正则表达式一般分为两大类型:基本正则表达式(Basic Regular Expression,简称BRE)与扩展正则表达式(Extended Regular Expression,简称ERE)。它们之间最核心的差异在于元字符是否需要通过反斜杠转义才能生效。只要理解这一区别,在实际文本处理中就能游刃有余地切换使用。
一、基本正则表达式的元字符含义
在基本正则表达式中,若要启用元字符的特殊含义,必须在其前面添加反斜杠。具体功能如下:点号.可匹配任意单个字符;方括号[]用于匹配指定集合内的一个字符,而[^]则匹配不在该集合内的字符;星号*代表匹配前一个字符出现任意次数(包括零次);问号\? 表示前一个字符出现0次或1次;加号\+表示出现1次及以上;花括号\{m\}用于精确匹配m次,\{m,n\}则匹配至少m次、至多n次;点号与星号组合.*能够匹配任意长度的任意字符序列;^锚定行首,$锚定行尾;\<(也可写作\b)用于锚定单词开头,\>锚定单词结尾;^$专门匹配空白行;圆括号\(\)通常与\n(n为数字)配合,实现捕获并引用之前匹配的字符串,从而完成重复匹配操作。
二、扩展正则表达式的元字符含义
扩展正则表达式的大部分元字符与基本版本相同,但关键区别在于:问号、加号、花括号和圆括号在扩展模式中无需添加反斜杠即可直接激活特殊含义。具体包含的元字符有:.、[]、[^]、*、?、+、{m}、{m,n}、.*、^、$、\<、\>、^$;此外,圆括号()用于分组捕获,竖线|代表逻辑或,能够匹配其前后任意一个字符序列。
三、可以匹配正则表达式的命令(以grep为例)
grep命令默认采用基本正则表达式来逐行匹配文本,其基本语法格式为:grep [OPTIONS] PATTERN [FILE...]或grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]。常用选项如下:-E切换至扩展正则表达式(功能等同于egrep);-F相当于fgrep;-i忽略大小写;-v显示不匹配的行;-o仅输出匹配到的部分;-q启用静默模式;--color=auto对匹配到的字符进行高亮显示。熟练掌握这些选项,能够大幅提升文本搜索与过滤的效率。
四、实战例子
以下通过几个典型场景展示正则表达式的实际用法(命令均在CentOS环境下测试)。
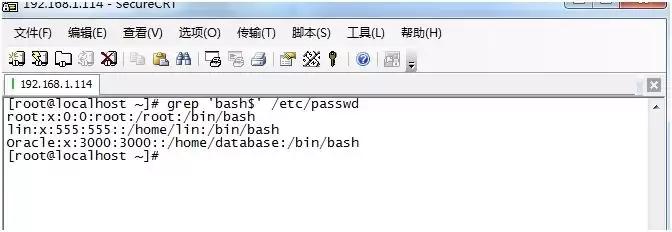
1. 显示/etc/passwd文件中以bash结尾的行:
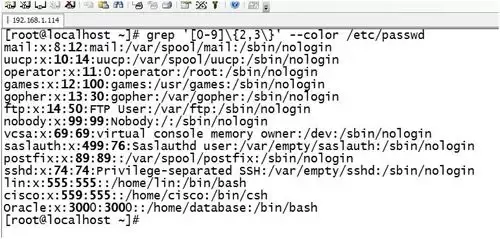
2. 显示/etc/passwd文件中的两位数或三位数:
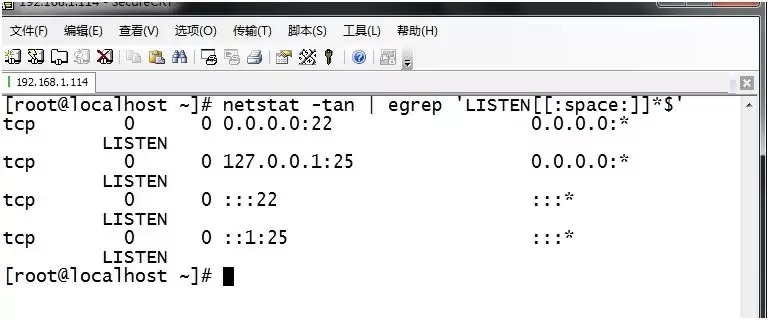
3. 从netstat -tan输出中提取以LISTEN后跟0个、1个或多个空白字符结尾的行:
4. 先添加用户bash、testbash、basher以及nologin用户,然后找出/etc/passwd中用户名与shell名相同的行:
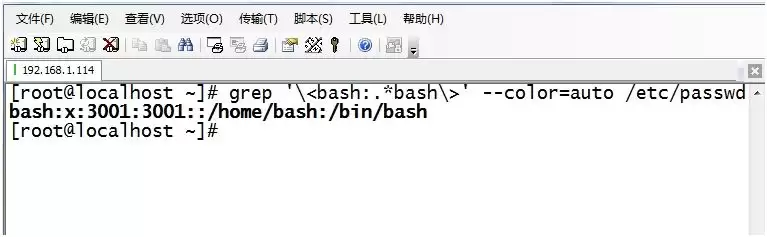
5. 显示当前系统中root、centos或user1用户的默认shell和UID:
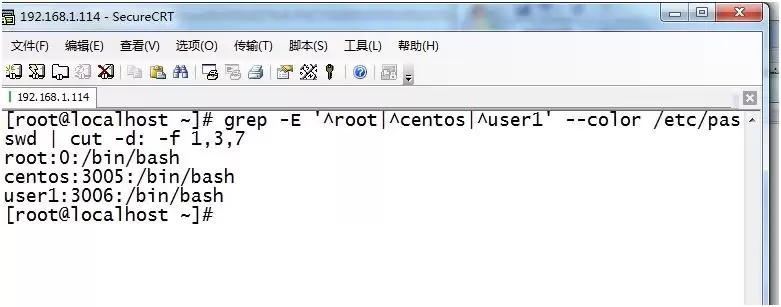
6. 找出/etc/rc.d/init.d/functions文件中某个单词(单词中间可以包含下划线)后面紧跟一组小括号的行:
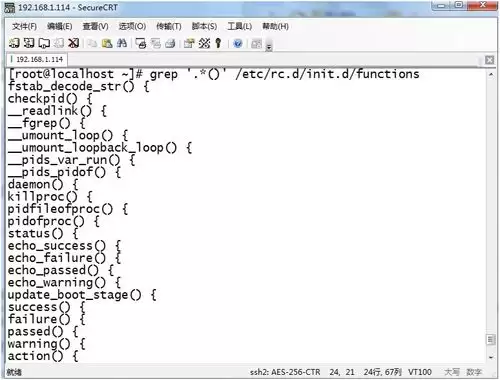
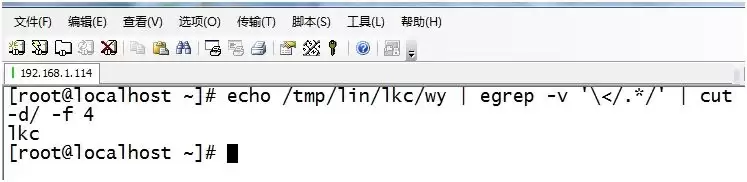
7. 用echo输出一个路径,然后用egrep提取其基名;进一步地,提取目录名:
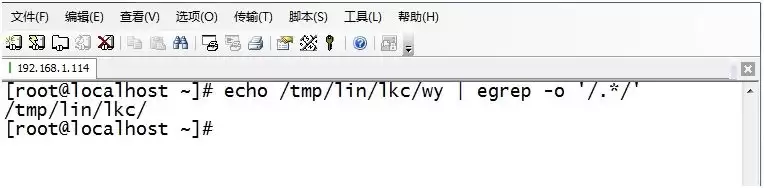
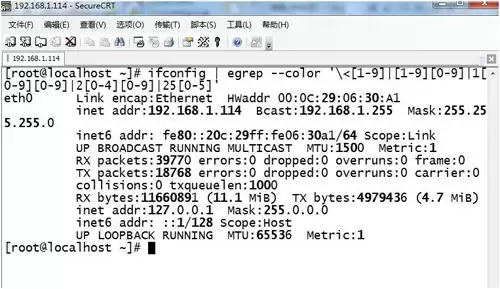
8. 从ifconfig输出中找出1到255之间的数字: