晶体结构表征的精确度,是决定机器学习能否成功应用于大规模晶体材料模拟的关键门槛。核心难点在于——如何高效捕获晶体内部复杂的几何与拓扑特征?这恰恰是目前晶体性质预测领域最具挑战性的难题之一。近期,研究团队提出了一种多视角图Transformer模型(Multi-view Graph Transformer,MGT),该模型能够同时处理SE(3)不变标量表示和SO(3)等变方向表示,将平移旋转不变性与方向信息表达能力融入一个统一框架。更精妙的是,模型引入了一个受混合专家机制启发的路由器模块,使得两类几何表示能够根据具体任务实现自适应融合,加之多任务自监督预训练策略的运用,整体结构理解能力得到了显著提升。
测试成果相当突出:在多个晶体性质预测基准上,MGT相较现有最先进模型,最高能将平均绝对误差降低14%。消融实验与可解释性分析进一步证实,自监督预训练和专家路由机制均为切实有效的增强手段。在迁移学习任务中——例如催化剂吸附能预测和杂化钙钛矿带隙预测——MGT相比已有方法实现了最高58%的性能改善。这些数据表明,MGT具备出色的泛化能力与可扩展性,有望成为加速新型功能材料发现的重要工具。

晶体材料的应用范围极为广泛:能源存储、催化作用、药物研发、半导体设计——几乎每个硬科技领域都离不开它。而精确预测晶体材料的性质,正是新材料发现的核心环节。传统方法依赖密度泛函理论(DFT)计算和分子动力学模拟,但计算成本高昂,难以支撑大规模筛选。近年来,图神经网络发展迅速,研究人员相继推出了CGCNN、Matformer、PotNet等方法,利用晶体图结构来构建预测模型。
然而,这些模型也存在一个明显短板:过于依赖局部图结构,往往无法完整描述晶体的几何特征。不同晶体可能对应相同的图表示,这限制了模型的预测能力。为此,研究者开始引入SE(3)不变和SO(3)等变表示,通过显式考虑空间对称性来提升模型表达能力。像ComFormer这样的工作已经证明,两类表示均能有效提升预测性能。
问题在于,现有方法要么单独使用SE(3)不变表示,要么单独采用SO(3)等变表示,很少探索两者之间的互补优势。缺少一个统一框架来实现多视角几何信息的融合,这已成为制约晶体性质预测进一步发展的关键瓶颈。正是在这一背景下,MGT框架应运而生——通过联合建模两种几何表示,实现对晶体结构更全面的理解。
方法
MGT由两个图Transformer编码器和一个轻量级混合专家路由模块构成。一个编码器负责提取SE(3)不变几何特征——原子间距离和角度信息;另一个编码器学习SO(3)等变几何特征,通过球谐函数和张量积运算保留方向相关信息。两者提取的特征被送入一个基于自注意力机制设计的MoE-inspired路由器,由它根据具体任务动态调整两种表示的权重,实现任务自适应融合。
为增强泛化能力,研究人员还设计了一套多任务自监督预训练策略,包含去噪学习和对比学习两部分。去噪学习:给几何特征添加随机扰动后再恢复噪声,让模型对晶体几何结构更加敏感。对比学习:最大化SE(3)与SO(3)表示之间的互信息,促进两种视角特征的协同学习。预训练完成后,再通过监督学习完成下游的晶体性质预测任务。
结果
MGT在多个晶体性质预测基准上达到最优性能
研究人员在Materials Project和JARVIS两个主流晶体数据库上全面评估了MGT的表现,涉及九项性质预测任务——形成能、带隙、体模量、剪切模量、总能量以及稳定性等指标。与CGCNN、ALIGNN、Matformer、PotNet、ComFormer、ReGNet等先进模型相比,MGT在八项任务中拔得头筹,平均绝对误差降低幅度从2.1%到13.6%不等。唯一一次落后出现在JARVIS数据集的总能量预测任务上,略逊于ReGNet。
从预测结果来看,所有任务的R²均超过0.95,预测值与真实值高度吻合,说明模型拟合能力和稳定性都相当出色。多次随机种子重复实验进一步验证了结果的稳健性。
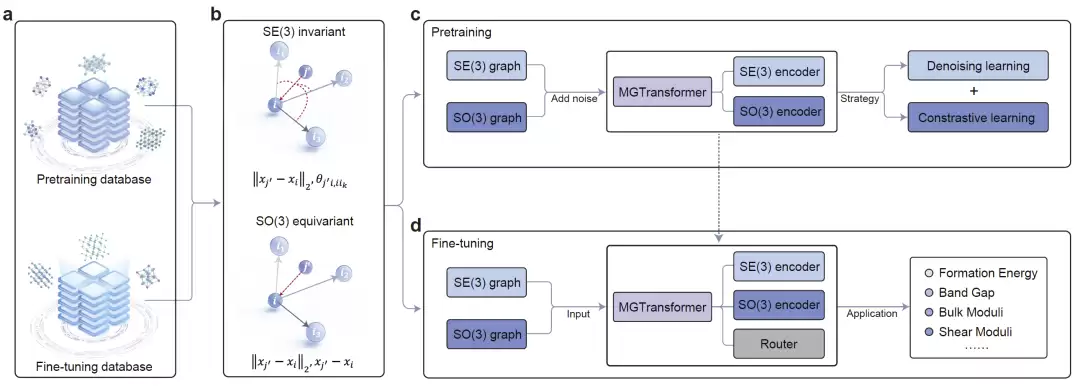
图1:多视角几何图Transformer(MGT)整体框架。
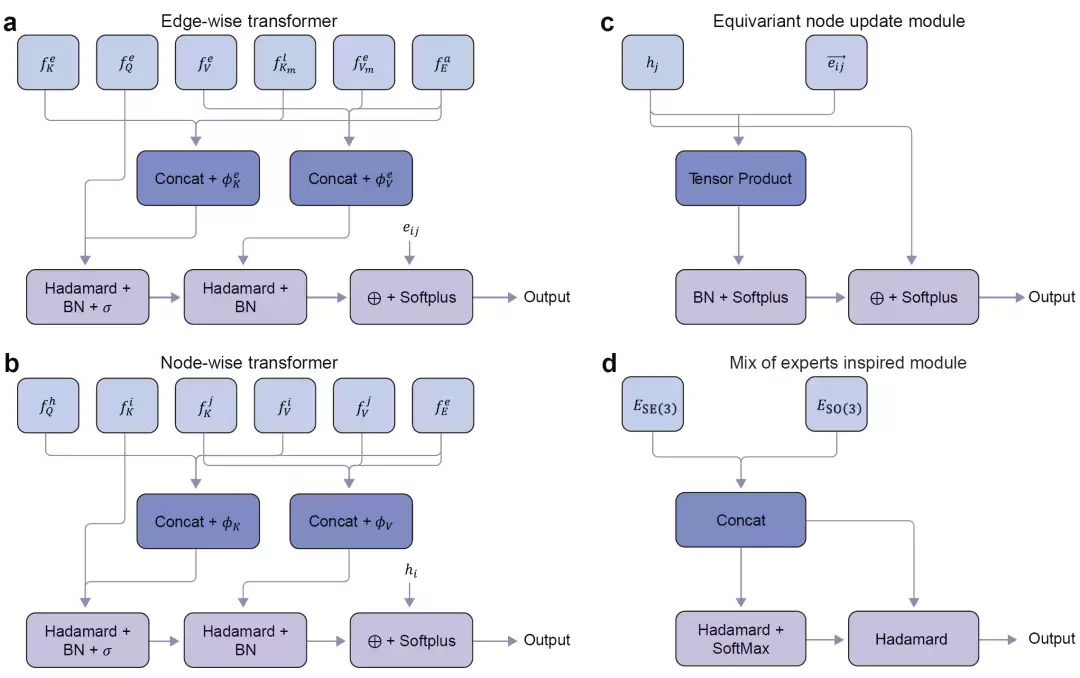
图2: MGT模型结构组成,包括SE(3)编码器、SO(3)编码器与MoE路由模块。
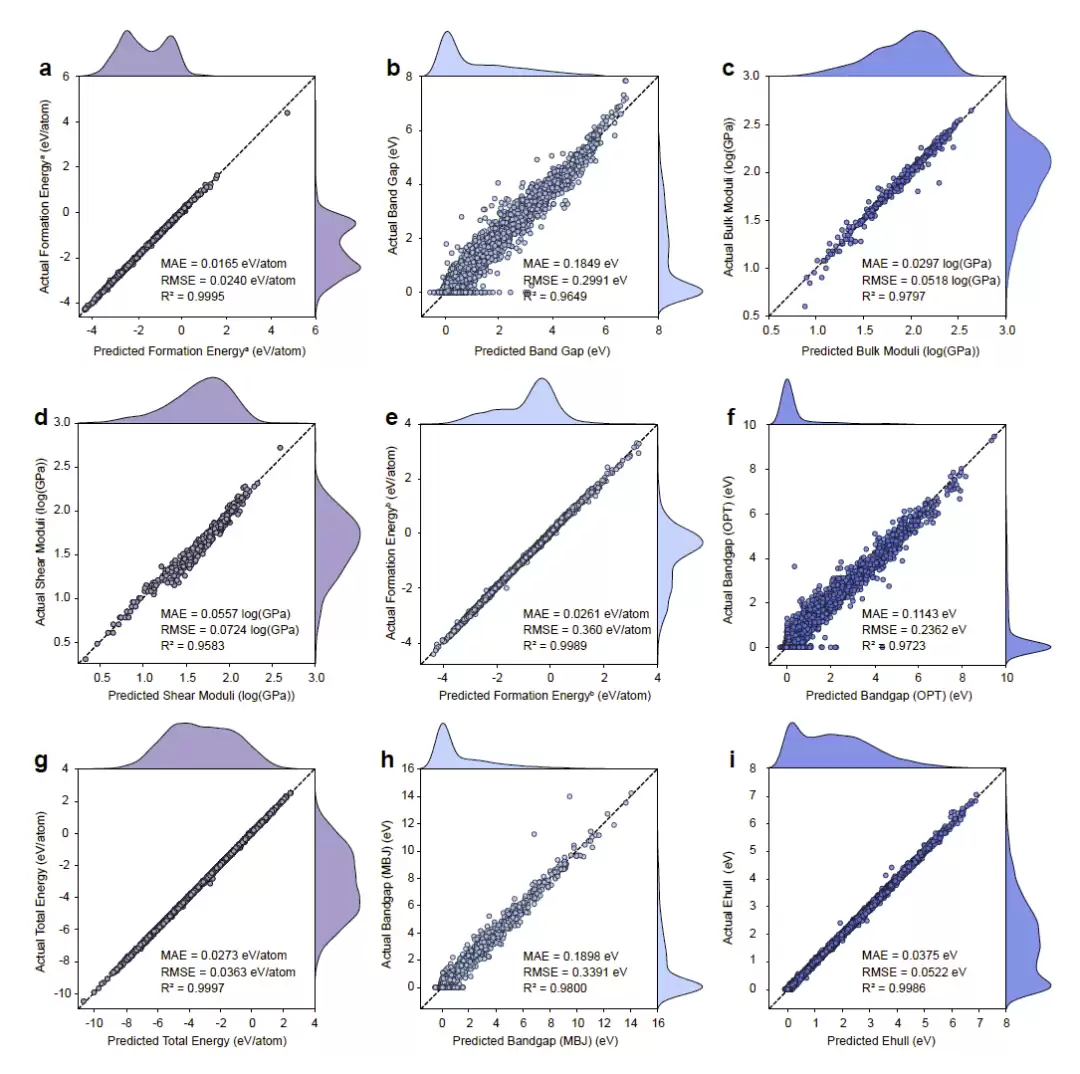
图3: MGT在Materials Project与JARVIS数据集上的预测性能比较。
自监督预训练显著提升模型性能
研究人员对比了有预训练和无预训练条件下MGT的性能。在Materials Project形成能预测任务中,采用预训练的MGT平均绝对误差为0.0165,从头训练则达到0.0174。差距虽不大,但趋势明确:预训练能帮助模型学到更通用、更有效的晶体结构表示。
进一步分析不同预训练策略发现,仅使用去噪学习就能带来明显提升;仅使用对比学习也有效果,但略逊于去噪学习。两者联合使用,性能最佳。研究者认为,去噪学习强化了模型对局部几何结构扰动的鲁棒性,对比学习则促进了不同几何视角之间的信息对齐,两者互补,共同提升了泛化能力。
MoE路由模块实现SE(3)与SO(3)特征的有效融合
为验证路由模块的价值,研究人员将其替换为一个简单的全连接网络。结果显示,引入MoE-inspired路由器后,无论在Materials Project还是JARVIS上,预测误差都进一步降低。例如在JARVIS形成能预测中,误差从0.0263降至0.0261;带隙预测中,从0.115降至0.114。提升幅度不算惊人,但足以说明动态权重分配机制能更有效地融合两种几何表示,让模型根据任务自动选择最有价值的信息来源。
更重要的是,即便移除预训练和路由模块,MGT仍然优于绝大多数现有模型——这证明多视角几何架构本身已具备较强优势。
可解释性分析揭示两种几何表示的互补作用
研究人员利用t-SNE对模型学习到的潜在表示进行了可视化。结果清晰显示:无论是SE(3)编码器还是SO(3)编码器,都能根据形成能将不同晶体材料聚类到不同区域。而经过MoE路由器融合后,聚类边界更加清晰,不同材料之间的区分度进一步提高。
进一步分析两类表示的贡献权重发现,不同预测任务对SE(3)和SO(3)特征的偏好差异明显。例如:
- 在形成能预测中,Materials Project更依赖SO(3)方向信息,而JARVIS则更依赖SE(3)标量信息;
- 体模量、带隙等任务中,两种表示往往表现出互补关系;
- 对于Ehull稳定性预测,由于本质上属于旋转和平移不变的能量性质,因此SE(3)表示贡献更大。
这些结果说明,不存在一种固定的最佳融合方式——不同任务需要不同程度地利用两种几何信息,这也正是动态路由设计合理性的最佳佐证。
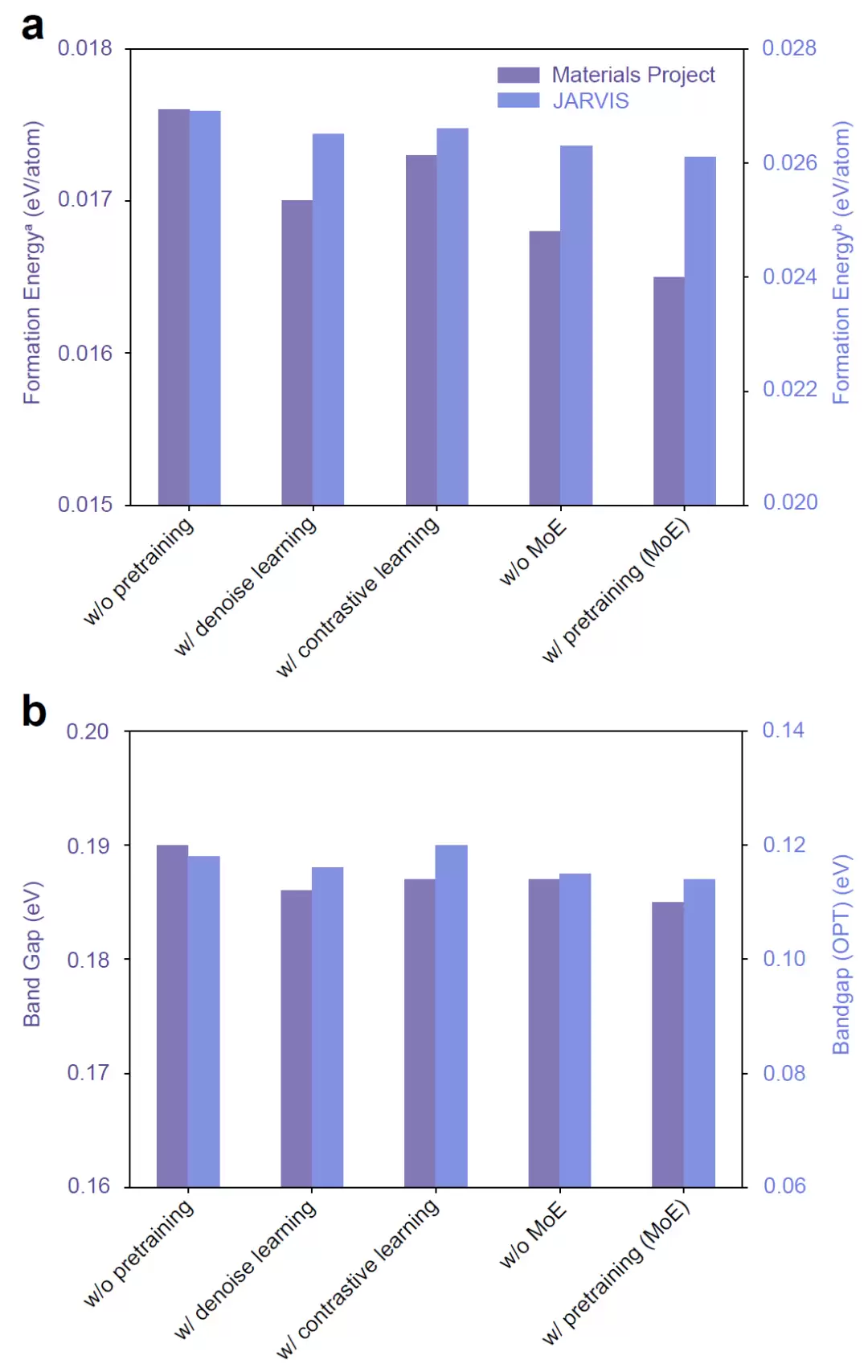
图4: 不同预训练策略和路由机制的消融实验结果。
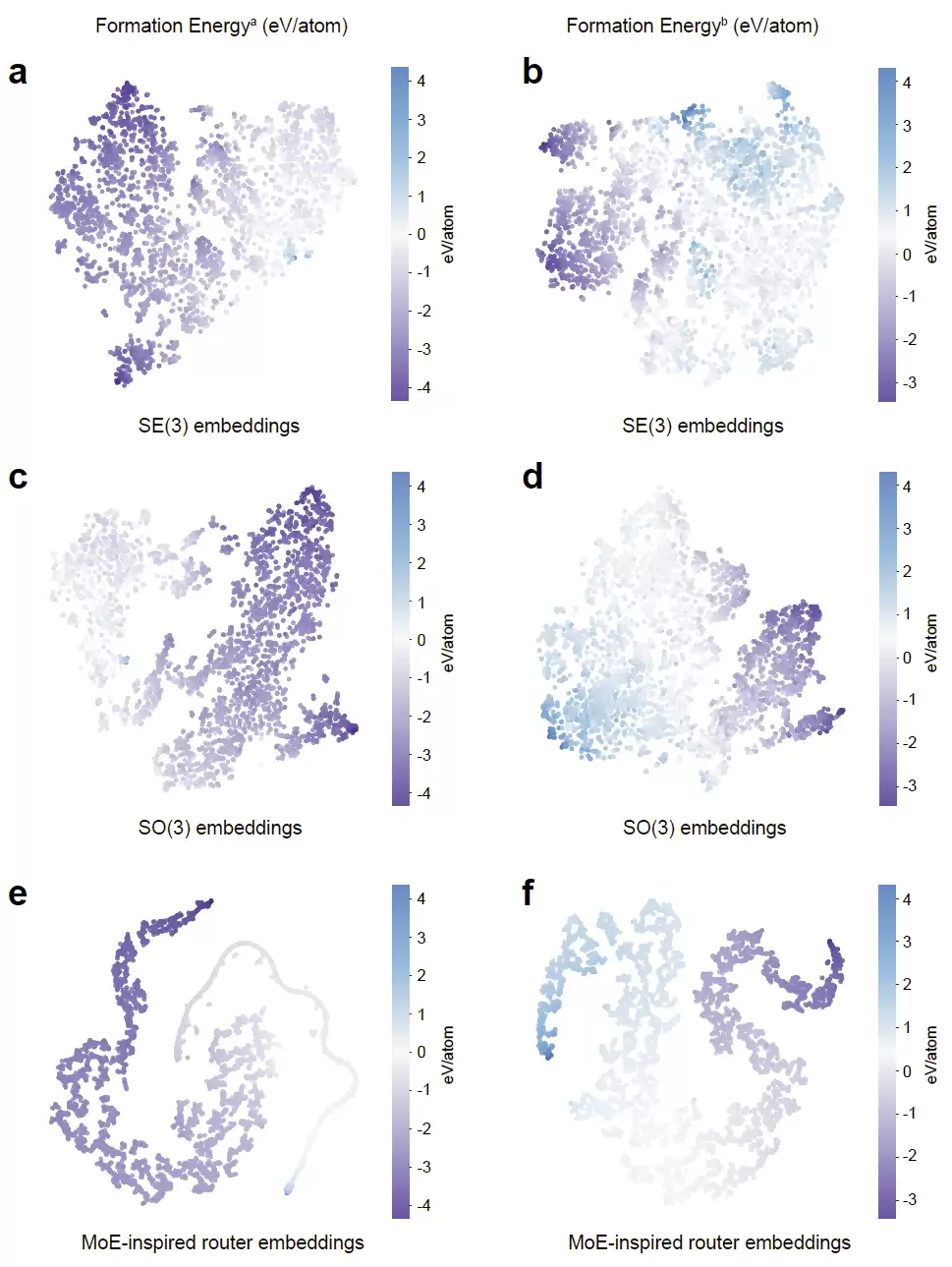
图5: MGT潜在空间可视化及SE(3)/SO(3)贡献分析。
迁移学习验证模型具有优异泛化能力
为检验MGT的实际应用价值,研究人员将其应用于两个迁移学习场景中。
第一个是催化剂全局最低吸附能(GMAE)预测。GMAE是评价催化剂表面反应活性的重要指标。MGT在Alloy-GMAE、FG-GMAE和OCD-GMAE三个数据集上全面领先,相比当前最先进模型AdsMT,性能提升分别达到46.4%、57.8%和15.4%。
第二个是杂化有机-无机钙钛矿(HOIP)带隙预测。带隙是决定太阳能电池和发光器件性能的关键参数。MGT在HOIP数据集上的预测误差比已有模型降低了25.7%。
这些结果说明,MGT不仅擅长标准晶体性质预测,在催化、能源材料等实际应用领域也具备很强的迁移能力。
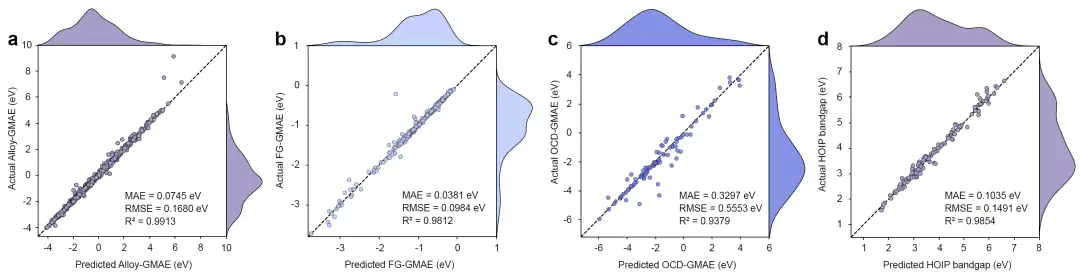
图6: MGT在催化剂吸附能与杂化钙钛矿带隙预测中的迁移学习表现。
讨论
研究人员提出的MGT,本质上是将SE(3)不变几何信息与SO(3)等变方向信息融合在一个多视角图Transformer框架中。双编码器结构、自监督预训练策略、动态专家路由机制这三驾马车,使模型能够同时学习晶体结构中的标量和方向特征,获得更完整的几何表示。
大量实验的结论高度一致:MGT在多个晶体性质预测基准上优于现有先进模型,并在催化剂吸附能和钙钛矿带隙预测等迁移学习任务中展现了优异的泛化能力。尤其值得关注的是,自监督预训练不仅提升了单项任务性能,还显著增强了跨任务迁移能力;MoE路由机制实现了SE(3)和SO(3)信息的动态融合,使模型能够针对不同性质自动选择最有效的几何特征。
当然,目前MGT主要关注静态晶体结构中的SE(3)与SO(3)对称性,尚未纳入空间群对称性、磁性对称性、时间反演对称性,以及温度和缺陷带来的无序效应。下一步的研究方向包括探索空间群等变消息传递、多保真主动学习框架,以及与扩散生成模型的结合,最终实现具有目标性质晶体材料的逆向设计——这将推动下一代功能材料的自主发现。
参考资料
Zhang, L., Wang, Z., Wang, X. et al. Improving crystal material property prediction with multi-view geometric graph transformer. Nat Commun (2026).
https://doi.org/10.1038/s41467-026-73627-7




