一、一夜之间,测试脚本又红了
最近和几个团队聊起天,大家一开口就是同一件事:自动化用例的维护成本,快压不住了。
页面改个ID,脚本倒一片;接口加个字段,断言全挂。环境稍微抖一下,CI流水线秒变红灯,然后就得有人蹲在屏幕前修到半夜。啊,谁懂啊。
更让人焦虑的是,AI测试工具越来越多,但问题反而更复杂了。引入大模型、RAG、Agent之后,失败的链路变得更长。你根本搞不清楚,到底是模型抽风了,还是工具链断了,还是业务逻辑本身已经悄悄变了味。
很多人心里已经清楚:传统那种手工修脚本的模式,已经跑不过需求的迭代速度了。
上周有个真实的例子:某电商大促前,登录页突然加了滑块验证。三十多个核心用例,一个不落,全挂了。三个测试同学通宵改代码,结果第二天上线前又改了一版,又挂。这场景,像不像你正在经历的事?
那如果脚本自己能修自己呢?
这可不是什么科幻小说。最近在一线团队里,已经开始落地一种“自进化”的测试技能——AI Agent遇上失败,自动分析原因、改写Skill,验证通过后直接入库。下次再碰到同类问题,Skill池里已经有了解法。
二、本质变化:从“修脚本”到“养技能”
很多人把AI测试理解成“让AI帮我写用例”。这个理解太浅了。
真正的本质变化只有一个:把测试知识从代码里抽出来,变成可执行、可演化、可复用的Skill。
传统自动化,逻辑是硬编码在脚本里的。页面定位变了,你得改代码;业务规则变了,你还得改代码。每一次变更,都像一次大手术。
而在自进化测试体系下,脚本只干一件事:调度Skill。Skill里封装了“怎么做”——比如“在登录页输入账号密码并提交”。当这个Skill执行失败时,不是直接报错了事,而是触发一个Agent。
这个Agent的任务是:判断失败原因,调用LLM和工具链,生成一个新的Skill版本,验证通过后,写入Skill库。
背后的逻辑非常清晰:把维护工作从“事后人工修复”,变成“运行时自动闭环”。人需要做的,只是定义边界和做评审,剩下的演化,交给Agent去完成。
三、核心机制拆解:失败 → 归因 → 改写 → 入库
下面这张图,是我们在一个实际项目中跑通的流程。
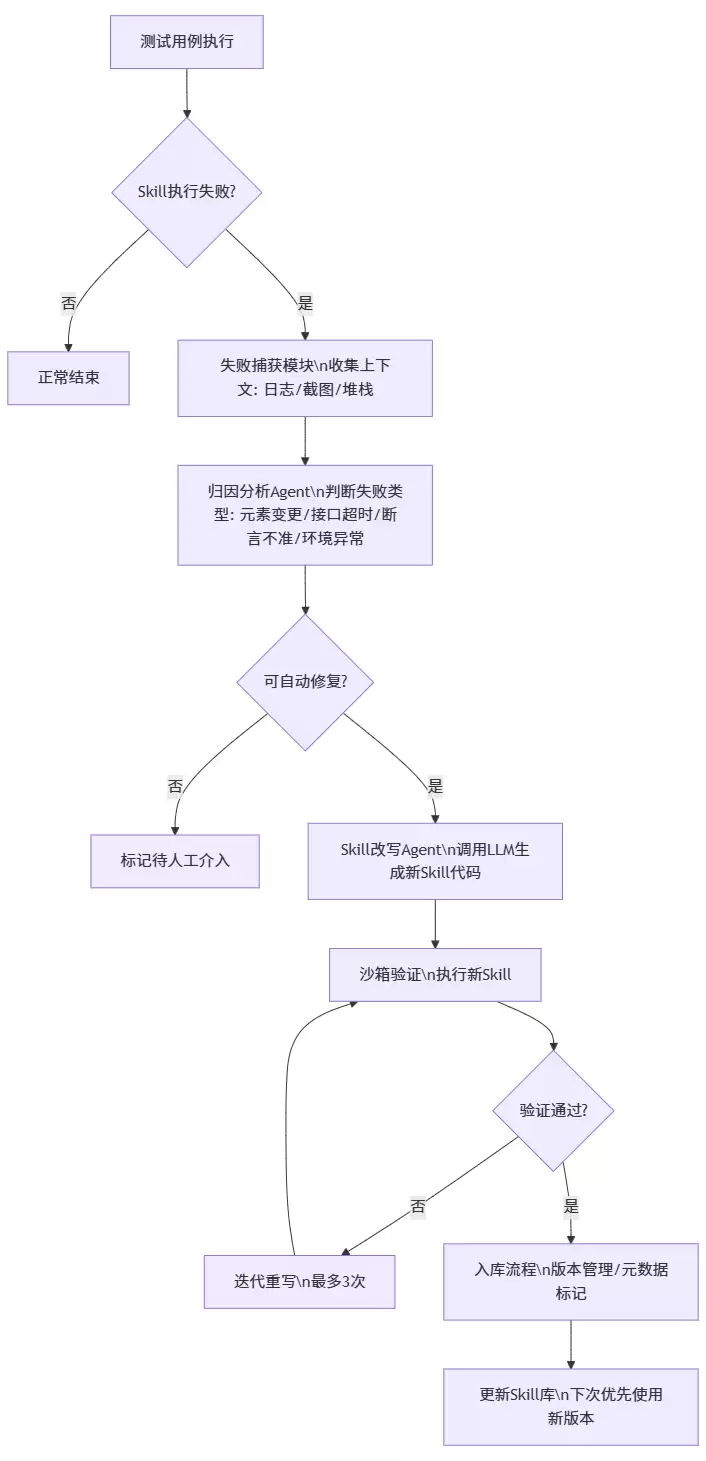
拆解几个关键点:
1. 失败捕获不是简单拿个状态码
我们要求捕获的是:页面DOM快照、网络请求记录、控制台日志、截图、以及失败前的操作序列。这些上下文,直接决定了归因的准确率。
2. 归因Agent用的是轻量规则 + LLM组合
先用规则筛出一批明显问题(比如timeout、404),剩下的丢给LLM分析。核心提示词里要求输出:失败类型、根因定位、建议的修复动作。实测下来,准确率大概70%左右,这个水平已经足够触发后续的改写了。
3. Skill改写不是“重写整个函数”
我们规定每个Skill必须是一个纯函数,输入输出明确。Agent拿到失败Skill的源码和归因结果后,会尝试局部修改——比如改定位器、加等待逻辑、换API调用方式。生成后立刻在隔离环境里跑一遍。
4. 入库不是简单的git push
新Skill会打上版本号、所属业务域、失败场景标签,并存到向量库。后续执行时,Agent会根据当前上下文从库中检索最匹配的Skill版本。换句话说,Skill是活的,越用越准。
为什么这么设计?因为传统方式下,一个人修完脚本,另一个人遇到同样问题还得再修一遍。有了Skill库,一次修复,全员受益。
四、典型案例:登录验证码变了,AI自己学会了打码
回到开头那个电商案例。
原始Skill:
login.skill — 打开登录页,输入用户名密码,点击登录。
某天运营加了两层验证:图形验证码 + 信息验证。Skill执行失败。归因Agent判断:页面出现新的验证码元素,属于“交互流程变更”。
Skill改写Agent做了三件事:
- 从失败截图识别出验证码类型(图形码)
- 调用内部打码服务的MCP工具
- 生成新的Skill:输入账号密码 → 读取验证码 → 调用打码 → 等待信息 → 输入信息码
沙箱验证通过后,新Skill以v2版本入库。第二天另一个业务线的测试用例也遇到验证码,自动检索到了这个Skill并复用。
传统做法:测试同学先发现失败,找开发确认,然后手写打码集成代码,再更新所有用到登录的用例。少说2小时。
自进化做法:第一次失败后3分钟完成改写入库,后续全部自动适配。
差距不在于速度,而在于规模化的维护成本——当你有200个用例依赖登录步骤时,改一个Skill比改200个脚本,要可靠得多。
五、工程落地启示:你现在就能搭的反馈闭环
别觉得这套东西很遥远。我们团队用一个周末就搭出了最小原型。关键组件就三块:
- 一个能调用LLM的Agent(LangGraph或自研轻量框架)
- 一个Skill存储库(文件系统+向量库就够)
- 一个沙箱执行环境(Docker或本地临时进程)
落地建议:不要一开始就想全自动。先做半自动。
第一步:在测试框架里加一个钩子,失败时打印“可尝试自动修复”,并给出Agent建议的新Skill代码,让测试人员确认后入库。
第二步:等确认准确率满意了,再打开自动验证+自动入库。
第三步:最后做跨项目/跨团队的Skill检索和复用。
对还在校园的同学来说,这是个非常好的切入方向——不需要懂复杂的分布式系统,只要搞明白“失败归因+LLM改写”这个闭环,就能做出让人眼前一亮的作品。
对初级工程师,这是从“写脚本”到“设计反馈系统”的方法论跃迁。
对中级工程师,这是降低团队维护负债的实际武器。
六、问自己一个问题
上面这套链路,我们已经跑通了电商、金融、企业内部系统三类场景。代价是增加了一次LLM调用和几秒钟的改写验证时间,换来的却是脚本维护的人力下降60%以上。
但这套方案距离“银弹”还有相当距离。归因的准确率、改写的安全性、入库的版本管理,每个环节都有坑。
这里只留下一个值得拿到团队里认真讨论的问题:
你的测试系统,现在有没有能力在失败后自动学习,并且自我改进?
如果答案是“不能”,那第一个要改的,可能不是脚本,而是你对待失败的视角——失败不应该只是红色标记,它应该是下一次进化的输入。




