近期,DeepSeek v4 的热度持续攀升,引发了广泛关注。然而,对于大多数用户而言,真正值得聚焦的并非“谁又登顶了榜单”,而是一个更实际的问题:在实际应用中,它能否让你的工作变得更省钱、更稳定、更省心?本文将围绕这一核心,提供理性评估与实操建议。
一、这次升级不止是技术圈的狂欢,普通用户也将深度参与
过去,模型更新换代时,很多人第一反应是“这与我有何关系”?如今,局面已截然不同——撰写文案、制作表格、整理会议纪要、编写代码、处理客服回复,几乎每个日常场景都在被大模型悄然重塑。
DeepSeek 官方文档中有一个至关重要且容易被忽略的信息:它支持与 OpenAI、Anthropic 兼容的 API 格式,并明确了旧模型名称的弃用节奏。
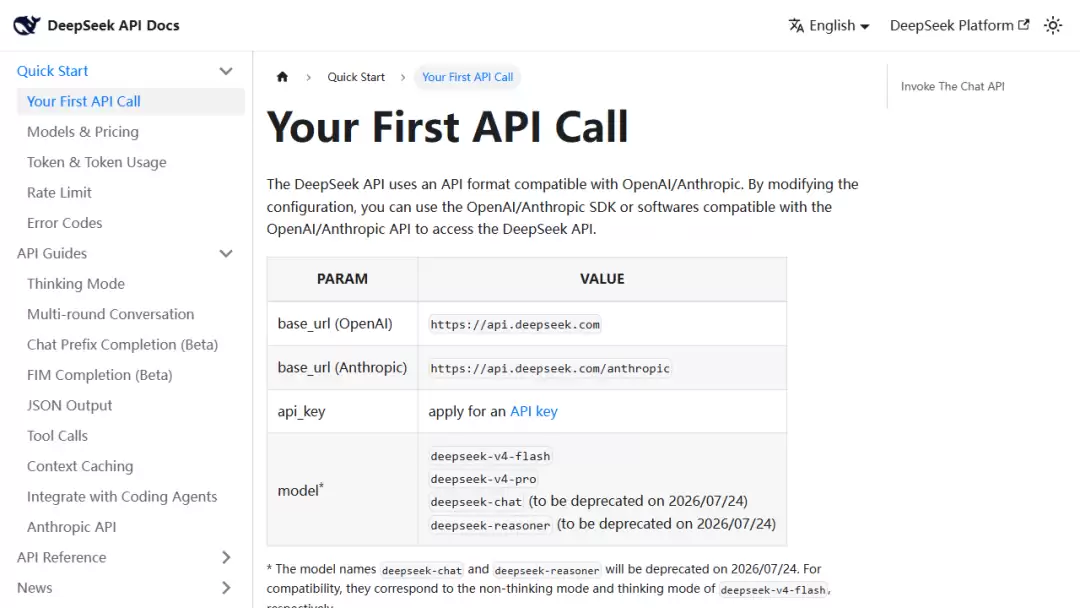
这意味着什么?意味着你不必推翻现有体系,从零开始。许多现有流程可以先行小范围调整、试点运行,再决定是否长期切换。对普通用户来说,这才是最有价值的洞察——并非“它有多先进”,而是“你手头的工作能否因此变得更加顺畅”。
二、别被热度裹挟,先算清三笔关键账
第一笔账:迁移成本账。 如果接入新模型需要大规模修改脚本、更换工具、重构流程,那这不叫升级,而是额外的沉没成本。兼容性越强,迁移成本越低,切换障碍越小。
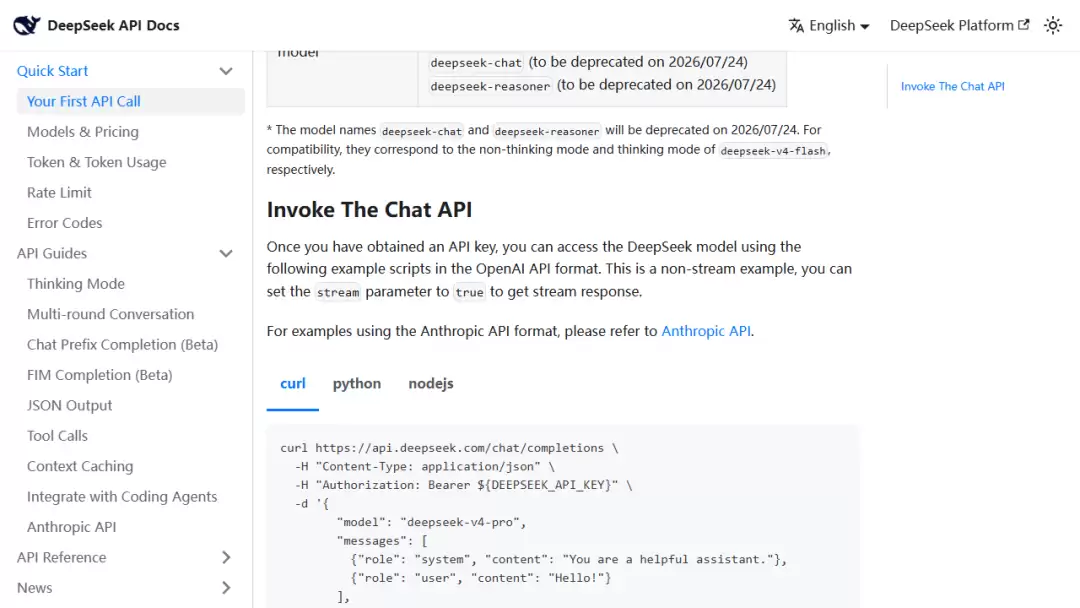
第二笔账:稳定性账。 模型优劣不取决于发布会上的华丽辞藻,而取决于你的真实任务是否会出现“今天正常运行、明天突然报错”的情况。尤其涉及长任务、批量处理、多人协作时,稳定性远比单次峰值表现重要得多。
第三笔账:自主可控账。 最令人担心的是“用上之后就再也离不开”。如果你的调用结构支持替换、回滚、并行测试,那么你就掌握了主动权;反之,即便供应商再强大,你也容易被锁定在单一生态中。
一句话总结:真正拉开差距的不是追逐热点的速度,而是你决策时是否为自己留足了备选方案。
三、给你一套立即可用的 7 天验证法
不想被舆论带偏节奏,最有效的做法就是拿真实任务进行短周期验证。不要用那些精心设计的“演示用例”,而要用你每周都在做的任务:例如撰写周报、整理客服话术、处理文档、修复固定脚本。
7 天的测试周期这样安排即可:
- 第 1-2 天:同一任务双模型对照运行,记录耗时与返工次数
- 第 3-4 天:引入中等复杂度任务,观察稳定性与中断频率
- 第 5-6 天:安排同事按同一流程复现一次,检验“新手上手门槛”
- 第 7 天:只关注三项结果——成本、稳定性、迁移摩擦
如果三项指标全部达标,再考虑扩大使用范围;只要有一项明显未过线,就继续观望并补充监控。这套方法看似“保守”,却能帮你避开最昂贵的一种错误:投入一周后被迫回滚,前功尽弃。
四、最后一句实在话:别急着站队,先把自己的账算清楚
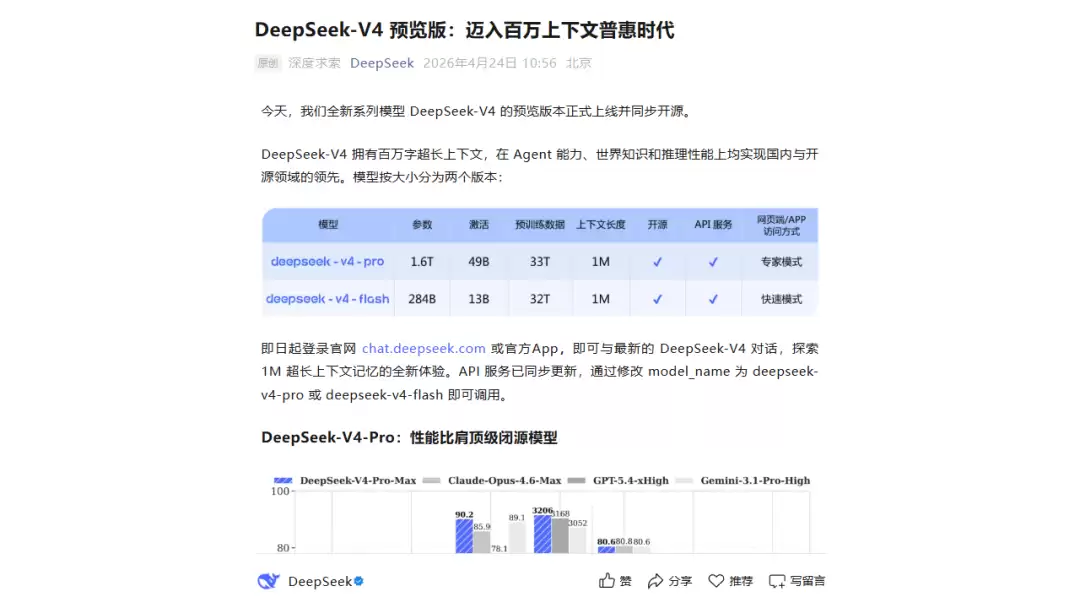
因此,本文最务实的结论只有一个:DeepSeek v4 值得尝试,但不应盲目冲入。先用真实任务跑通一个小闭环,再决定是否全面接入。理性判断,留有余地,才是应对技术迭代的最佳策略。




