先说几个核心判断。AMD与英伟达围绕数据中心市场的这场“牌局”,已迈入全新阶段——不再局限于单纯的产品发布,而是提前通过性能预估与基准测试互相“放话”,为接下来的服务器芯片更替周期制造声势。
还记得英伟达此前发布的Vera服务器处理器吗?当时英伟达通过一套由其严格把控的基准测试宣称,Vera在多项负载中领先于AMD现有的Epyc产品。如今,AMD的反击来了。根据最新披露的内部测算数据,AMD认为,其下一代Epyc“Venice”平台在机架级性能上,有望实现对Vera的“大幅超越”。

AMD这份新发布的性能预估文档,直接点名了英伟达的Vera方案。其策略非常清晰:既然英伟达之前用数据说话,那就在相同的假设条件和测试框架下,摆出Epyc Venice的相对优势。换言之,这不是空对空的对比,而是精准的“对位比划”。
先来看看Venice这款产品本身。作为AMD下一代数据中心的CPU平台,Venice目前已进入量产阶段,预计今年晚些时候正式亮相。基于全新的Zen 6架构,Venice单颗处理器最多可提供256个核心和512个线程。更关键的是制造工艺上的跨越:从现有Epyc Turin的台积电4nm,直接跃迁到2nm节点,中间跳过了3nm。按照AMD自己的预期,相比Turin,Venice在整体性能和能效上可带来约70%的提升,同时线程密度增长约30%。
在与英伟达平台的对比中,AMD选择了一个非常巧妙的切入点。它引用了此前在英伟达总部完成的那批Vera基准测试数据——这批测试经过英伟达审批,对环境和配置有严格控制。Phoronix在报道中将Vera称为“目前测试过的最强Arm处理器”,它在多数工作负载下的确优于Intel Xeon和现有AMD Epyc。但AMD接下来要做的是,在这个基础上,用一套“统一假设”来做机架级推算。
推算模型考虑了单CPU核心数、节点功耗、每机架可部署节点数以及100千瓦的机架功率预算。在这个模型下,AMD得出的结论是:Epyc Venice的每机架性能可达Vera的3.3倍。作为参照,现有的192核Epyc 9965 Turin和128核Intel Xeon 6980P GNR-AP,在相同条件下分别被推算为Vera的约2.37倍和1.46倍。Venice这个“3.3倍”的数字,显然是有备而来。
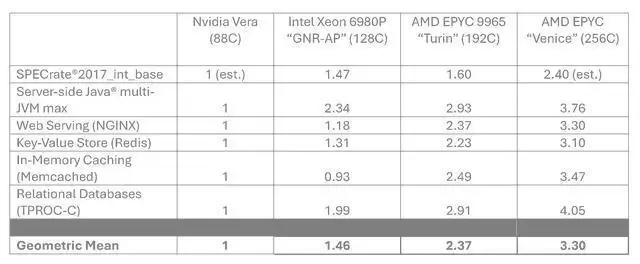
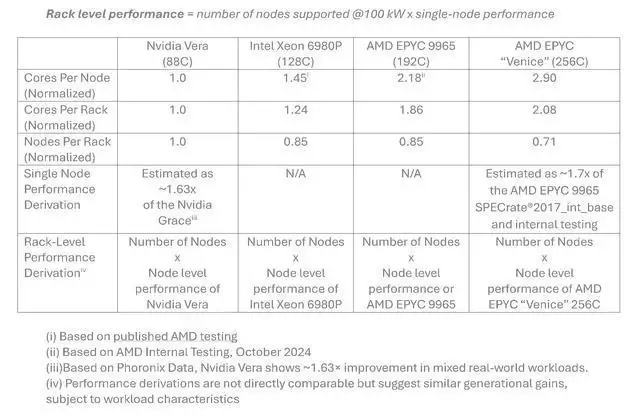
除了机架级吞吐量这个“大数”,AMD还把矛头对准了每核心性能。按照同样的基准体系,AMD声称,其64核版本的Venice在每核心性能上就已经领先Vera约27%,即便用96核版本,也能保持约11%的优势。考虑到两家产品都面向AI工作负载,AMD的算盘打得很清楚:每核心性能和核心数量同时拉升,意味着在同样的机架功耗约束下,Venice能提供更高的算力密度,这对于“智能体式”AI部署场景来说,无疑是一个极具吸引力的选项。
当然,必须补充一句:所有这些都是厂商层面的理论预估。在独立测试机构拿到量产芯片并完成公开对比之前,这些差距都还停留在纸面上。
不过,在为Venice预热的同时,AMD已经开始为更远的未来“埋伏笔”。按照其路线图,“Verano”将是AMD第一款专为AI基础设施设计的CPU产品,而且会率先采用Zen 7架构。供应链消息显示,Zen 7有望导入台积电A14工艺节点——大约1.4nm级别。这被视为AMD迈入“埃米级时代”的关键一步,理论上可在2nm基础上继续带来性能和能效的进一步提升。当然,AMD目前还没有对这些细节给出最新官方确认,但方向已经相当明确了。




