在Transformer架构几乎成为大模型代名词的今天,谷歌DeepMind联手KAIST AI和Mila团队,悄悄放出了一个名为Mixture-of-Recursions(MoR)的新架构。先别急着联想到MoE,这可不是专家混合——它是递归混合。效果如何?推理速度直接翻倍,KV缓存内存砍掉一半,而且所有这些提升都在一个统一的框架内完成:同一组参数,既能灵活处理不同任务,又能动态调配计算资源。
说得直白点,这就像给大语言模型装了个双层增效器——性能和效率两手都抓,两手都硬。
不少网友已经在惊呼“Transformer Killer”来了。更有观点认为,MoR或许意味着“潜在空间推理”将成为LLM的下一个突破口。

那么这个MoR到底创新在哪里?我们逐一拆解。
MoR:首次将参数共享与自适应计算统一到一个框架
Transformer虽然带来了惊艳的少样本泛化和推理能力,但训练和部署时那庞大的计算和内存开销,一直是绕不开的难题。业界现有的优化手段,要么走参数共享路线,要么走自适应计算路线,但两者像鱼和熊掌,往往只能选一个。
MoR的出现打破了这种二选一的局面——它在一个递归Transformer里同时融合了这两种效率维度。
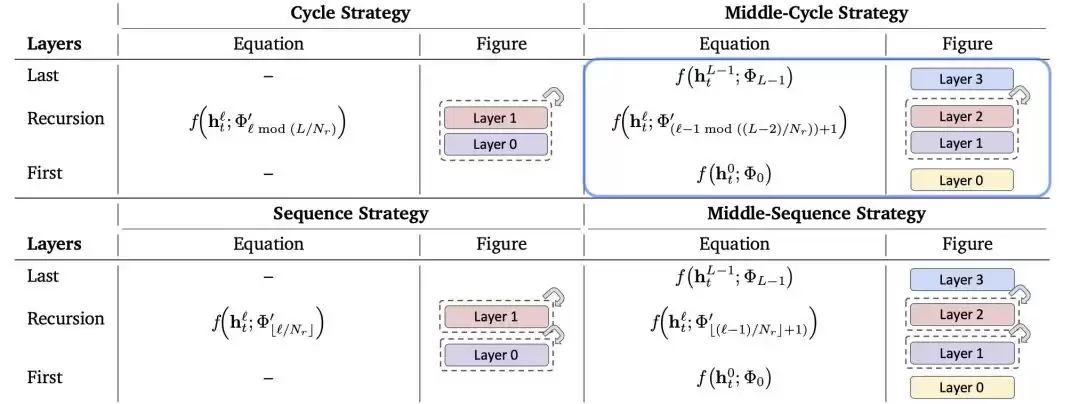
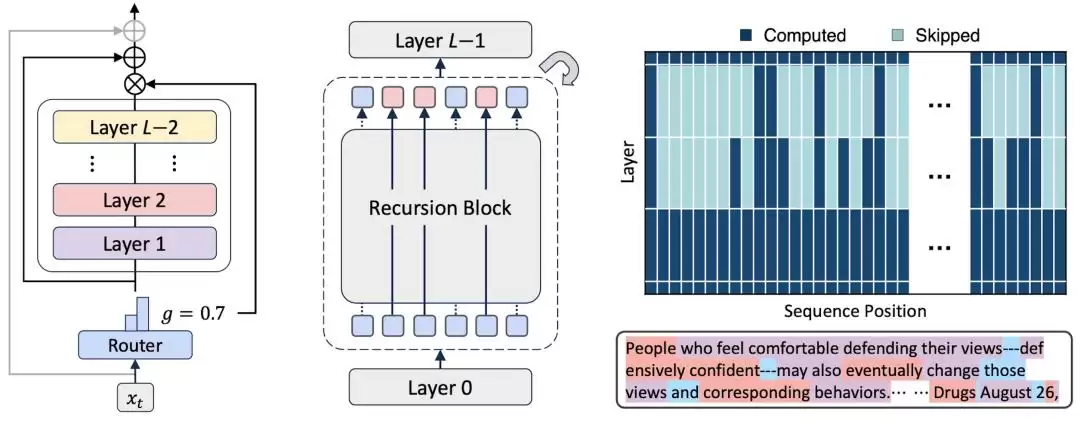
具体来说,MoR首先采用了递归Transformer的设计思路。传统Transformer的每一层都是独立参数,而MoR将模型划分为递归块,复用一组共享参数池。它提供了三种参数共享策略:
- Cycle:循环复用层参数。
- Sequence:连续复用同一层参数。
- Middle变体:保留首尾层为独有参数,只共享中间层。
参数共享的好处很明显:减少独特参数数量,提升分布式训练效率,还能通过连续深度批处理消除计算中的“气泡”,显著提高推理吞吐量。
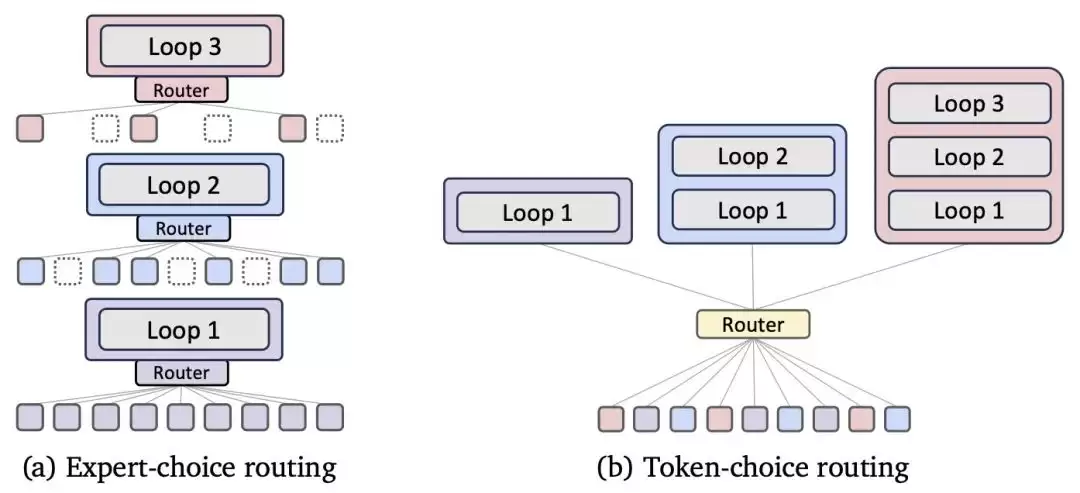
接下来是动态路由机制。MoR通过一个轻量级路由器,为每个token分配不同的递归深度,把计算资源集中投放在复杂token上。路由策略分两种:
- Expert-choice路由:把每个递归步骤看作一个“专家”,基于隐藏状态计算分数,用阈值筛选出需要继续计算的token,层级过滤,复杂度越高的token优先获得更多计算。
- Token-choice路由:初始阶段就为每个token分配好固定递归深度,通过softmax/sigmoid确定专家,token按分配深度依次完成递归。
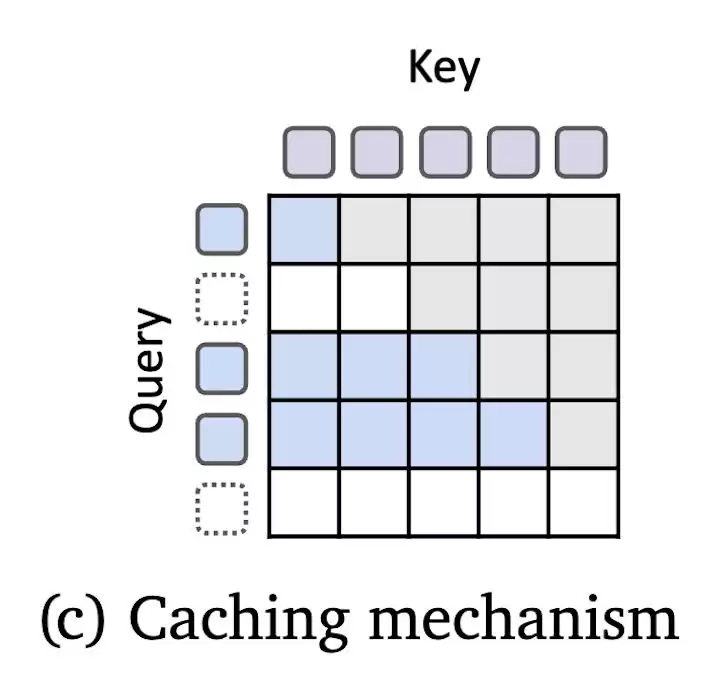
除了参数和路由,MoR还配套了一套KV缓存策略来管理键值的存储与使用,保证内存效率不掉队:
- Recursion-wise缓存:只缓存当前递归步骤中活跃token的KV对,把注意力计算限制在本地缓存里,降低内存和IO需求。
- Recursive KV共享:复用首次递归产生的KV对供后续步骤使用,确保所有token都能访问历史上下文,减少预填充操作。有趣的是,这种共享方式反赌意力的计算量下降幅度很小。
三种策略组合在一起的效果是:MoR在每个token的解码过程中直接进行“潜在思考”,路由机制让模型能自适应推理,突破了以往固定思考深度的限制。参数效率与自适应计算,终于不再是一道单选题。
性能全面超越Transformer
研究团队在135M到1.7B不同参数规模的模型上,对原始Transformer、递归基线模型和MoR进行了对比实验。
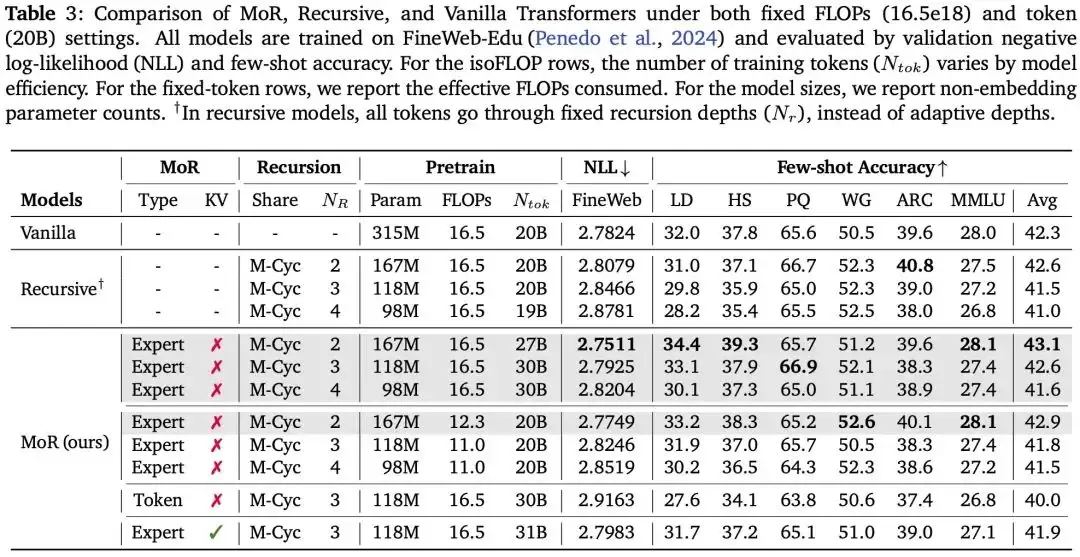
实验结果很说明问题:在相同的16.5e18 FLOPs训练预算下,MoR使用了将近50%更少的参数,却取得了更低的验证损失和更高的平均少样本准确率——43.1%。而普通Transformer模型的少样本准确率是42.3%。这意味着MoR的计算效率更高,同样的FLOPs预算可以处理更多的训练token。
如果固定训练20B token,MoR的训练FLOPs减少了25%,训练时间缩短了19%,峰值内存也降低了25%。
进一步分析路由策略发现,Expert-choice路由的性能在一定程度上优于Token-choice路由——路由的粒度确实会对最终性能产生重要影响。
研究团队还做了IsoFLOP分析,结果显示,在135M、360M、730M和1.7B四个参数规模,以及2e18、5e18、16.5e18三种FLOPs预算下,MoR始终优于递归基线模型。
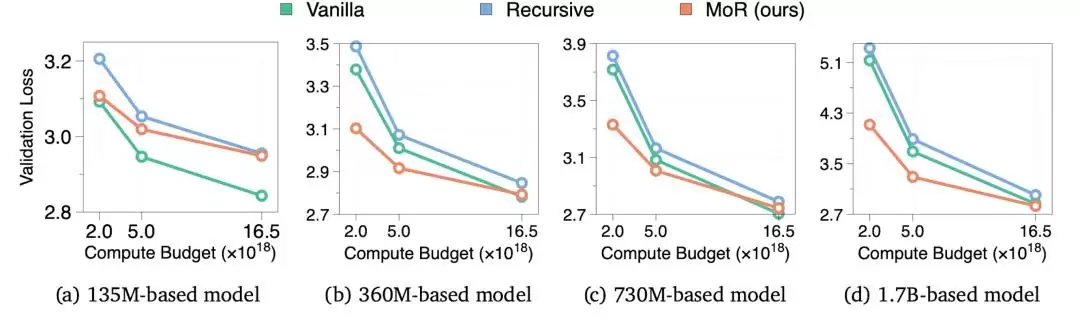
不过值得一提的是,在135M这种极小规模下,MoR因为递归容量瓶颈,表现略逊于普通Transformer。但随着规模扩大到360M及以上,MoR的性能逐步接近甚至超越普通模型,而且参数仅为后者的三分之一——这个可扩展性数据相当扎实。
在推理吞吐量评估中,360M规模的MoR模型,无论是固定批大小还是最大批大小设置,都优于普通Transformer。
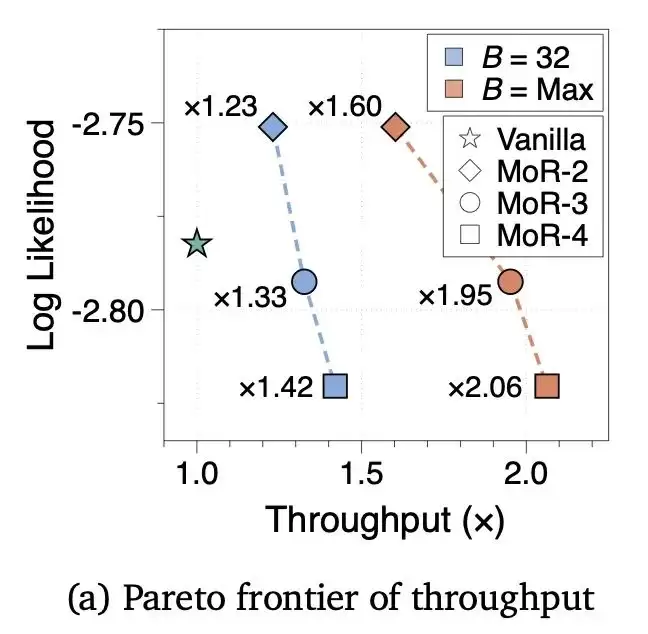
原理也不难理解:递归深度增加后,更多token会提前退出计算,KV缓存占用减少,吞吐量自然就上去了。深度批处理与早期退出的结合,对部署效率的提升非常显著。
谷歌对底层架构的再思考
这已经不是谷歌第一次对底层架构动手术了。其实,谷歌一直在用架构创新来重构计算范式,试图找到AI效率与性能的新平衡点。
最典型的例子就是混合专家模型(MoE)。2017年,谷歌首次把MoE引入LSTM层,通过稀疏门控机制只激活部分专家网络来处理输入,让一个137B参数的模型依然能保持高效训练。

后来的GShard把MoE和Transformer结合起来,实现了动态负载均衡。2021年的Switch Transformer进一步简化了路由机制。而Gemini 1.5 Pro采用的就是分层MoE架构,把专家网络与多模态处理深度绑定,能处理更复杂的多模态任务,训练和服务效率也提升了一大截。

MoE的底层逻辑突破了传统全连接模型的计算瓶颈,如今已成为超大规模模型的首选范式之一。此外还有像TokenTransformer这样的可扩展架构,把模型参数当作可学习的token,通过增量训练无缝扩展模型规模,为未来千亿级模型的低成本迭代铺了路。
所以当MoR出现在眼前时,不少人的反应是:它会不会彻底改变AI世界的规则?能不能真正超越Transformer?

答案或许还要留给时间去验证。但可以肯定的是——谷歌在架构创新的路上,从来没停过。




