苹果在2026年WWDC大会上正式发布了CoreAI引擎,全面接替已服役长达9年的CoreML框架。此前,CoreML自2017年起主要承担iOS和macOS平台上图像分类等小型静态任务,而全新登场的CoreAI则将战略重点全面转向端侧大模型推理——在设备本地运行大型语言模型,支持更灵活的模型格式并允许更大的内存占用,这无疑是其真正的核心使命。
与此同时,MLX作为苹果生态中的另一套机器学习框架,聚焦于研究、训练和模型微调,开发者经常借助它来测试和部署本地大模型。换句话说,CoreAI与MLX虽同属苹果体系,但分工非常清晰:一个主攻端侧推理,另一个偏向研究与训练场景。
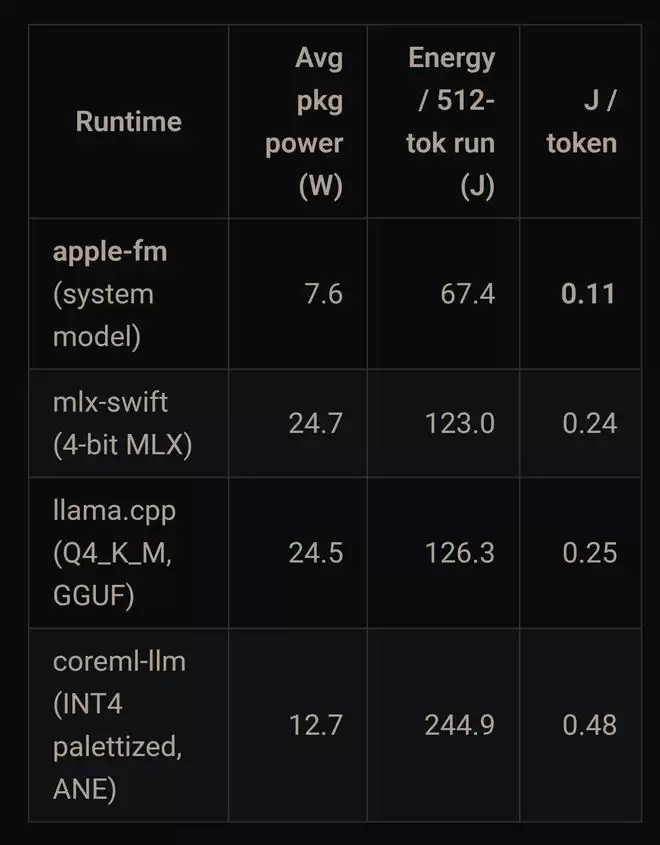
从首批基准测试结果来看,CoreAI呈现出“小模型性能突出、大模型表现持平”的鲜明特征。在M4 Mac上运行Qwen3 0.6B模型时,CoreAI的解码速度大约是MLX的2.47倍;而在iPhone 17 Pro上,这一优势缩小至约1.6倍。所谓解码速度,即大模型每秒能够生成多少个token(tok/s),该数值越高,用户等待回复的时间就越短。
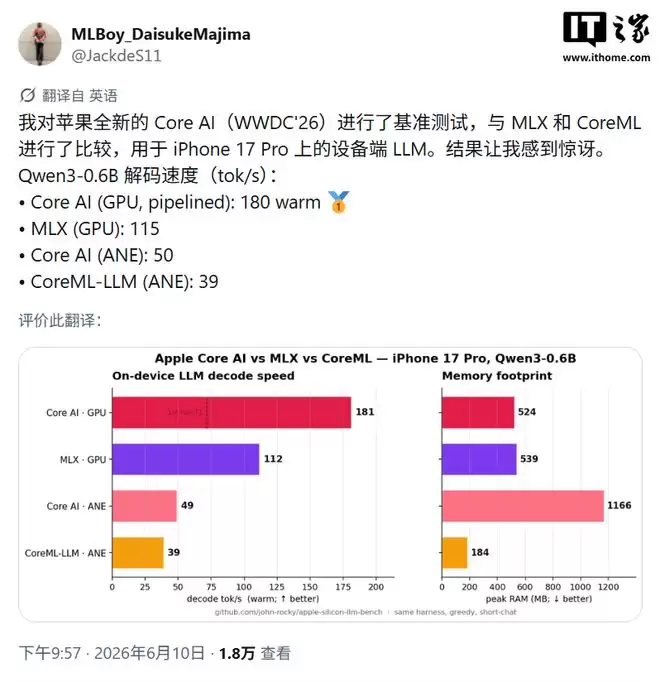
当模型规模提升至80亿参数(Qwen3 8B,M4 Max)后,CoreAI仅比MLX快了约5%,两者基本处于同一水平。这说明随着模型体量增大,CoreAI的性能优势明显收窄——在小模型上可以拉开倍速差距,而大模型上则趋于持平状态。
在持续负载能力方面的测试更具参考价值。数据显示,iPhone 17 Pro的GPU在长时间运行大模型后会较快触发温控降频,从而削弱基于GPU路线的持续吞吐能力。反倒是CoreML与苹果神经引擎(ANE)的组合,在性能保持率上实现了反超。这表明纯GPU路线并非最优方案,融合神经引擎的混合架构在长时间推理场景下更为稳定可靠。
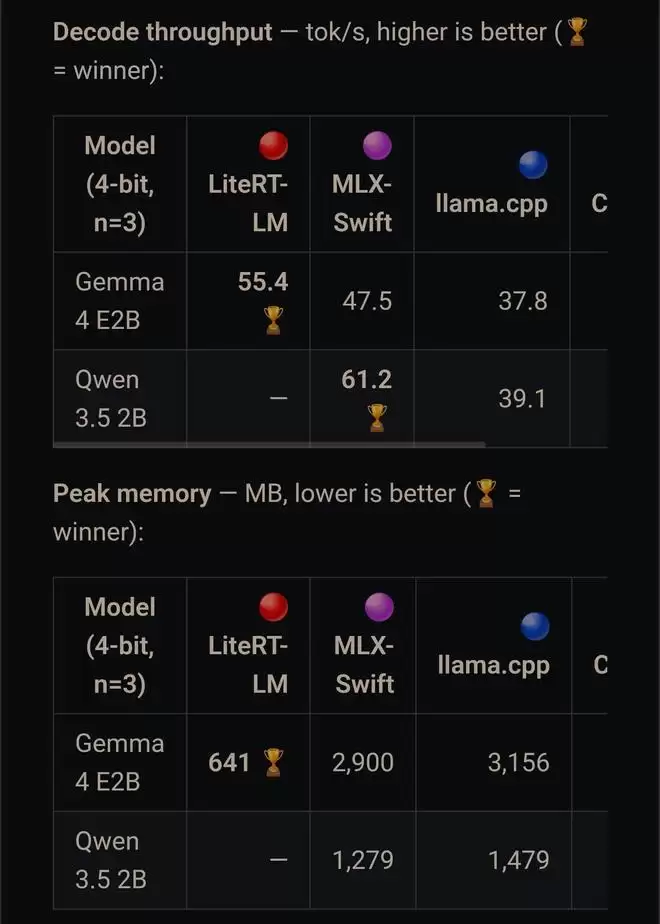
再横向对比其他厂商的方案,你会发现针对特定模型深度优化的引擎更容易胜出。谷歌的LiteRT-LM在iPhone 17 Pro上运行Gemma时,每秒可达55.4个token,而RAM占用仅641 MB。作为对照,苹果MLX运行相同模型的内存占用高达2900 MB,是前者的4.5倍。这组数据很直观地说明:内存效率与推理速度之间的平衡,往往成为端侧AI落地的关键瓶颈。