SQL Server 索引创建方式详解
在目标表上右键打开,选择“索引” → “创建索引” → “非聚集索引”,这是 SQL Server 中建立索引最常用的操作流程。
在此之前,我们先明确两个核心概念:聚集索引与非聚集索引。打个比方,聚集索引就像按拼音排序好的字典正文,整张表通常只能拥有一个;而非聚集索引则像一本独立的“偏旁部首速查手册”,它仅存储“关键字段 → 实际数据 ID”的映射关系。要获取实际数据,还需通过该 ID 返回聚集索引进行回表查询。
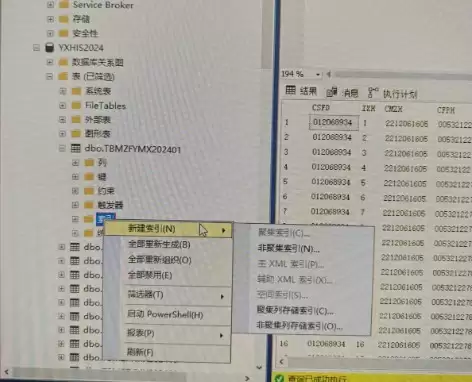
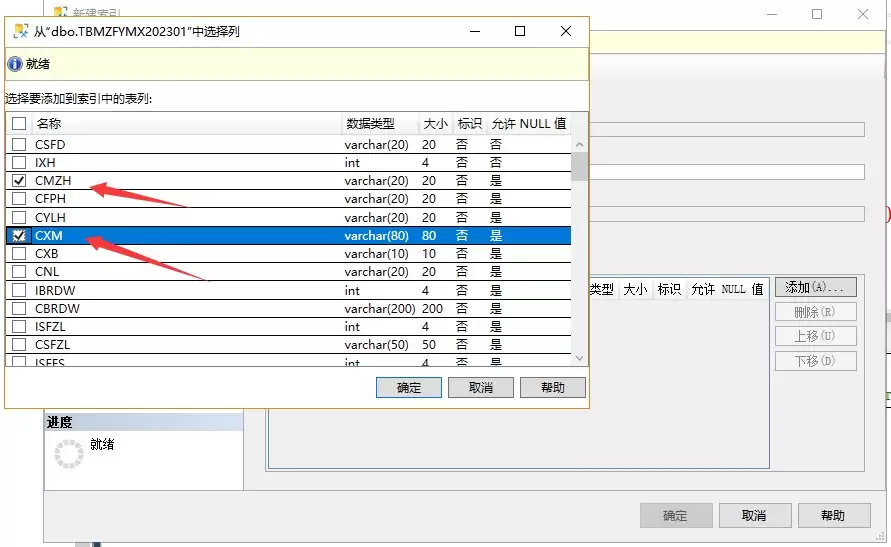
接下来选择需要建立索引的字段,通常优先选取查询条件中频繁使用的列。
然后编写一条 SQL 查询语句来验证索引对性能的实际影响。
索引效果对比分析
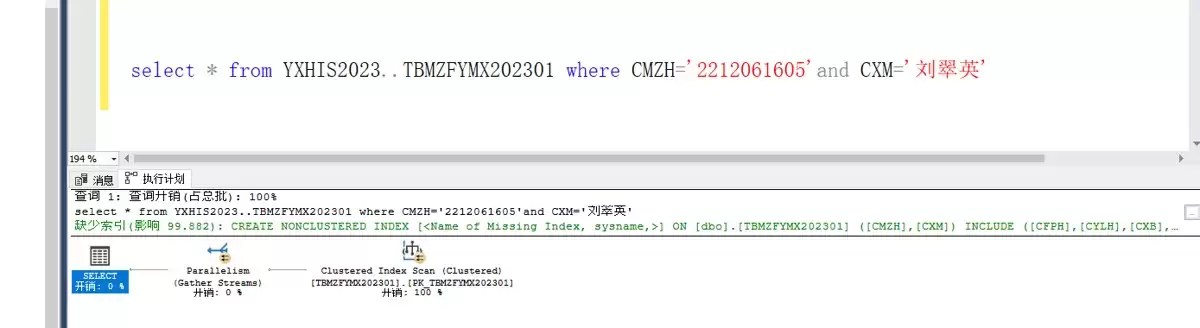
以下是没有索引参与的查询计划示例——全表扫描,性能较低,所有数据行都需要逐行检查。
而这是启用索引后的执行计划,可以看到查询成本大幅下降,检索效率明显提升。
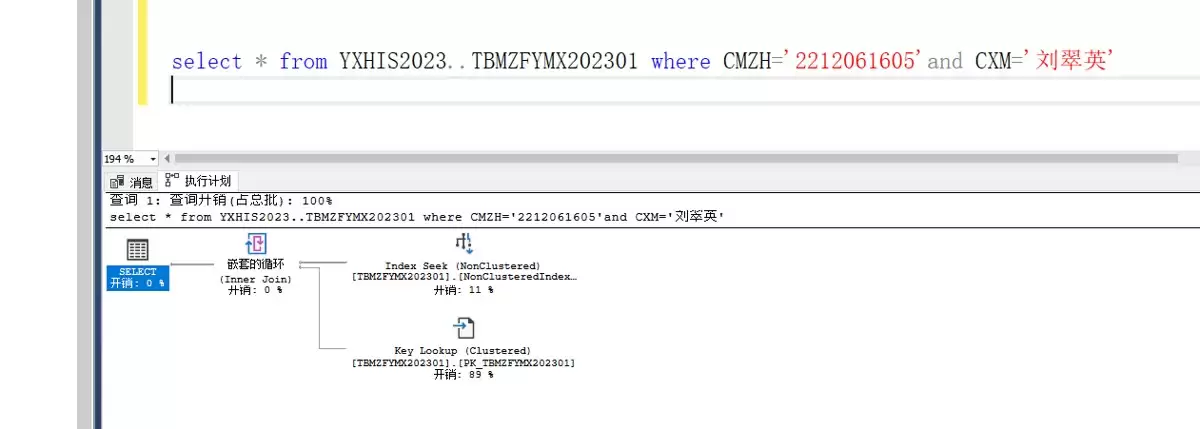
这里有一个值得关注的细节:为什么执行计划中会出现百分比差距?
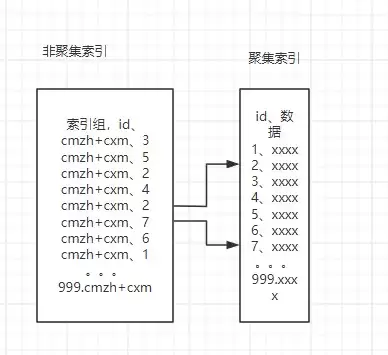
原因在于该非聚集索引仅覆盖了 CMZH 和 CXM 两个字段。如果查询还需要其他字段,SQL Server 必须通过索引中找到的 ID 返回聚集索引“补货”,这一过程会增加额外的 I/O 开销。
若这张表没有聚集索引,情况会更复杂:会触发一种称为 RID Lookup 的操作,直接定位物理页地址,效率自然非常低下。
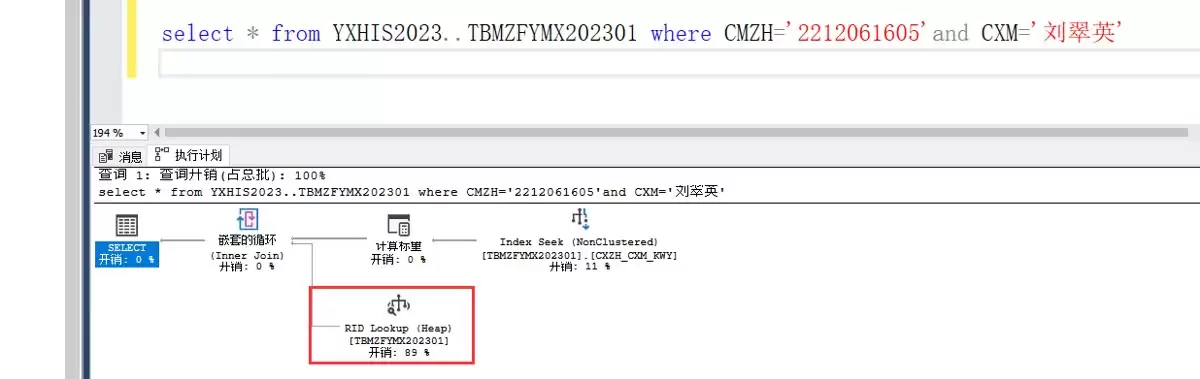
因此结论很明确:每个数据表都应当拥有聚集索引。通常建表时主键会默认设置为聚集索引,但无论是否默认,确保表至少有一个聚集索引是优化查询性能的基础步骤。
总结
简单来说,索引就像书籍的目录——合理使用能大幅提高查询速度,反之则会导致查询缓慢。与其让数据库执行全表扫描这种“体力活”,不如在设计阶段就规划好索引策略,这才是提升 SQL Server 性能的根本之道。




