通义实验室最新发布的Qwen3-TTS语音合成系统,在音色复刻、个性化定制以及拟真语音生成等方面展现了诸多创新亮点。尤为突出的是,该系统支持通过自然语言指令对语音进行精细化调控——用户无需再面对复杂的参数设置界面,只需说出“我想要更活泼一点、语速快一些”等自然语句即可生效,极大降低了开发者和普通用户的使用门槛。
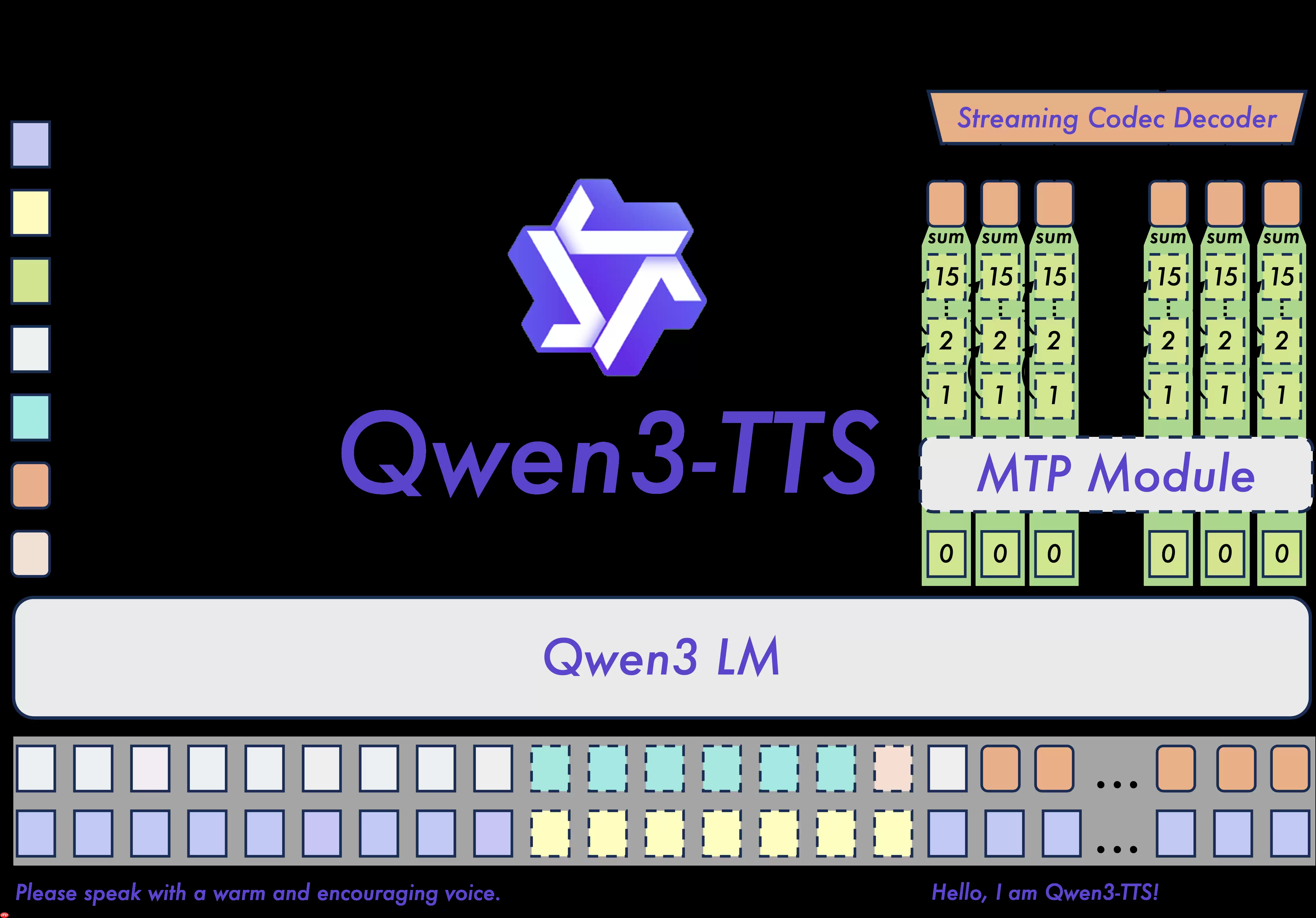
在技术实现上,核心引擎采用自研的Qwen3-TTS-Tokenizer-12Hz多码本语音编码器,能够对原始语音进行高保真压缩,同时完整保留语气、停顿、呼吸等副语言细节,甚至连录音环境的微妙声学特征也得以保存。更关键的是,它并未采用当前流行的“LM+DiT”级联架构,而是选择了轻量级的非DiT解码方案,效率更高且更直接。在此基础上引入的Dual-Track双轨流式建模机制,实现了真正的低延迟生成——首个字符输入时,首帧音频即可输出。
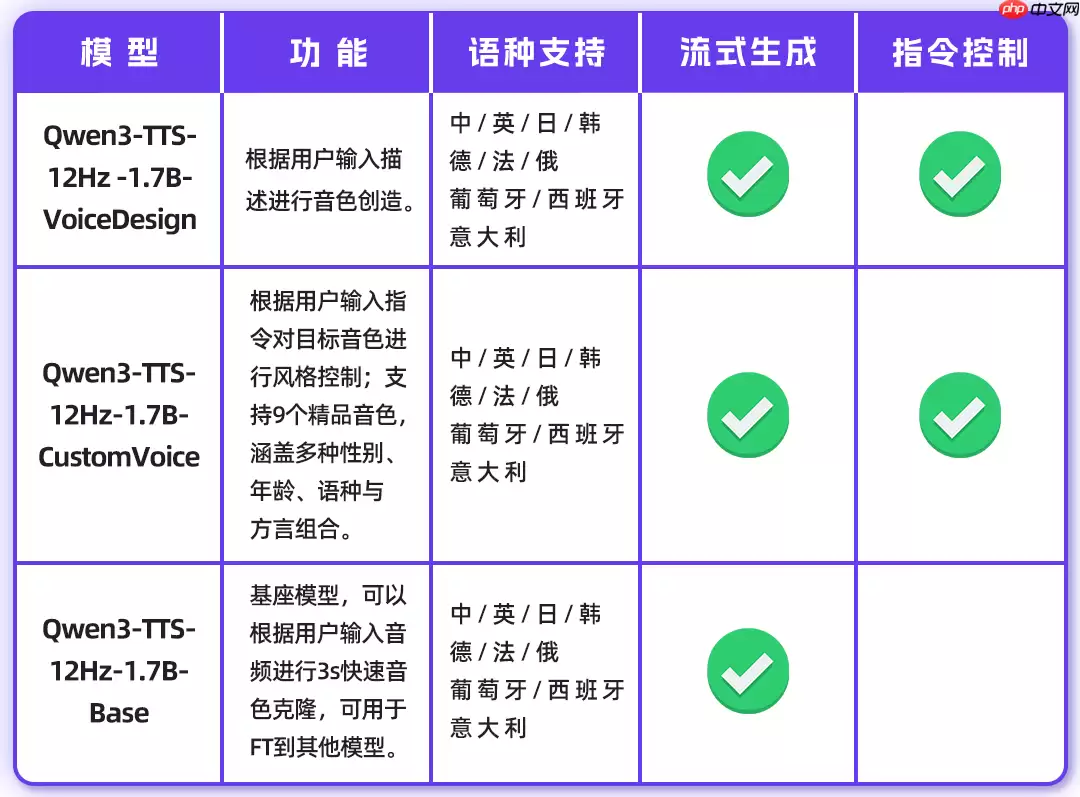
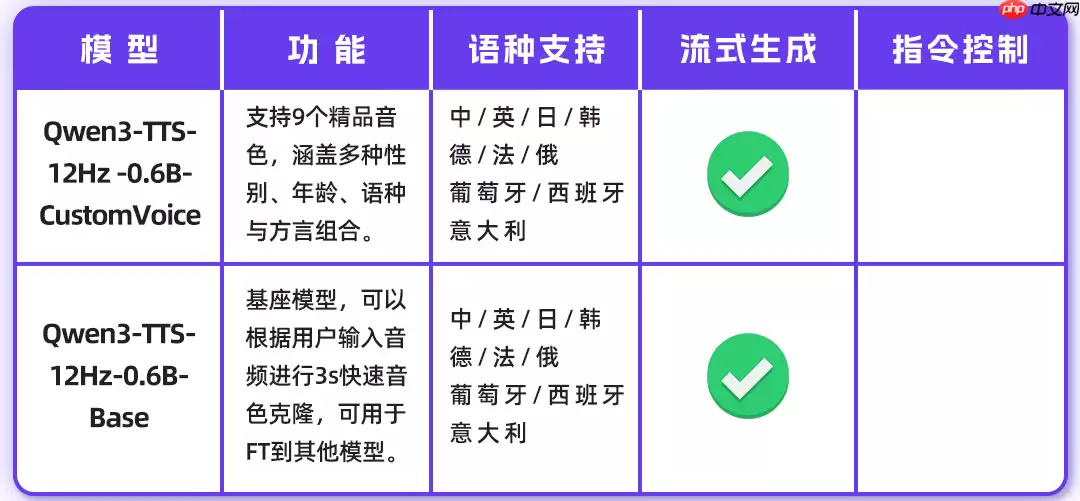
目前Qwen3-TTS模型系列已全面开源,提供1.7B和0.6B两个参数规模版本。1.7B版本专注实现极致的控制力与生成质量,0.6B版本则在效率与效果之间取得了出色平衡。原生支持10种主流语言,并覆盖多种地域性方言音色——涵盖中文、英语、日语、韩语、德语、法语、俄语、葡萄牙语、西班牙语、意大利语,基本满足全球化应用场景需求。
值得注意的是,该模型具备强大的上下文感知能力,能够根据文本语义和用户指令动态调整语调、节奏和情绪表达。即使输入文本存在错别字、标点缺失或口语化表达,模型依然能保持稳定的合成效果,鲁棒性表现十分出色。
模型规格一览
1.7B 模型
0.6B 模型
核心优势
- 高保真语音表征能力:自研编码器同时优化了声学压缩与高维语义建模,副语言线索和环境声学特征均被完整保留。搭配非DiT轻量解码架构,实时性与还原度均达到较高水准。
- 端到端统一建模范式:基于离散多码本语言模型架构,直接建模语音全维度特征,彻底避免传统级联范式带来的性能瓶颈与误差累积问题,泛化能力、生成速度及表现上限均实现质的飞跃。
- 毫秒级流式响应:Dual-Track混合框架使单一模型同时支持流式与非流式模式,首个字符输入即可输出首段音频,端到端延迟低至97毫秒——适用于实时对话、虚拟助手等强交互场景,体验流畅。
- 语义驱动的智能调控:通过自然语言描述即可控制音色、情感、语速、韵律。文本理解模块自动匹配语气起伏与情绪张力,最终输出效果实现“所思即所闻”。
综合性能评测
在音色克隆、音色创造、可控语音生成等关键任务上,Qwen3-TTS表现抢眼,多项指标刷新了开源与闭源模型的纪录:
- 音色创造任务中,指令遵循准确率与语音表现力均超越MiniMax-Voice-Design闭源方案,显著领先其他开源竞品;
- 音色控制方面,平均词错率仅2.34%,跨语言泛化能力出色,风格一致性控制得分达到75.4分(InstructTTS-Eval)。在超长文本合成场景下,连续生成10分钟语音,中英文词错率分别稳定在2.36%和2.81%;
- 音色克隆任务中,中英文语音稳定性全面优于MiniMax和SeedTTS。在10类语种评估中,平均词错率1.835%,说话人相似度0.789,双优成绩超越MiniMax和ElevenLabs。跨语种音色迁移能力与CosyVoice3相当,达到当前SOTA水平。


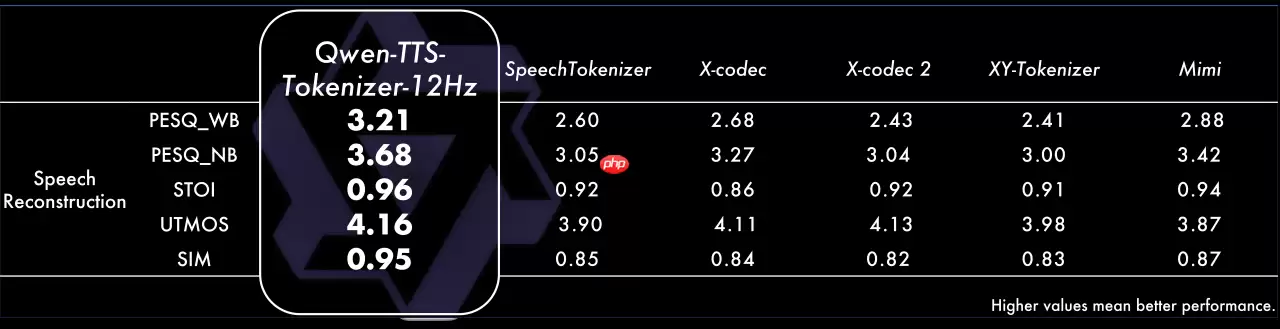
Tokenizer 重构性能
在LibriSpeech test-clean数据集上的语音重建质量评估进一步验证了编码器的实力:
- 感知语音质量(PESQ)宽带得分3.21,窄带得分3.68;
- 短时客观可懂度(STOI)达到0.96,UTMOS主观质量评分4.16;
- 说话人相似度指标获得0.95分——近乎无损地保留了原始说话人的身份特征,对比效果显著。
总体而言,Qwen3-TTS在语音合成的核心环节实现了实质性进步:编码更高效、架构更直接、控制更灵活、表现更稳定。对于正在寻求高质量语音合成方案的团队而言,这套开源模型的推出,无疑提供了一个极具研究价值的选择。




