近日,业界迎来重大进展——百度文心正式推出新一代OCR模型PP-OCRv6,一次性发布Tiny、Small、Medium三款模型,支持50多种语言,覆盖从浏览器端到嵌入式设备再到服务器的全场景需求。据公开数据表明,PP-OCRv6再度刷新OCR领域的评测纪录,综合性能已跃居全球第一。
尤其值得一提的是PP-OCRv6 Tiny,其模型体积仅1.5MB,可直接部署在本地浏览器环境中,单张图片预测最快仅需97毫秒。这意味着用户数据无需上传云端即可完成OCR处理,既保障了隐私安全,也大幅降低了部署门槛。有开发者评价称,这可能是全球唯一能在浏览器环境运行的高精度OCR模型,相当于为Agent装上了“眼睛”,在智能办公、教育、工业等场景中提供更轻量、高效的视觉感知能力。
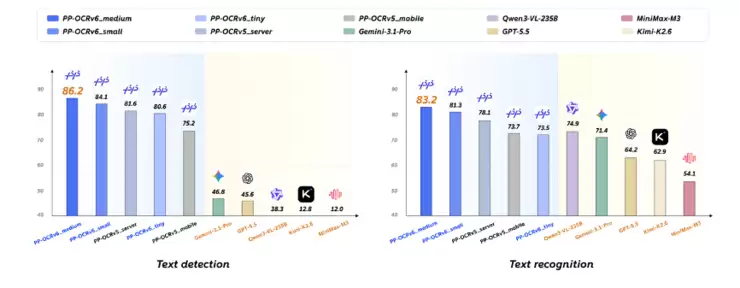
在性能方面,PP-OCRv6在保持轻量化优势的同时,识别精度和推理速度进一步提升,综合性能显著增强。具体来看,它在文本检测和文本识别两个任务上分别取得86.2和83.2的分数,双双刷新此前由PP-OCRv5保持的OCR领域最佳纪录。整体表现甚至优于Qwen3-VL-235B、GPT-5.5、Gemini-3.1-Pro等国内外主流多模态大模型,在OCR专业任务上展现出更强的竞争力。
从v1到v6:持续演进的OCR生态
作为文心大模型多模态能力的重要支撑,PP-OCR系列近年来持续推动文本检测与识别技术的升级,从PP-OCRv1迭代至如今的PP-OCRv6。目前,PP-OCR系列所在的PaddleOCR项目已支持超过110种语言识别,服务覆盖全球170多个国家和地区。
凭借轻量化、高精度等优势,PP-OCR系列已被广泛集成到UmiOCR、MinerU、TurboOCR等业界常用OCR工具链中,在文档解析、数据处理、知识库构建等场景中发挥关键作用,成为开发者和企业广泛采用的开源OCR解决方案之一。同时,它也成为各大模型团队进行数据预处理、文档解析和知识提取的核心工具,为模型训练与应用落地提供坚实支撑。在GitHub上,PaddleOCR的Star数量已突破8.22万,超过谷歌旗下开源OCR标杆项目Tesseract OCR,成为全球最受关注的开源OCR项目之一。
目前,PP-OCRv6已正式上线PaddleOCR正式版,用户可通过网页或API快速调用,同时代码和模型权重均已开源,方便广大开发者下载部署。可以预见,随着更多应用场景的接入,OCR在智能体时代的价值将进一步释放。




