近期在项目开发中遇到一个典型的数据库迁移场景:需要从.MDB文件(Microsoft Access数据库)中提取数据,并导入到现有系统的数据库。同事将文件发来后,我首先尝试本地打开查看结构,但试了多种方式均未成功——Microsoft Access需要付费激活,其他工具也无法兼容。后来搜索发现,可先将.MDB导入SQL Server再处理。既然都要走数据库链路,不如直接通过Docker部署一个SQL Server环境更高效。于是翻出之前的笔记,结果发现镜像路径已经更新,索性重新整理一份完整的操作步骤分享出来。
什么是.MDB文件?了解Access数据库格式
.MDB文件是Microsoft Access数据库的专用格式,属于微软开发的桌面级关系数据库管理系统(RDBMS)文件类型。它通常应用于以下场景:
- 桌面级数据库应用:用于中小型业务的数据管理,例如库存、客户信息等。
- 原型快速开发:快速搭建数据库应用的演示原型。
- 自定义报表生成:创建和管理灵活的报表内容。
- 与Office生态集成:与Excel、Word等组件实现无缝数据对接。
使用Docker部署SQL Server数据库
创建docker-compose.yml配置文件
首先创建一个部署目录 sqlserver,并在其中新建docker-compose.yml,配置如下:
services:
sqlserver:
image: mcr.microsoft.com/mssql/server:2025-latest
container_name: mssql-server
restart: always
environment:
# 同意最终用户许可协议
- ACCEPT_EULA=Y
# SA用户密码:长度至少8位,且包含大写字母、小写字母、数字和符号中的三类字符
- SA_PASSWORD=Abcd1234
ports:
- 1433:1433
volumes:
- ./mssql:/var/opt/mssql
创建数据挂载目录并设置权限
在docker-compose.yml同级目录下创建数据挂载目录 mssql,并赋予读写权限:
# 创建挂载目录 mkdir mssql # 设置目录权限 chmod -R 777 mssql
启动SQL Server容器
在同级目录执行以下命令启动服务:
docker-compose up -d
若启动时遇到权限错误 Access denied errno = 0xD(13) Permission denied,重新给挂载目录赋权限后再启动容器即可解决。
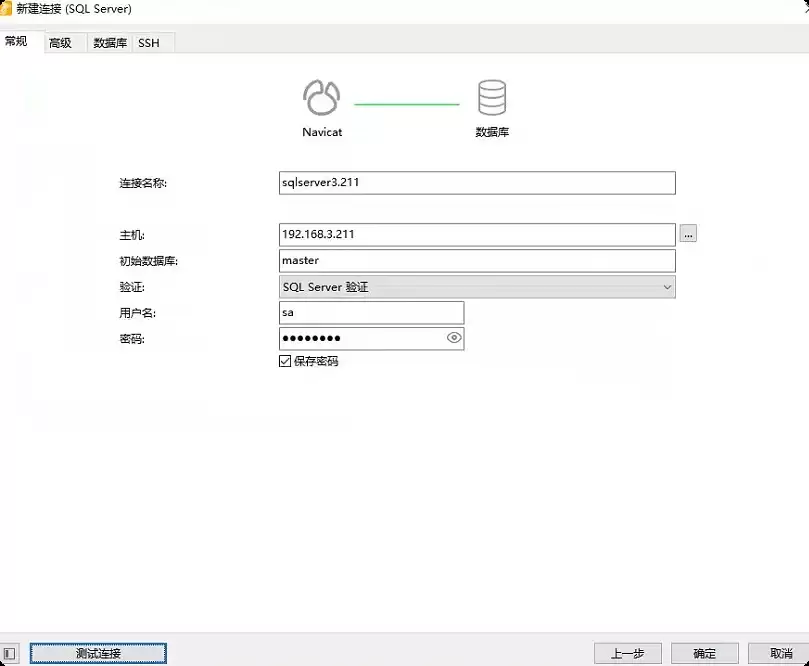
连接数据库
使用Navicat连接数据库。旧版本需要在安装目录下额外安装 sqlncli,但新版本直接连接即可,省去了不少配置步骤。
将.MDB文件导入SQL Server数据库
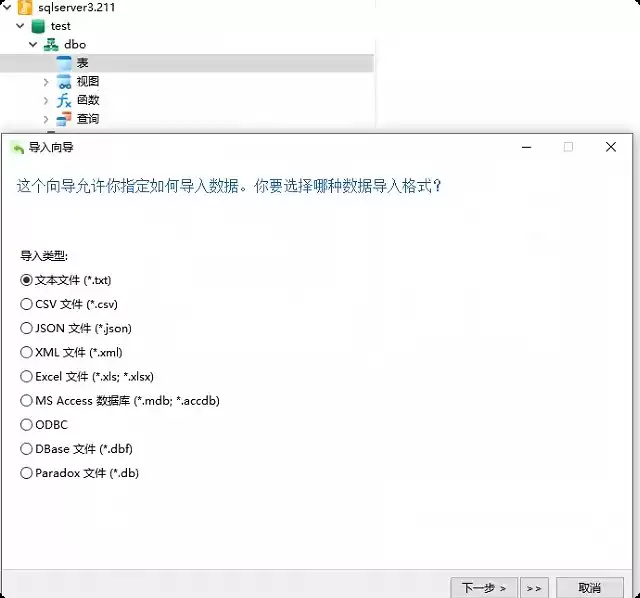
连接到SQL Server后,新建一个目标数据库。在“表”上右键选择“导入向导”,数据源选择 MS Access 数据库,点击下一步并勾选需要导入的表。数据将原样导入SQL Server中,之后即可像普通数据表一样查看、查询和操作。如需修改数据,改完后再导出文件即可。
总结
通过Docker部署SQL Server,再借助Navicat这类工具,可以高效、灵活地处理.MDB文件(Access数据库)。这种方法既省去了本地安装Access的成本与限制,也便于在开发环境中进行数据迁移和格式转换。对于临时或频繁需要处理Access数据的开发运维场景,该方案非常实用——环境隔离性好,且可以重复利用。
以上就是使用Docker部署SQL Server并导入.MDB文件的完整指南,希望能帮助到有类似需求的读者。




