按理说,一个能自主读代码、跨文件编辑、跑测试、修bug、提PR的coding agent,底层应该有一套相当复杂的调度系统。状态机、有向无环图、任务规划器、多步推理引擎,总得有几样吧。
结果Anthropic今年4月放出了一篇关于Claude Code设计空间的论文(arXiv 2604.14228),里面披露的架构让人相当意外。Claude Code的核心,剥掉所有外围系统之后,就是这么一个东西:
while (true) {
response = await callModel(context)
if (response.done) break
result = await executeTool(response.toolCall)
context.append(result)
}
一个async generator函数,叫queryLoop(),跑在所有接口上——CLI、SDK、IDE插件、Web端——都是同一个循环。这不是简化后的伪代码,这就是它的实际结构。
整个Claude Code代码库里,决策逻辑(也就是决定“下一步做什么”的代码)只占1.6%。剩下的98.4%都是operational harness:权限系统、context压缩、工具执行、安全护栏。
这跟我们直觉中对“复杂agent系统”的想象完全相反。
一个while循环能做什么
这个循环的运行模式属于ReAct模式(Reasoning + Acting)。模型负责推理和决策,harness负责执行和反馈。每一轮循环是这样的:
- 模型看到当前context(系统提示 + 对话历史 + 所有工具调用结果)
- 模型输出一个决策:是结束,还是调用某个工具
- 如果是工具调用,harness执行它,把结果追加到context里
- 回到步骤1
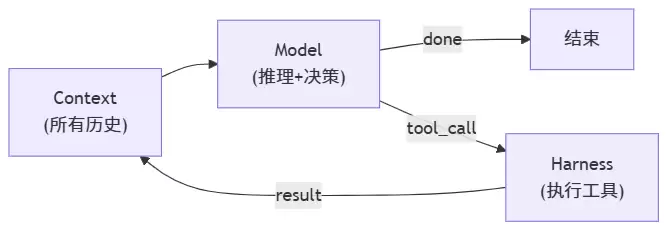
这里面没有任何预设的step顺序。模型看到什么context,就决定下一步做什么。读了一个文件发现里面import了另一个模块,就去读那个模块。跑了测试发现失败了,就去分析错误。修了代码再跑测试,通过了就停下来。每一步都是根据上一步的结果动态决定的。
这就是为什么它是一个动态工作流,而不是静态流水线。
最少的脚手架,最厚的护甲
Anthropic在论文里用了一个精确的表述:Minimal Scaffolding, Maximal Operational Harness。
翻译一下就是:不要试图用代码结构去约束模型的决策路径(少搭脚手架),而是给它提供一个尽可能丰富的运行时环境(厚的护甲),让它自己做判断。
跟主流agent框架的对比就很清楚了:
| 框架 | 核心调度机制 | 决策者 | 复杂度分布 |
|---|---|---|---|
| LangGraph | 显式状态图,边上有条件分支 | 图结构 + 模型 | 重在图定义 |
| Devin | 任务规划结构,plan-then-execute | 规划器 + 执行器 | 重在规划层 |
| SWE-Agent | 容器隔离 + 受限工具集 | 模型(在沙箱内) | 重在隔离层 |
| Aider | Git-based rollback | 模型 + Git | 重在版本控制 |
| Claude Code | while循环 + ReAct | 模型(几乎完全) | 重在运行时护甲 |
Claude Code把几乎所有决策权都交给了模型。它不告诉模型“你应该先读文件再写代码再跑测试”,它只给模型提供了这些工具,然后说“你自己看着办”。
这背后的设计信念是:对于一个足够强的模型,显式的调度脚手架不是帮助,而是束缚。当模型的推理能力足够强的时候,让它自己决定下一步比给它预设路径更优。前提是你得给它足够好的工具和足够安全的执行环境。
五层Context压缩流水线
while循环虽然简单,但有一个硬约束:context window是有限的。每跑一轮循环,context都在增长(模型输出 + 工具结果)。如果不管理,很快就会爆掉。
Anthropic在论文里披露了一个五层顺序执行的压缩流水线,在每次调用模型之前运行:
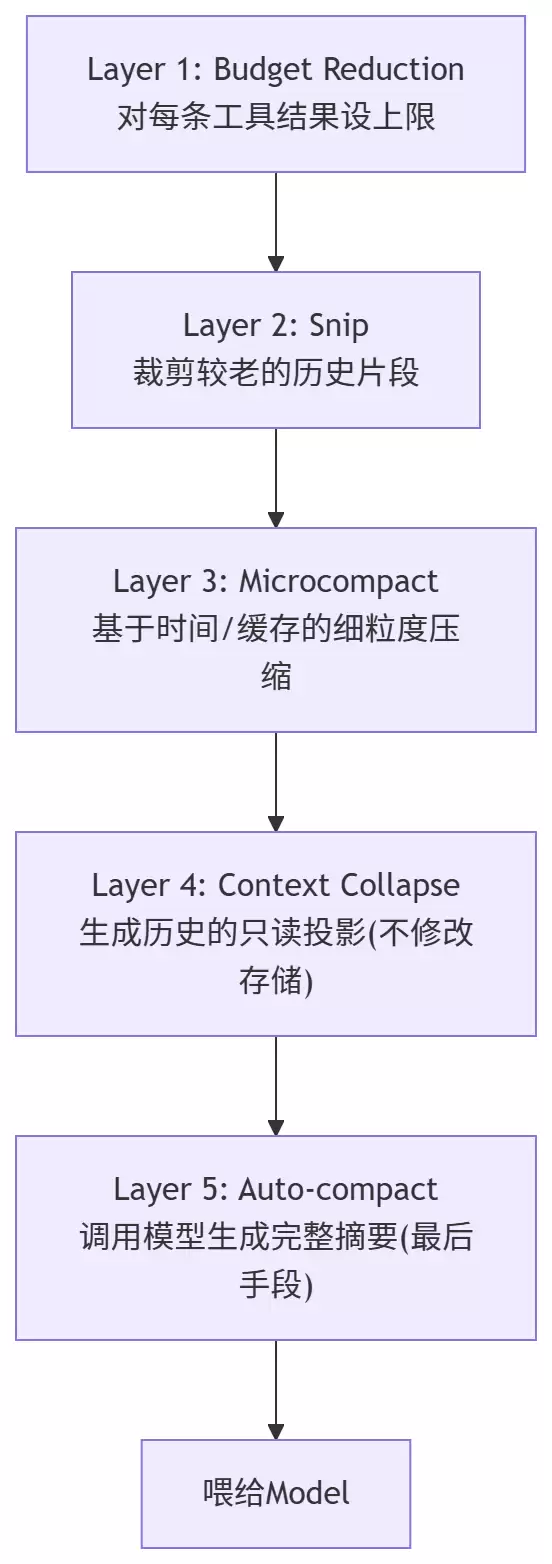
| 层级 | 名称 | 做什么 | 触发条件 |
|---|---|---|---|
| 1 | Budget Reduction | 对每条消息的工具输出设大小上限 | 每次调用前 |
| 2 | Snip | 裁剪较早的历史段落 | context超阈值 |
| 3 | Microcompact | 基于时间衰减或prompt cache友好性做压缩 | context继续超阈值 |
| 4 | Context Collapse | 不修改底层存储,生成一个“只读投影”给模型看 | 更高压力 |
| 5 | Auto-compact | 调用一次模型做完整摘要 | 前四层不够时的最后手段 |
这五层的设计有两个精妙之处。
第一,Layer 4的“Context Collapse”是一个只读投影。它不修改实际的会话存储(JSONL文件),只是给模型“看到”一个压缩后的版本。带来的好处是:你随时可以rewind到任何checkpoint,因为原始数据还在。
第二,五层是顺序尝试的。只有前一层不够用了才触发下一层。大多数时候跑到Layer 2就够了,Auto-compact(调用模型生成摘要,最贵的操作)只在极端情况下触发。
动态工作流 vs 静态Pipeline
回到核心问题。为什么Claude Code是“动态工作流”而不是一个更传统的pipeline?
静态Pipeline(比如CI/CD、LangGraph的图、或者Devin的plan-execute)的特点是:
- 步骤是预定义的
- 顺序是固定的(或有限的条件分支)
- 运行时不改变结构
- 可预测,但缺乏应变能力
Claude Code的动态工作流则是:
- 没有预定义步骤
- 每一步由模型根据当前状态决定
- 可以在运行中完全改变策略
- 不可预测,但极强的应变能力
一个具体的例子。假设你给Claude Code一个任务“修复这个auth bug”。
在静态pipeline里,你可能设计成:读错误日志 → 定位出问题的文件 → 生成fix → 跑测试 → commit。
在Claude Code的动态工作流里,实际执行路径可能是这样的:
- 跑测试看报错 → 读auth.ts → 发现import了tokens.ts → 读tokens.ts
- 发现tokens.ts里调用了一个deprecated的API → 搜索这个API在哪里被替换了
- 找到新API → 但发现新API的签名不一样 → 需要同时改middleware.ts
- 改了三个文件 → 跑测试 → 新的测试过了但另一个测试挂了
- 读挂掉的测试 → 发现是test fixture过期了 → 更新fixture → 全部通过
这个路径不可能被预先设计出来。它是模型根据每一步的反馈动态生成的。这就是“动态”的核心含义。
Dynamic Workflows:脚本化的编排层
说到这个,Anthropic在v2.1.154之后引入了一个跟上面同名但层次不同的功能——Dynamic Workflows(大写)。
这是一个更高层的编排能力。你给Claude一个复杂任务,Claude不是自己用while循环一步步跑,而是先写一个Ja vaScript编排脚本,然后由一个运行时并行执行这个脚本里定义的多个子agent。

跟普通subagent的区别就在于:
| 维度 | Subagents | Dynamic Workflows |
|---|---|---|
| 编排者 | Claude模型(逐turn决策) | Ja vaScript脚本(代码化的计划) |
| 并行度 | 每turn几个 | 最多16个并发,总计1000个agent |
| 中间结果 | 在Claude的context里 | 在脚本变量里(不占主session context) |
| 可复用 | 只有worker定义可复用 | 整个编排逻辑可保存为命令 |
| 适用场景 | 中等规模委托 | 大规模审计、迁移、交叉验证研究 |
Dynamic Workflows的一个精妙设计是对抗性验证。编排脚本可以让一组agent做研究,然后让另一组agent独立审查前一组的结论。因为每个agent有独立context,审查者看不到研究者的推理过程,只看到结果,所以能提供真正独立的second opinion。
一个容易混淆的点:Claude Code“是一个动态工作流”(小写,指它的while循环架构),同时“提供了Dynamic Workflows功能”(大写,指脚本化编排)。前者是底层架构范式,后者是建立在前者之上的一个高级feature。
跟竞品的架构路线对比
这一段值得专门讲。当前主流的AI coding工具,在架构上走了三条完全不同的路线。
路线一:补全增强(Cursor / GitHub Copilot)
核心模式是“用户主导,AI辅助”。用户在IDE里写代码,AI在旁边提供补全、解释、修改建议。AI不主动做事,不自己跑命令,不自主决策。context基本限制在当前文件和少量相关文件。
这条路线的优势是可控性极强,劣势是无法处理需要多步推理的复杂任务。Cursor后来加了Composer/Agent模式往agentic方向靠,但底层还是IDE优先的架构。
路线二:计划-执行(Devin / Codex)
核心模式是“AI先做计划,确认后执行”。系统有一个显式的规划阶段,生成task list和实施步骤,然后按计划逐步执行。Devin在云端沙箱里跑,Codex也走类似路线。
这条路线的优势是可审查性好(你能在执行前review计划),劣势是计划一旦定下来,应变能力有限。实际中agent经常遇到计划里没预料到的情况(文件结构不符预期、API变了、测试暴露了新问题),rigid的计划会成为负担。
路线三:反应式循环(Claude Code)
核心模式是“模型自主决策,harness提供环境”。没有预设计划,没有固定步骤,模型根据每一步的反馈实时决定下一步。planning不是一个独立阶段,而是融入每一步的推理中。
这条路线的优势是应变能力极强(能处理任何unforeseen situation),劣势是不可预测(你不知道它接下来会做什么)、成本不可控(token消耗取决于模型决策路径)。
七级权限光谱:动态工作流的安全层
一个纯while循环如果没有安全机制,就是一个可以执行任意命令的脚本。Claude Code的解法不是限制循环能力,而是在循环外面套了一层权限系统。
这套系统有七个权限模式,形成一个“渐进信任光谱”:
| 模式 | 约束程度 | 适用场景 |
|---|---|---|
| Plan | 只读,不能改任何东西 | 纯调研/代码审查 |
| Default | 每次编辑/命令都要确认 | 新手/敏感项目 |
| Accept Edits | 文件编辑自动通过,命令仍需确认 | 日常开发 |
| Auto | ML分类器自动评估,只拦截高风险 | 信任度较高时 |
| Don"t Ask | 自动拒绝需要确认的操作 | CI/非交互场景 |
| Bypass Permissions | 跳过所有确认 | 完全信任(慎用) |
| Ultracode | Auto + xhigh effort + Dynamic Workflows | 全力以赴 |
评估顺序是deny-first:deny规则永远覆盖allow规则。这跟防火墙的逻辑一样:默认拒绝,明确允许。
这套权限系统不改变while循环本身的结构,只是在“执行工具”这个环节插入了一个gate。模型仍然可以决定调用任何工具,但harness有权拦截或需要用户确认。
几个还没看清楚的点
while循环的收敛性问题。纯反应式循环没有“步骤上限”的硬约束(除了context window)。如果模型陷入了一个循环(改了A破了B,修B又破了A),目前的机制是context满了自动compact,而不是主动检测循环。社区里有人报告过50轮以上的无效循环。
Dynamic Workflows的成熟度。这个功能目前还是research preview。1000个agent/run的上限和16并发已经很高,但实际生产场景中的稳定性和错误恢复能力还需要更多案例验证。
1.6%决策逻辑的可解释性。把所有决策交给模型,直接后果是你很难事后解释“它为什么选了这条路径”。对于需要审计trail的企业场景,这是一个潜在的合规挑战。
scale问题。每一步决策都需要调用模型推理,执行速度和成本都受制于模型的latency和token价格。对于那些“步骤确定但文件很多”的任务(批量迁移、格式化),static pipeline反而更高效。Claude Code用Dynamic Workflows部分解决了这个问题,但底层还是在调模型。
写在最后
Claude Code的架构选择,本质上是在做一个判断:“把决策权完全交给模型,把工程复杂度全部放在运行时环境上”。这跟传统的agent框架(把决策逻辑编码为图/状态机/规划器)是两个完全相反的方向。
这个选择成立的前提是模型够强。当Claude Sonnet/Opus的推理能力足以在每一步做出合理决策时,所有预设的脚手架都变成了多余的约束。1.6%的决策代码不是偷懒,是对模型能力的一次赌注——赌它不需要外部结构来引导,只需要一个安全的、工具齐全的执行环境。
从目前的结果看,这个赌赢了。
References
- Anthropic, "Dive into Claude Code: The Design Space of Today's and Future AI Coding Agents", arXiv 2604.14228, April 2025, https://arxiv.org/abs/2604.14228
- Anthropic, "How Claude Code works - The agentic loop", 2025, https://code.claude.com/docs/en/how-claude-code-works
- Anthropic, "Orchestrate subagents at scale with dynamic workflows", 2025, https://code.claude.com/docs/en/workflows
- Anthropic, "Best practices for Claude Code", 2025, https://code.claude.com/docs/en/best-practices
- Anthropic, "Explore the context window", 2025, https://code.claude.com/docs/en/context-window
- Anthropic, "Create custom subagents", 2025, https://code.claude.com/docs/en/sub-agents
- Anthropic, "Hooks - Programmable lifecycle events", 2025, https://code.claude.com/docs/en/hooks
- Anthropic, "Permission modes", 2025, https://code.claude.com/docs/en/permission-modes
- Anthropic, "Claude Code CLI Reference", 2025, https://code.claude.com/docs/en/cli-reference
- Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models", ICLR 2023, https://arxiv.org/abs/2210.03629
- Diptendud, "Claude Code vs Cursor vs Windsurf: Which Agentic IDE Wins in May 2026", Medium, 2026, https://diptendud.medium.com/claude-code-vs-cursor-vs-windsurf-which-agentic-ide-wins-in-may-2026-bf7ad498e852
- Anthropic, "Model configuration and extended context", 2025, https://code.claude.com/docs/en/model-config




