惊艳,但依然停留在官方演示阶段。所有发布内容都是官方放出的,没有提供普通用户试用,还是经典的谷歌版“期货”。
但虽是期货,可现如今,这样具有跨时代意义的产品和技术突破,似乎也只有对AI进行饱和式火力覆盖的谷歌,才能做到。
从技术层面来讲,即便是像OpenAI这样的创业公司,也只能在Transformer这类模型上和谷歌形成你追我赶之势。虽然一年多以前,是OpenAI推出的Sora炸裂全场,拉爆了人们对于视频生成模型的期待,但真正有实力持续投入、在时间维度上保持领先的产品,依然是谷歌和它的Veo。而Genie 3,也是谷歌默默耕耘、迭代了数个大版本的成果。
考虑到即便是Transformer,也是发源于谷歌,希望它能善待每一株火苗,早日让我们感受到燎原的热浪。
03 偏科冠军的执着:2%提升
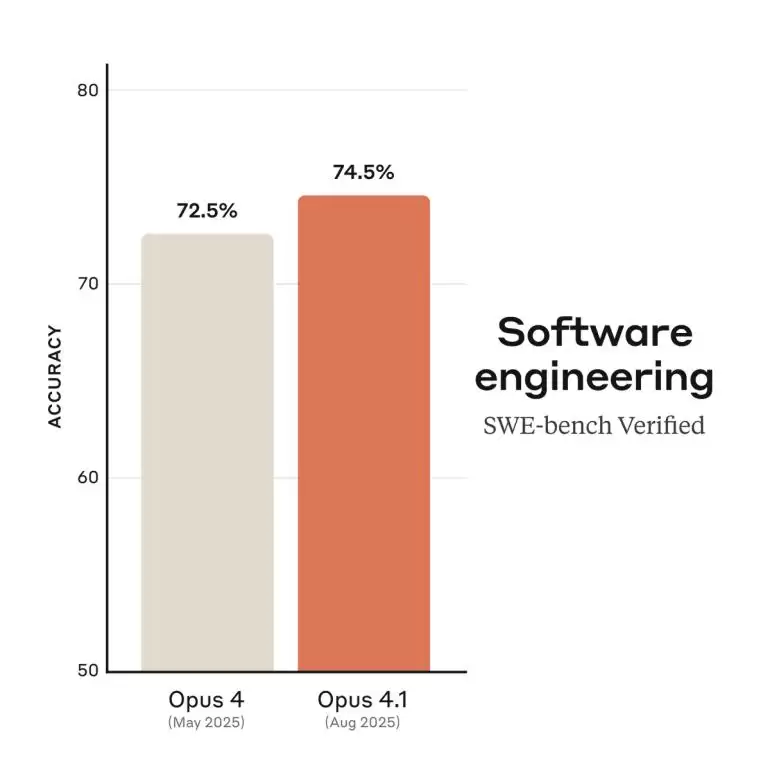
一张图就能很好地概括Anthropic的发布——AI编程能力上限又提高了2%。
但需要强调的是,这里的2%,不仅仅是Claude自己的提升,而是代表了当前AI编程能力的上限。
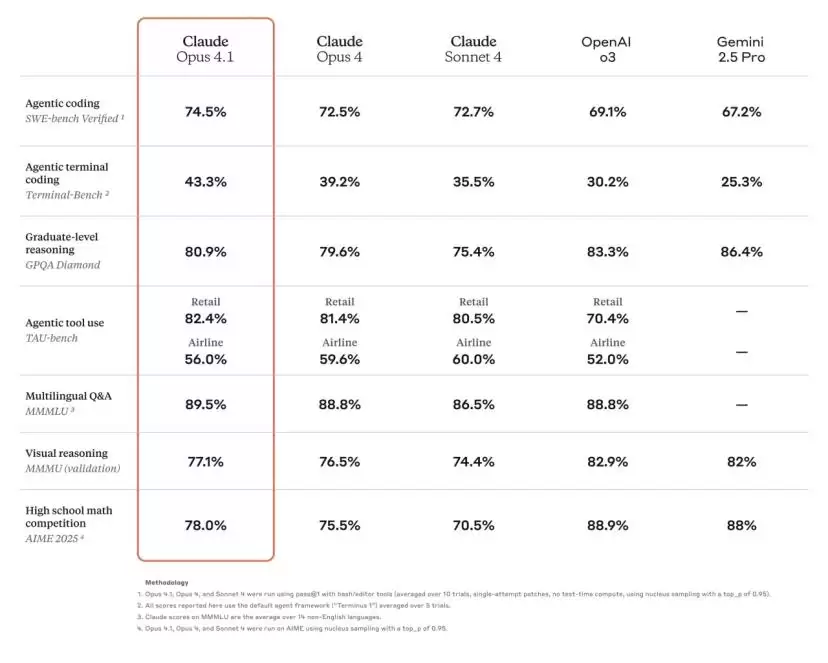
为什么这么说?因为从用户真实反馈和市场占有率来看,Claude Opus几乎就是现在AI Coding领域口碑和占有率最高的模型。
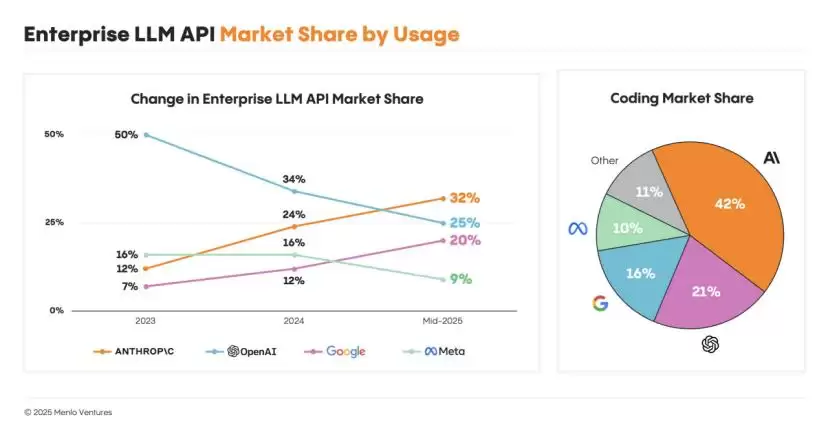
而AI编码,几乎就是现阶段大模型商业化最彻底、未来上限最高的一个分支赛道。所以面对OpenAI的血脉压制,Anthropic选择将所有资源和精力都花在提升自己模型的编程能力上。通过这个竞争策略,让自己能够持续留在大模型商业化的牌桌上,保留同谷歌和OpenAI持续对抗的可能。
从这个角度看,Opus 4.1的发布,就像是在另外两家发布“补课”和“战未来”产品时,向自己的所有客户坚定地说:放心,你们选我错不了。
04 AI圣诞夜背后的国人力量
硅谷AI圈的三弹连发,背后依然少不了华人科学家和工程师的身影。
OpenAI发布的gpt-oss系列模型,其核心团队成员之一,就有参与多个项目的北大校友任泓宇。

在OpenAI期间,他主要负责后训练团队,主要研究方向是语言模型训练优化。
而他现在,也已经被小扎重金挖到了Meta,成为了Meta超(一)级(亿)智(薪)能(酬)实验室的成员。
在去OpenAI之前,他曾在苹果、微软、谷歌、英伟达都工作或实习过。2018年从北大本科毕业后,他在斯坦福大学获得了计算机博士学位。
在社交网络上,他也专门感谢了另一位华人科学家Wang Xin在项目后训练阶段的贡献。
她本科毕业于上海交大,后来在加州大学伯克利分校获得了计算机博士学位。

之后在微软、苹果工作过,于今年2月份加入了OpenAI,主要负责模型的后训练工作。
而在谷歌发布Genie 3的团队名单中,也有1名华人参与。

Emma Wang本科毕业于上海交通大学,在哈佛大学获得博士学位。2019年博士毕业后加入谷歌,主要负责模型的优化。2023年,她加入了DeepMind团队,之后参与了Genie 3服务系统的设计和优化,将延迟降低了10倍,大大提升了模型的吞吐量,从而使模型实现了24fps的流畅度和亚秒级响应延迟。





