大家好,我是人月聊IT。本期我们继续深入探讨本体论实践方面的核心内容。
先厘清:传统知识图谱实践与本体论实践的本质差异
首先,我们再来梳理一下传统知识图谱实践与本体论实践之间的关键区别。
传统知识图谱实践主要聚焦于 ABox 对象实例层,需要为每个对象实例构建三元组关系。而本体建模则从 TBox 抽象模型层出发——尽管 OWL 等建模语义同样支持录入实例个体,但这并非其核心目标。本体建模的真正意图,是通过抽象层的建模内容,实现向实例关系层的有效泛化。
需要特别注意的是,OWL2 规范引入了属性链(Property Chain)机制,进一步简化了从抽象层向个体实例层的泛化过程。换言之,本体论实践的核心要素——对象、属性、关系、逻辑——全部定义在 TBox 抽象模型层,而非在 ABox 实例层强行构建。这正是其与传统知识图谱最根本的区别所在。
OWL、SWRL 与 SHACL:被割裂的三位一体
传统的 OWL 建模主要用于定义对象、关系和属性。在规则建模方面,OWL 仅能直接表达少量参照完整性约束,更复杂的规则则需要交由 SWRL 和 SHACL 来处理。简要概括:
SWRL 负责定义能够推导新事实的推理规则;SHACL 则用于定义数据完整性约束与校验规则。
即便是斯坦福大学开发的 Protégé 编辑器,也主要聚焦于静态本体定义,对 SHACL 的支持极为有限。因此,一个完整的本体工程实际上需要 OWL、SWRL、SHACL 三者协同配合才能构建完成。
此处先埋一个伏笔,后续会用到:OWL 基于开放世界假设(OWA),而 SHACL 校验则遵循封闭世界假设(CWA)。这意味着,同一套形式化技术栈中并存着两种相互矛盾的世界观。传统本体栈呈现"割裂"状态——静态对象关系由 OWL 管理,推理规则归 SWRL 负责,校验规则由 SHACL 承担,甚至连底层的逻辑前提都无法统一。这种割裂并非工具层面的问题,而是范式本身存在的结构性缺陷。
Palantir 本体:静态本体与动态本体的有机融合
Palantir 本体建模最关键的突破,在于将静态的对象-关系-属性本体与动态的行为规则进行了深度融合。从这一视角来看,Palantir 的建模思路更接近于面向对象的分析建模(OOA)。
观察其模型结构便一目了然:Action 类似于用例建模,Function 对应动态复杂规则建模,但所有这些元素都围绕 Object 对象紧密整合。这恰恰击中了纯 OWL/RDF 体系的核心痛点——一个典型的"贫血模型":数据与关系停留在 TBox 层,行为却被放逐到 SWRL/SHACL 乃至外部代码中。而 Palantir 将行为重新绑定到对象之上,这本质上正是面向对象分析的基本常识。
先完整走一遍传统范式流程
当前本体实践中,一种典型思路是:基于具体场景问题进行需求分析,借助 AI 大模型辅助生成 OWL、SWRL、SHACL 各自的标准语义定义文件,然后驱动场景化推理。这是一套经典的传统模型,我们先将其关键环节完整展开,后续再讨论其局限性。
最基础的模型加载与推理流程如下:首先加载 TBox 抽象本体模型(包括 OWL 类、属性、关系);接着基于场景问题筛选数据,加载 ABox(RDF 三元组);然后加载规则(OWL + SWRL + SHACL);最后执行推理。
此外,ABox 实例数据的加载可以依托图数据库来实现。目前主要有两类图数据库:
一类是基于原生 RDF 三元组的图数据库,例如 GraphDB。这类数据库与 OWL/RDF 体系最为契合,内置了推理引擎,支持前向链接和后向链接两种推理模式。
另一类是以 Neo4j 为代表的属性图数据库。属性图本身不直接支持原生的 OWL/SWRL 推理,需要借助中间件进行转换——在此模式下,OWL RDF 先转化为图模型导入 Neo4j,后续推理主要基于图遍历来完成。
不过有一个工程细节值得注意:如果先将实例数据写入 RDF 文件再动态装载,I/O 与性能开销会非常大。因此,当前更通用的做法是:在内存中直接使用 RDF 模型初始化一个内存对象,然后动态装载数据;同时将系统预置的 OWL/SWRL/SHACL 定义文件加载到该内存模型中。此时内存中同时具备了模型层与实例层,两者绑定后,无论是执行 SPARQL 查询还是运行 SHACL 校验,都不会有问题。
必须强调的是:上述基于传统本体论与知识图谱的流程本身是成熟且可靠的,没有任何问题。但接下来我们要质疑的不是它能否运行,而是在 AI 大模型时代,它是否还应该继续扮演核心角色。
AI 大模型在此究竟扮演什么角色?
回到本文最核心的观点。
上述流程虽然能够跑通,但 AI 大模型在其中究竟发挥了什么作用?如果仅仅停留在上述思路,那么 AI 大模型实际上只是辅助完成了本体建模工作,或者通过 AI 编程方式生成了本体应用的基础框架。
AI 大模型的能力远不止"帮你写几个定义文件"这么简单。如果只局限于此,实际上是我们自己束缚了大模型的潜力。
传统本体标准是否适用于 AI?
这里需要先把一件事厘清,否则容易产生误解。
并非大模型无法理解 OWL/SHACL——恰恰相反,Turtle、OWL、SHACL 等语义在训练语料中大量存在,大模型理解它们毫无障碍。真正的问题在于推理范式的不匹配:传统形式化本体遵循描述逻辑(DL)的路径——单调蕴含、封闭规则集、确定性推导;而大模型则采用概率化、语境化、Plan 式的推理方式。将一套为 DL 推理机设计的输入,硬塞给一个概率推理引擎,这便是我们常说的"阻抗失配"。
因此,这里需要区分两个角色:OWL/RDF 作为供大模型理解的知识载体是合格的;但若将其作为 DL 推理机的唯一输入并依赖推理机给出结论,在大模型时代就显得格格不入了。再加上前文提到的 OWA 与 CWA 并存、静态与动态割裂等问题——这套体系本身的内在矛盾,使其难以成为一条理想的、面向 AI 的本体技术路径。
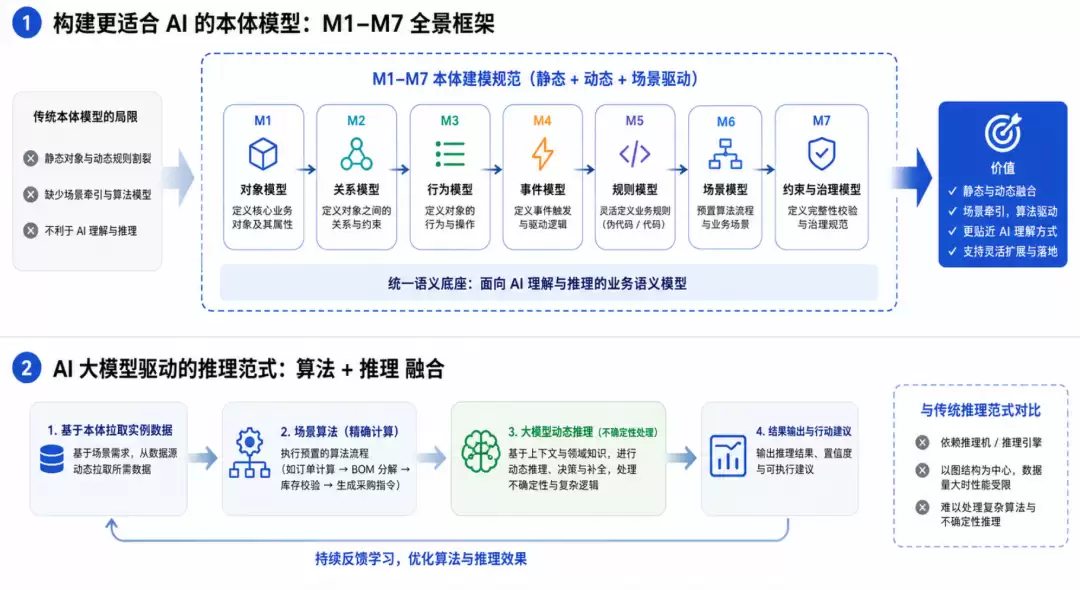
还有一个更为关键的缺失:这种本体定义中缺少了场景模型。场景模型可以理解为算法模型,是预先设定好的一组行为规则组合。本体建模本应服务于场景问题,缺少场景模型,整个本体就失去了关键的驱动力——只剩下声明式的、与场景无关的静态知识,缺失了"目的性"和"过程性"的维度。
这也是此前提出 M1 到 M7 本体建模规范的根本原因。该规范不仅覆盖了静态本体,还通过行为规则与事件涵盖了动态内容,并引入了场景驱动的牵引机制,三者共同构成了一个完整的整体。
用伪代码或代码定义规则:灵活性与代价并存
对于规则模型,完全可以使用伪代码进行灵活定义——传统本体中 OWL 的约束、SWRL 的推理、SHACL 的校验,都可以融入规则模型,并且能够更好地与对象行为绑定。以 Palantir 的 Function 为例,其定义极为灵活,可以直接使用 Python 或 TypeScript 代码来表达规则。这种灵活性与开放性,是一项不可或缺的能力。
但这里需要坦诚地说明代价,不能只谈优势。SWRL/SHACL 之所以"受限",恰恰是因为它们具备可判定性和可分析性——你可以对规则集进行一致性检查,自动发现相互矛盾的规则,并给出可证明的推导链。一旦规则变为图灵完备的代码,这些能力将不复存在:规则之间是否冲突将无法自动验证;推导过程也不再具备可证明性。
这是一个真实的权衡——表达力与可分析性之间的取舍。在大模型时代,选择表达力,我们认为这个方向是正确的;但必须承认,这是以牺牲"可分析性"为代价换来的,并非没有成本。正视这一点,反而让这个选择更加站得住脚。
传统 DL、SPARQL 与图推理引擎:是否足够强大?
前文已经强调,AI 大模型时代需要一套更适合 AI 理解的本体建模规范。接下来要讨论第二件事:在 AI 大模型框架下,应充分利用大模型自身的推理能力。
大模型的一大优势,在于其对复杂事物的 Plan(规划)能力和深度思考能力,也就是我们常说的思维链——它天然具备强大的动态推理能力。因此,基于场景问题,利用 TBox 本体模型动态拉取数据后,完全可以直接将数据投喂给大模型,由其进行后续的动态推理,而不必拘泥于传统本体中的推理引擎和推理机。
那么图数据库的推理机还需要吗?需要,但要降级使用,而不是作为核心。前文提到过一种做法:当拉取的数据量较大时,可以先将数据送入图数据库,利用其推理引擎进行预处理,缩减数据规模,再交由大模型处理。这里需要明确——这并非让传统推理机重新成为核心,而是将其作为大模型可按需调用的工具。在整体编排中,它是一个高效的预处理算子;指挥权仍然掌握在大模型手中。
拉取实例数据后,避免条件反射式地映射为知识图谱
接下来是一个特别想提醒的关键要点。
基于本体模型拉取实例数据后,这些数据并不一定要构建成知识图谱,也不一定需要形成以对象关系为核心的实例图结构。见过太多人,一拉取出实例数据就条件反射地想要"映射到知识图谱"——这种惯性思维需要克制。
这里把话说得更准确一些:是否需要物化成图,取决于推理任务的形态。如果任务涉及多跳关系推理、路径查找、社群发现,那么图结构反而是最优选择,这种情况下应当直接使用图数据库;但如果任务像供应链场景那样是计算密集型的,强行先映射成知识图谱就有些大材小用了。因此,原则不是"映射成 KG 是错误的",而是"根据推理任务选择数据结构,不要条件反射式地一切往图上靠"。
真正拉取出来的实例数据,往往需要精确算法与动态逻辑的融合推理。精确算法定义在哪里?正是前文提到的、固化在本体中的场景模型。
精确算法与动态推理的协同:算法负责什么,大模型负责什么
可以回顾一下前文提到的供应链本体案例:先拉取订单进行计算,再拉取 BOM 进行分解,然后拉取库存数据,最终生成采购指令。说白了,这就是经典的 MRP(物料需求计划),是一套确定性算法——整个大阶段的骨架是提前明确定义好的。
但骨架的每个节点内部,可能涉及需要判断、允许一定置信度的动态推理。这才是大模型应该发挥作用的地方。因此,所谓的"融合"并非含糊地混在一起,而是要明确划分:哪些节点是确定性算法——例如 BOM 展开、净需求计算、库存冲减,这些必须保证可证正确、可复现,交给算法;哪些节点是模糊判断——例如供应商优先级的权衡、异常订单的归因、替代料的取舍,这些容忍模糊性、需要语境理解,才交给大模型。
确定性的骨架保证了结果的可靠性,大模型则负责填充骨架内部那些需要判断的环节。这项任务,传统的图数据库推理、SPARQL 和 SHACL 推理根本无法完成,因为它们只具备确定性的一半能力;而纯大模型直接盲目推理,又会丢失确定性的另一半。两者单独使用都不可行,必须进行融合。
无法回避的问题:可信性与可审计性
讲到这里,企业实践者一定会追问一个问题——采购指令是由大模型推导出来的,如果出错了谁来负责?如何证明其正确性?同样的输入条件下,下次能否得到一致的结果?
这是无法回避的问题。传统推理机最大的价值,其实不在于"能够推理",而在于给定事实和规则后,结论具备可靠性(soundness)、可追溯性和可解释性。如果将推理重心全部交给大模型,相当于用一个黑盒换掉了最宝贵的确定性保障。
答案不是退回传统形式化栈,而是将整个架构理解为编排(orchestration):大模型负责担任 Planner(规划者)和模糊判断者,它是指挥官;确定性算法、图推理、SHACL 校验等,是它可调用的工具;关键结论——尤其是涉及资金、合规、生产指令的——必须经过确定性校验或回放验证才能最终落地。
这样阐述,"以大模型推理为核心"在企业语境中才能真正站得住脚。核心的含义是指挥协调,而非独自承担正确性责任。可信性与可审计性,恰恰是依靠那些被降级、被编排进来的确定性能力来兜底保障的。
总结与展望
因此,我们一直强调:在 AI 大模型时代,本体论实践必须以大模型自身的推理为核心,构建"算法 + 推理"的融合推理能力。但请注意,这里说的是将传统的本体推理机、推理引擎从推理范式的中心位置降级,使其成为大模型可按需调用、用于保障可信性的工具——而非将其完全抛弃。降级与编排,而非摒弃,这才是本文真正想要传达的核心思想。
今天的分享到此结束,希望对各位有所启发与帮助。




