转眼间六月即将结束,DeepSeek的新模型依然未见踪影。不过,昨日在官网对话时,一个细节让我颇感意外:刚按下回车键,回答便如流水般顺畅涌现,几乎察觉不到任何延迟。

仔细探查后发现,原来是 DeepSeek 推出了一款名为 DSpark 的框架,它能够将推理生成速度提升 60% 到 85%。这究竟是怎样一项技术突破?
通俗地说,DSpark 是一种“推测性解码”模块。其设计思路相当巧妙:设想你是一位总工程师,每写一行代码都需要亲自审批。而推测性解码的做法是,先让一个实习生快速起草几行代码,你只需扫一眼,正确的就直接通过,错误的再亲自修改。这样一来,审批次数从100次锐减到20次。该框架的核心,是引入一个轻量级的“草稿模型”来快速生成候选 token,然后由大模型进行批量验证。
两大核心创新
投机解码本身并非全新概念,但真正将其大规模部署到生产环境中,DSpark 确实实现了两项前人未能突破的成果。
第一项:半自回归生成架构。
传统的草稿模型通常分为两种:一种是“并行派”,能一次性预测整行文字,速度快,但后续内容容易偏差;另一种是“串行派”,逐字预测,准确率高,但速度较慢。DSpark 的策略是两者兼得:它主体上仍采用并行生成,但在每个小模块(block)内部,让 token 之间先进行互相确认后再输出。这样既保留了并行的速度,又有效降低了错误率。
第二项:置信度调度验证。
原有的投机解码有一个常见问题:草稿生成的 token,无论质量如何,都需要送进大模型验证。但在高并发场景下,GPU算力尤为宝贵。如果大量被大概率拒绝的 token 也排队等待验证,无疑会造成算力浪费。为此,DSpark 引入了一个“置信度头”,让草稿在生成 token 的同时,为每个 token 打分——评估其被采纳的概率。随后,一个实时调度器会监控 GPU 负载情况,动态决定本次需要验证多少个 token。高负载时减少验证,以保障整体吞吐量;低负载时增加验证,以充分发挥单个请求的性能。调度器根据当前硬件状态,为每个请求量身定制最佳方案。
架构运行机制
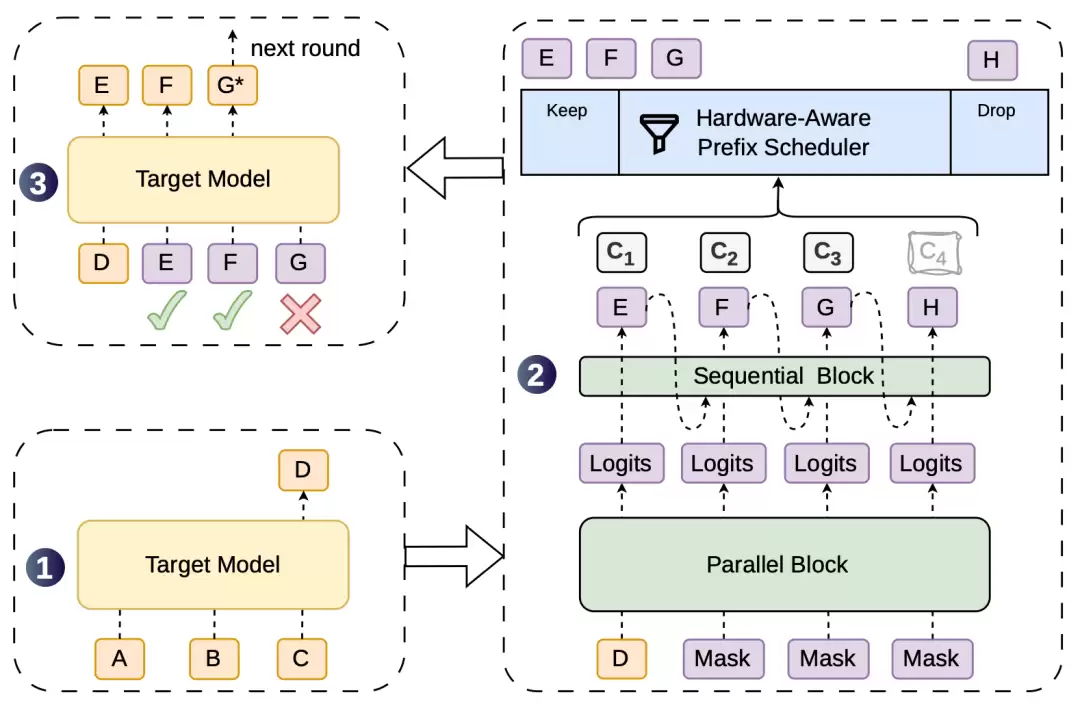
DSpark 架构图
我们来梳理一下它的工作流程:
步骤 1:目标模型首先运行一步,生成第一个 token D,作为草稿阶段的“锚点”。
步骤 2:以 D 为输入,DSpark 启动并行主干网络,一次性生成草稿 token EFGH,同时通过轻量级的串行头计算每个 token 的置信度 c1-c4。
步骤 3:硬件感知的前缀调度器(Hardware-Aware Prefix Scheduler)评估这些置信度,决定哪些保留,哪些舍弃。从图中可以看到,EF 被保留,G 被拒绝,H 被直接丢弃。最后,目标模型并行验证被调度的前缀,E 和 F 顺利通过,G 被拒绝后模型生成修正版 G* 来完成本轮。整个流程循环往复,每轮都有新的 token 被确认。
实际性能数据
相较于前一代的单 Token 基准(MTP-1),在维持总体吞吐量不变的前提下:
• Flash 模型:生成速度提升 60%-85%• Pro 模型:生成速度提升 57%-78%
与其他投机解码方案(在 Qwen3 系列 4B、8B、14B 上的测试)相比:
• 比 Eagle3 提升 26.7%-30.9%• 比 DFlash 提升 16.3%-18.4%
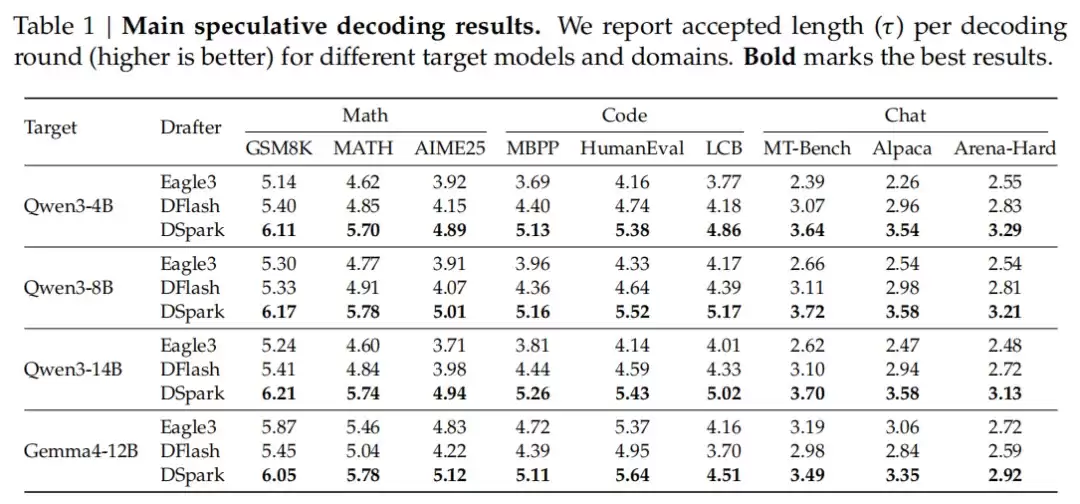
这里有一个关键指标叫“平均接受长度”,它衡量的是草稿模型生成的 token 中有多少被目标模型采纳。接受率越高,无效计算就越少,推理速度自然更快。DSpark 已实际部署在官网,难怪昨天我使用对话时,感觉它几乎无需思考就迅速回应。
为实现这种效果,DSpark 的调度器采用了异步机制,兼容零开销调度(ZOS)和连续 CUDA 图回放。它利用前两步的历史预测来决定当前的动态截断长度,既隐藏了调度延迟,又避免了 GPU 流水线停顿,同时确保了目标模型输出分布的完全无损还原。
在涵盖数学推理、代码生成和日常对话等多个领域的测试中,DSpark 大幅超越了当前最先进的自回归模型(Eagle3)和并行草稿模型(DFlash)。例如,在 Qwen3 系列(4B、8B、14B)目标模型上,其平均接受长度比 Eagle3 提升了 26.7% 到 30.9%,比 DFlash 提升了 16.3% 到 18.4%。
 图片
图片
相较于前一代部署的单 Token 生产基准(MTP-1),在保持相同总体吞吐量的情况下,DSpark 将用户的生成速度分别提升了 60%-85%(Flash 模型)和 57%-78%(Pro 模型)。
 图片
图片
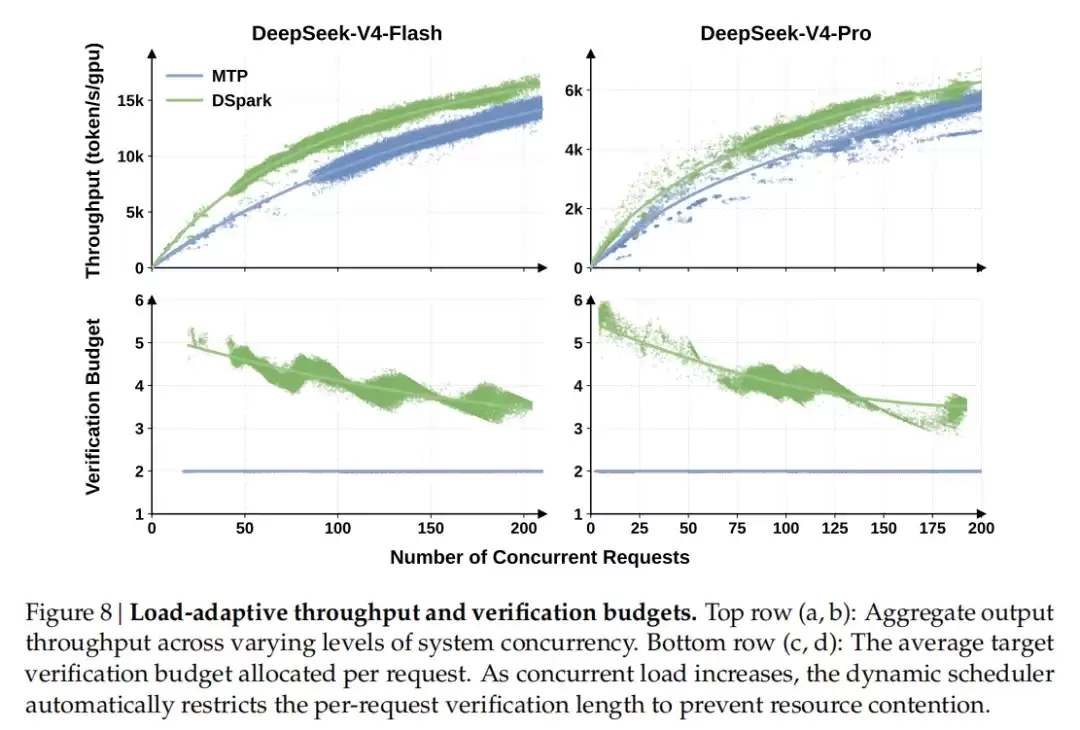
图8 | 负载自适应吞吐量和验证预算。顶行(a,b)展示了不同系统并发水平下的聚合输出吞吐量;底行(c,d)展示了每个请求分配的平均目标验证预算。随着并发负载的增加,动态调度器会自动限制每个请求的验证长度,以防资源竞争。
配套基础设施:DeepSpec
与 DSpark 一同开源的还有 DeepSpec,这是一个用于训练和评估投机解码草稿模型的全栈代码库。它将整体流程划分为三个阶段:数据准备、训练和评估。
数据准备阶段需要下载提示词数据,利用推理引擎对目标模型重新生成答案,并构建好目标缓存。
训练阶段可通过一段简单的 bash 脚本启动,脚本会调用 train.py,并为每张可见 GPU 启动一个工作进程。用户可以通过指定 config_path,在 config/ 目录下选择不同算法和目标模型配置。项目也支持覆盖配置路径和缓存目录,以及使用 --opts 修改单个配置字段。
在硬件方面,DeepSpec 的默认配置面向单节点8卡环境。如果 GPU 数量较少,则需要相应调整可见 GPU 数量。
评估阶段则通过另一个 bash 脚本启动,它会使用训练好的草稿模型,在多个投机解码基准任务上进行测试。目前列出的评估数据集涵盖了数学推理、代码生成、对话能力和综合问答等多种类型。
项目内置了三种草稿模型:DSpark、DFlash 和 Eagle3。支持的目标模型系列包括 Qwen3 和 Gemma。需要注意的是,以 Qwen3-4B 配置为例,目标缓存大小约为38TB,开始运行前需要先评估存储资源是否充足。
DeepSpec 的价值在于,它将此前分散在各团队内部的工程经验汇聚成了一套标准化工具链。对于希望加快模型推理速度的团队而言,这意味着可以直接在成熟框架上训练定制草稿模型,省去大量重复的基础设施搭建工作。
总结
观察近期各家大模型的更新路径,可以发现一个有趣的分化:DeepSeek 似乎专注于大模型技术底层的深度优化,而其他厂商更多地向应用层面发力,比如通过后训练让 Agent 能执行更多现实世界的任务。像阿里的语言世界模型、智谱让大模型持续长时间运行以完成复杂任务,都是这一方向的典型代表。
这种局面其实很有意思。国内各家在不同方向上投入资源,并且都保持开源。这样一来,每个模型团队在训练时都能汲取各家之长,任何一方的技术突破都会迅速成为整个行业的“公共养分”。大家默契地共同推进一场分布式攻坚战,合力追赶国际前沿水平。
你也在等待 DeepSeek 的新模型发布吗?欢迎在评论区交流讨论。
参考资料
技术报告:《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》
GitHub:https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf




