核磁共振波谱学在分子结构鉴定中占据着举足轻重的地位,然而解析复杂的谱图数据一直是资深专家的“看家本领”。面对重重峰形与繁复的耦合常数,新手往往无从下手,即便是经验丰富的研究者,也需要综合多种谱学信息反复推敲,才能逐步锁定可能的分子骨架。近年来,深度学习技术的兴起为“从谱图到结构”的自动化解析带来了曙光,但大多数现有方法仍遵循传统路径:先将谱图转化为峰表、耦合模式等文本特征,再输入模型进行分析。这种做法不可避免地丢弃了原始谱图中细微的强度分布和峰形特征。更棘手的是,这类方法很难自然扩展到二维核磁共振实验,而二维谱恰恰是消除结构歧义、确定连接关系的核心利器。
令人振奋的是,一项最新研究为此难题提供了全新方案。研究者提出的NMRViT框架,直接以原始核磁谱图图像作为输入,同时处理一维¹H谱、一维¹³C谱和二维HSQC谱,实现了从“谱图”到“结构”的端到端预测。该模型在大规模模拟数据上完成训练,无论采用单一谱图还是多谱联合输入,表现均十分出色。尤为关键的是,研究团队直面实际应用中的核心障碍——模拟谱图与真实实验谱图之间的“领域差距”,系统评估了迁移性能,并通过少量实验数据微调、结合化学位移重排序策略,大幅提升了模型在真实数据上的鲁棒性。总体而言,这项工作证明了视觉Transformer能够直接从原始NMR图像中“读懂”分子结构信息,为自动化结构解析开辟了一条极具前景的实用路径。

核磁共振波谱在天然产物鉴定、药物研发、有机合成及代谢组学等领域中扮演着不可替代的角色。理论上,一张完整的NMR谱图包含了官能团组成、原子连接方式以及局部化学环境等全部信息。然而理想与现实之间存在巨大鸿沟:从谱图中准确推断出完整分子结构,依然高度依赖经验丰富的研究人员对多种实验数据的综合分析。
过去的算法大多采用“候选库匹配”策略:先枚举大量可能的分子结构,再用量子化学计算或机器学习模型预测其谱图,与实验结果比对后选取最佳匹配。这种方法虽有一定成效,但瓶颈同样明显——只能从现有候选库中挑选,无法发现真正未知的全新结构。
近年来,Transformer和大语言模型的崛起推动了端到端谱图解析技术的发展。研究者开始尝试用神经网络直接将NMR谱图“翻译”为SMILES结构式。不过,多数方法仍沿袭旧路:先将谱图转化为峰列表、峰型等文本符号,再输入Transformer处理。虽然降低了计算压力,但原始谱图中的强度分布细节和噪声特征也随之丢失。
同时,二维HSQC谱能够直接揭示氢原子与碳原子的连接关系,对于消除结构歧义至关重要。然而,如何将一维谱和二维谱统一整合到深度学习框架中,一直是一个棘手的技术难点。此外,模型在模拟数据上表现优异,但迁移到真实实验数据时往往性能急剧下降——这种模拟与实验之间的差距,成为实用化道路上的最大障碍。
正是为了攻克这一难关,研究者推出了NMRViT框架。这个视觉Transformer不走寻常路,直接以原始谱图图像作为输入,旨在将多模态谱图信息在同一深度学习框架中融会贯通,真正实现端到端的分子结构解析。
方法
NMRViT将分子结构解析视作序列生成任务。它首先获取原始的¹H谱、¹³C谱和二维HSQC谱图像,然后将每张谱图切割成若干小块(Patch)。这些图像块经过嵌入处理后,送入Vision Transformer编码器。编码器中的自注意力机制擅长捕捉不同化学位移区域之间的长程依赖关系。随后,一个自回归的Transformer解码器基于编码器提取的谱图特征,逐步“写出”SMILES结构序列。
为提高结构预测的准确性,研究者还将分子式作为额外提示信息输入解码器——这相当于给模型一张“元素清单”,限制生成的分子必须符合给定的元素组成范围。此外,模型引入了名为Patch Dropout的随机丢弃策略,在训练时随机丢弃部分谱图片区。由于NMR谱图具有天然稀疏性(大部分区域无信号),这一操作迫使模型关注不同区域的信息组合,显著提升了对弱峰和缺失峰的鲁棒性。在多模态输入场景下,不同谱图先各自编码,再在统一空间中进行特征融合,使¹H、¹³C和HSQC的信息充分发挥协同效应。最后,模型调用一个外部化学位移预测网络,对生成的多个候选结构进行重排序,选出最可靠的结构作为最终答案。
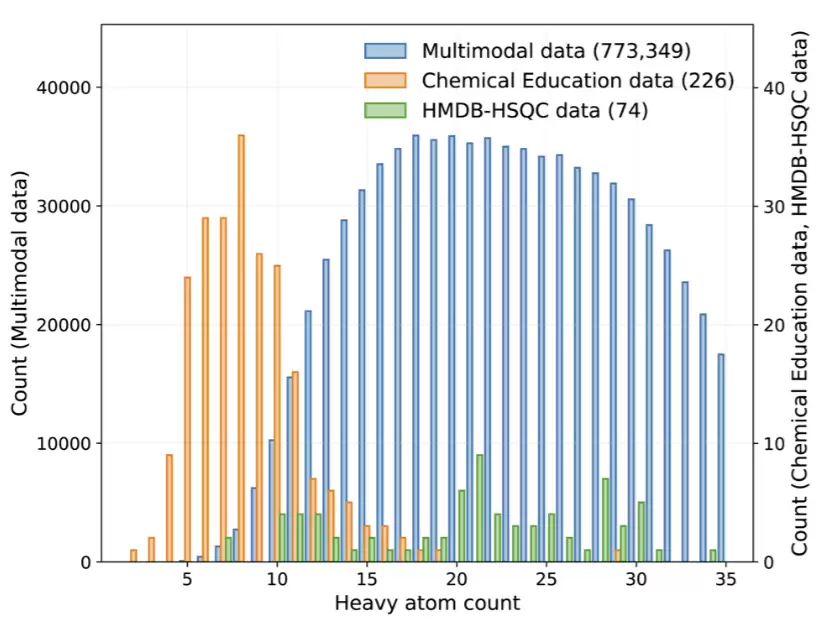
图1: 模拟数据集与实验数据集分子规模分布统计。
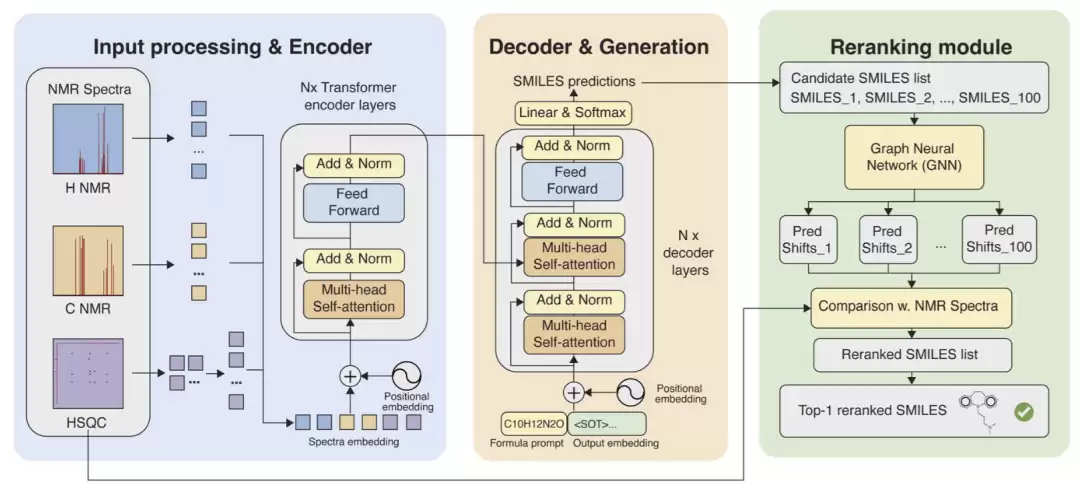
图2: NMRViT总体框架。
结果
在大规模模拟数据集上实现高精度结构解析
研究者首先使用一个包含约79万个有机分子的模拟多模态谱图数据库对模型进行“摸底测试”。结果显示,无论采用哪种谱图输入模式,NMRViT的性能均已达到甚至超越当前最佳方法。
仅使用¹H谱时,模型Top-1结构预测准确率达到71.39%,显著领先于先前基于峰列表编码的方法。关键在于,模型直接利用原始谱图中的强度分布信息——这些细节在传统峰提取操作中往往被视为噪声而被丢弃。
在二维HSQC谱任务上,模型取得了67.97%的Top-1准确率。这属于首批系统评估从二维NMR谱图直接推断分子结构的研究之一,同时也证明了Vision Transformer具备从二维谱图中“识别”结构关联信息的能力。
当整合¹H、¹³C和HSQC三种谱图时,模型表现进一步提升:Top-1准确率飙升至79.12%,Top-10准确率超过91%。这一结果充分说明,多模态融合策略能够充分利用不同谱学实验的互补信息。
分子式提示和Patch Dropout显著增强模型性能
研究者通过一套完整的消融实验,探究了模型各组件的贡献。
结果发现,移除分子式提示后,无论采用哪种谱图输入,预测准确率都明显下降。分子式相当于为结构生成过程划定了范围,提供了全局的元素组成约束,帮助模型缩小搜索空间,避免生成元素组成不合理的候选结构。
同样,关闭Patch Dropout后,模型性能也出现下滑。如前所述,NMR谱图天然稀疏,大部分区域无信号。该策略迫使模型关注不同区域的信号组合,从而对弱信号和偶发缺失信号更加不敏感。
实验数据清晰表明,这两个机制是NMRViT性能大幅提升的两大关键。
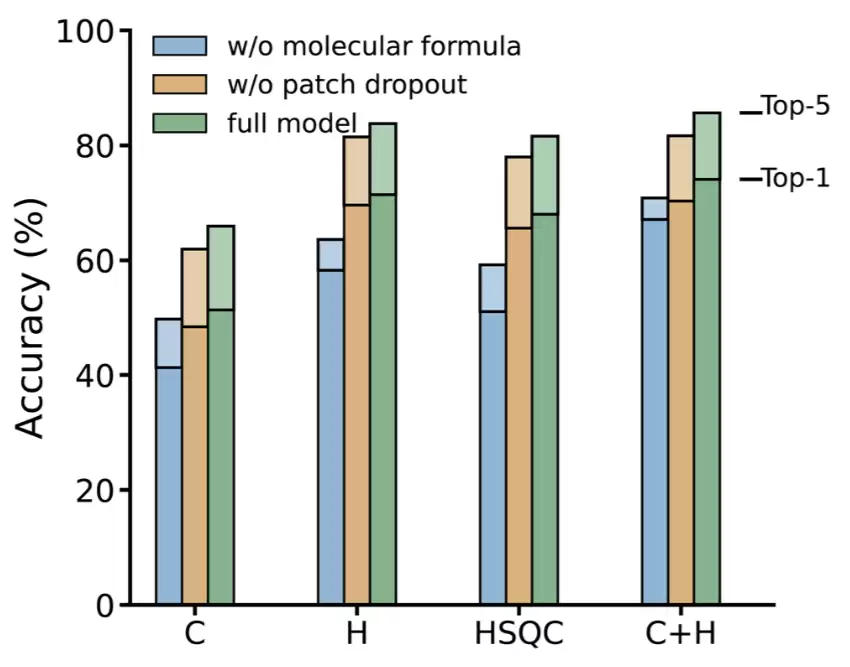
图3: Patch Dropout与分子式提示的消融实验结果。
模拟谱图与真实实验谱图之间存在明显领域差距
接下来,研究者将训练好的模型直接应用于真实实验NMR数据集,不进行任何额外训练,仅作零样本测试。
结果颇为严峻:模型在实验数据上的表现与模拟数据相比判若云泥。仅使用¹H谱时,Top-1准确率从模拟测试集上的71.39%骤降至19.91%。即便针对训练集中已出现过的分子,只要谱图来自真实实验,预测准确率同样大幅下滑。
进一步分析显示,性能下降的元凶并非分子结构复杂度,而是模拟谱图与实验谱图之间的信号分布存在巨大差异:基线漂移、噪声模式、仪器条件差异等,每一个因素都构成障碍。
这一结果揭示了当前谱图生成模型面临的核心挑战:如何跨越模拟数据与真实实验数据之间的“天堑”。
少量实验样本微调即可显著恢复预测能力
为填补这一鸿沟,研究者仅使用约100个实验样本对模型进行了微调。
效果立竿见影!所有谱图模式的性能均获得显著提升。特别是联合使用¹H和¹³C谱时,Top-1准确率跃升至66.15%,已经接近其在模拟数据上的巅峰表现。
最令人惊喜的是,仅需如此少量的实验样本,就能带来如此巨大的性能修复。这说明NMRViT在大规模模拟数据上学到的结构知识具有很强的可迁移性,而微调本质上只是帮助模型“适应”了真实仪器产生的谱图特征。
这一发现对构建未来自动化NMR解析系统意义重大,因为实验标注数据历来稀缺且昂贵。
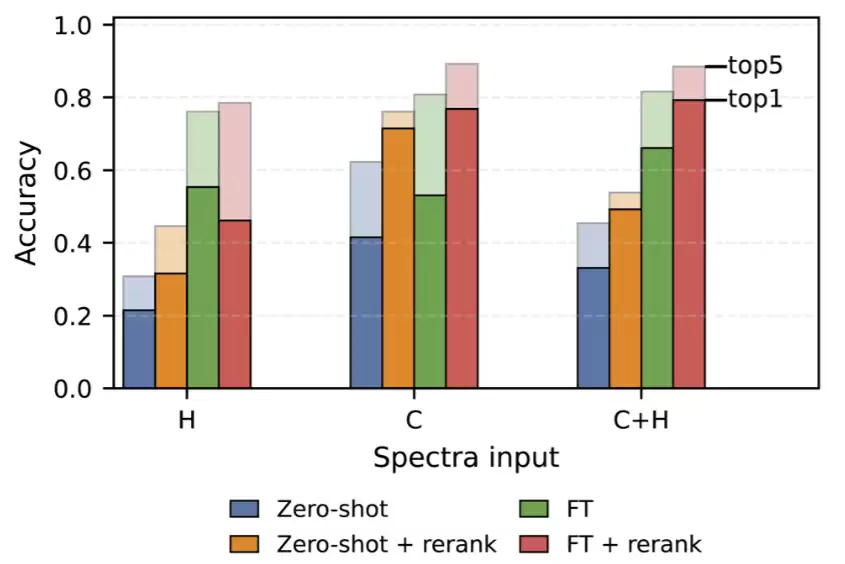
图4: 零样本迁移与实验微调性能比较。
化学位移重排序进一步提高候选结构筛选能力
研究者还设计了一种基于化学位移预测的重排序策略,对Transformer生成的候选结构进行“优中选优”。
实验结果表明,在零样本迁移场景下,该重排序操作能够持续提升Top-1和Top-5准确率。特别值得关注的是,仅使用¹³C谱时,加上重排序后的结果甚至超过了未经重排序的微调模型。
若干案例分析揭示了其中的奥秘:模型初始预测往往仅在官能团位置、芳环取代模式等局部细节上出现错误,而重排序借助化学位移信息,能够精准识别这些细微差别,将正确结构“提拔”到更靠前的位置。
即便最终未能完全恢复正确结构,经过重排序的候选结构通常也更接近真实分子的骨架,从而提升了最终结果的化学合理性和可解释性。
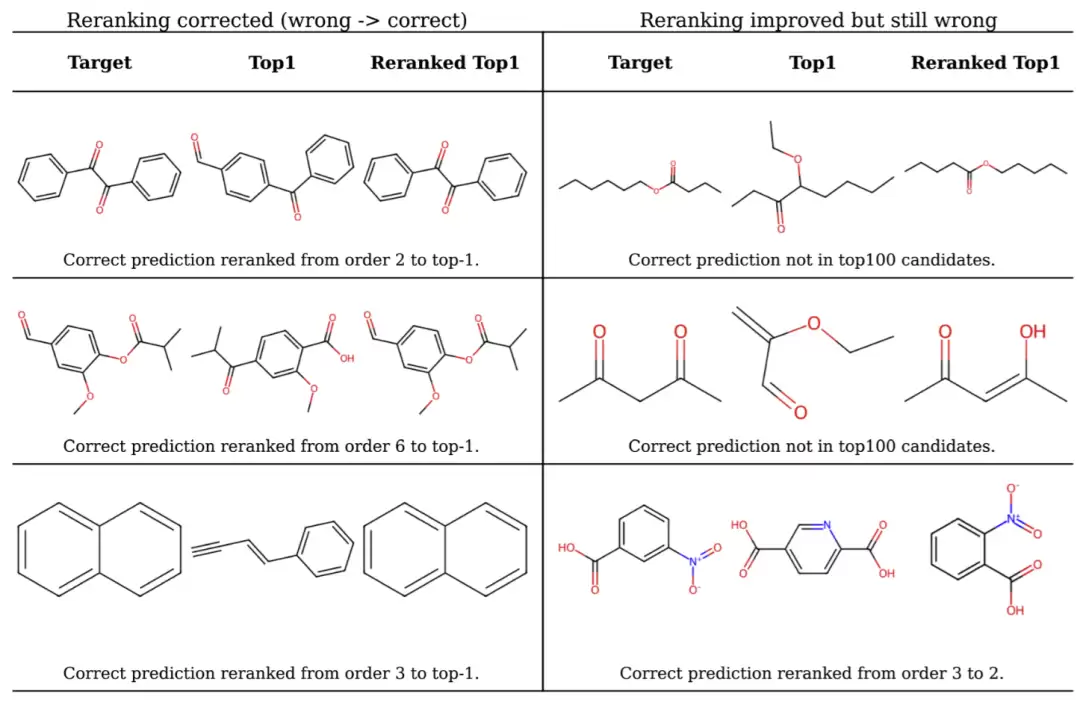
图5: 化学位移重排序前后结构预测结果比较。
二维HSQC谱图实现复杂代谢物结构预测
研究者还使用HMDB-HSQC实验数据集,专门评估了模型处理二维谱图的能力。
在零样本条件下,模型对重叠分子的Top-1准确率达到32.0%。虽然与模拟数据上67.97%的成绩尚有差距,但考虑到这是跨领域应用,已展现出不俗的迁移能力。随后利用少量实验数据进行微调,模型对未见过分子的Top-1准确率从16.7%跃升至45.8%。
从展示的预测案例来看,无论面对芳香体系、长链脂肪结构,还是复杂的多环骨架,NMRViT均表现出色。这说明它不仅能处理简单小分子,对于结构更复杂的代谢物同样游刃有余。
研究者认为,该框架未来具有广阔的拓展空间,有望进一步延伸至COSY、HMBC等更多二维NMR实验,最终实现真正意义上的多维谱图“一键解析”。
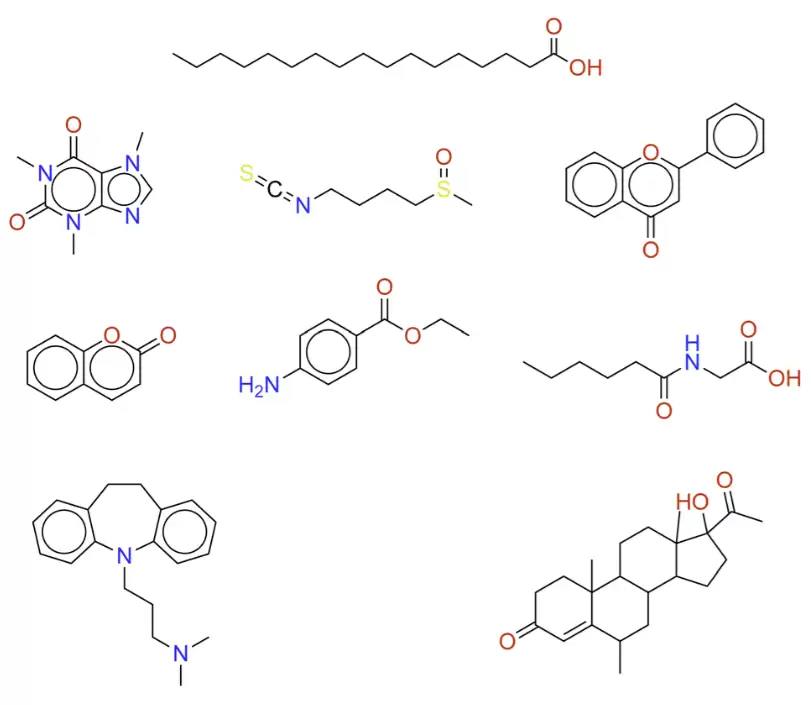
图6: HMDB-HSQC数据集上的结构预测结果与典型案例。
讨论
总而言之,本研究提出的NMRViT框架构建了一个基于Vision Transformer的端到端分子结构解析系统,实现了从原始NMR谱图直接到分子结构的自动化预测。与传统的先提峰再编码方法相比,NMRViT直接利用了完整的谱图信息,最大程度保留了谱学信号中的细粒度特征。
结果明确表明:多模态谱图融合能够显著提升结构解析能力,而二维HSQC谱则是解决结构歧义的“神兵利器”。当然,研究也揭示了模拟谱图与实验谱图之间明显的领域鸿沟,不过通过少量实验数据微调,再配合化学位移重排序,这两项操作足以有效弥补这一缺陷。
未来仍有诸多挑战:如何让模型对真实谱图的噪声和仪器差异更加鲁棒?如何构建更大规模的实验谱图库?如何将模型扩展至COSY、HMBC等二维谱学实验?随着自动化实验平台和AI实验室的不断演进,NMRViT这类模型极有可能成为闭环机器人化学平台中的核心分析模块,最终实现从“合成”到“表征”再到“结构解析”的全自动化流程。
参考资料
Han, C.; Pan, X.; Zhang, Y. End-to-end molecular structure elucidation from multimodal NMR spectra images using vision transformers. Chem. Sci. 2026. https://doi.org/10.1039/d6sc02352e





