伴随着计算生物学与合成生物学的深度融合,抗体发现领域正经历一场深刻且影响深远的变革。机器学习若想真正颠覆抗体筛选的规则,其核心前提在于拥有结构清晰、质量过硬的高质量训练数据。在此需要明确一点:仅有出色的算法远远不够,能够与算法需求精准匹配的实验体系,才是决定成败的关键所在。
一项最新研究精准地切中了这一痛点。研究团队构建了一种合成Fab酵母展示文库,其设计思路从一开始就着眼于与机器学习流程的无缝衔接。核心策略是将序列多样性高度集中于重链的互补决定区——即CDRH3环上。在天然免疫系统中,这一环正是抗原识别的主力区域。研究人员从人类B细胞抗体库中提取关键序列特征,并将其压缩进一个紧凑的“抗原识别模块”(ARM)中。基于VH1-69重链和四种轻链,该文库对PD-L1、TIGIT、ROBO1等十种细胞表面抗原进行了实战验证。结果令人振奋:不仅获得了数百个生物物理特性优异的抗体,还通过流式细胞术、免疫组化等实验方法进行了验证。更重要的是,研究团队直接从海量测序数据中,利用机器学习模型挖掘出了针对ROBO2和PD-L2的全新抗体。整个公开数据集,本质上构建了一个适用于机器学习的高通量抗体发现框架。

抗体展示技术在寻找高质量抗体方面的价值,业内早已形成共识。在某些应用场景下,其筛选出的候选分子甚至能与传统免疫方法获得的单克隆抗体相媲美。无论是酵母展示还是噬菌体展示,其核心优势在于能够对大量候选分子进行“饱和式”筛选。而纯合成展示文库最大的亮点,在于其流程的可控性、稳定性与可重复性——这对于构建“计算-实验”闭环体系而言,几乎是不可或缺的前提条件。传统免疫法在面对神经系统或发育过程中的高度保守抗原时常常力不从心,而合成文库则能轻松绕过这一天然障碍。
然而,当前许多用于治疗性抗体开发的先进文库,其结构往往较为复杂。它们通常依赖患者或动物来源的多种CDR组合,并叠加多种筛选技术,这虽然拓展了抗体序列空间,但数据结构的复杂度也随之急剧上升,这恰恰为大型机器学习模型训练数据集的构建设置了不小的障碍。
回到天然免疫识别机制本身,重链CDRH3环在决定抗原特异性方面扮演着举足轻重的角色,是整个互补位结构的核心区域。因此,一个自然而然的设想便应运而生:如果将互补位的主要序列空间从六个CDR压缩到仅剩一个CDRH3,那么抗原-抗体相互作用的语言是否会变得更为简洁、有序,从而更适合计算建模?这一思路并非首创,此前已有合成文库进行过尝试,但它们多采用固定的随机氨基酸频率,结果引入了大量在天然体系中本应被B细胞选择过程清除的不良基序,例如多反应性、易聚集或易降解的氨基酸。
这正是本项研究设计的出发点。他们构建的合成Fab酵母展示文库,其巧妙之处在于:在CDRH3区域引入的是来自初始B细胞抗体库的位置特异性氨基酸频率,同时清除了那些“有害”基序。每个CDRH3序列之后还附上了一个核苷酸层面的条形码,用于追踪其匹配的轻链类型。这个完整的“CDRH3+轻链条形码”结构,即为ARM。由于ARM本质上是一段超短核苷酸序列,天然适合深度测序,可作为抗体互补位的一种紧凑表示形式。研究团队利用这套系统筛选了十个具有生物学和治疗价值的细胞表面抗原,并结合大规模测序与机器学习,旨在挖掘那些低频但潜力巨大的Fab克隆。
方法
具体实施步骤如下:首先,从人类初始B细胞抗体库中“临摹”出CDRH3的序列空间,并剔除那些可能引发问题的基序。接着,以VH1-69重链作为固定支架,搭配四种轻链,构建起携带紧凑ARM的合成Fab酵母展示文库。随后,针对十种细胞表面糖蛋白抗原,通过磁珠分选结合多轮流式分选进行逐步“筛选”。每一轮筛选后,均对ARM区域进行深度测序,实时追踪候选Fab克隆的富集动态。最后,根据CDRH3序列进行聚类分析,选出代表性克隆,表达为IgG1或兔嵌合抗体,并使用一整套分析手段进行验证:尺寸排阻色谱评估聚集情况,多特异性反应检测非特异性结合,表面等离子体共振测定动力学参数,流式细胞术和免疫组化评估应用潜力。更为关键的是,对于那些在实验筛选中被“埋没”的克隆,他们利用基于k-mer特征的逻辑回归模型,从早期分选数据中重新识别出来。
结果
ARM的设计与序列分析
为了搭建一个既适合高通量筛选又适合机器学习分析的平台,研究团队的核心发明就是ARM。它覆盖了CDRH3及其邻近框架区,并附加了一个轻链条形码。由于序列较短,深度测序的效率极高,天然成为抗体识别特征的理想编码形式。
他们为长度在11到17个残基之间的CDRH3设计了不同的寡核苷酸池,每个位置的氨基酸频率均来源于Observed Antibody Space数据库中的初始B细胞序列。为确保多样性不被扭曲,特意调整了不同长度序列的比例;同时,主动排除了半胱氨酸、甲硫氨酸以及其他可能带来不良性质的基序。
展示支架选择了VH1-69,这是一个在治疗性抗体和广谱中和抗体中广泛使用的重链胚系基因。四种轻链的选择也颇具匠心:VK1-39、VK3-15和VK3-20能形成相对平坦的互补位表面,而VK4-1因其CDRL1环较长,可形成更凹陷的表面,可能识别不同类型的表位,例如肽类表位。深度测序结果证实,两个VH1-69子文库检测到了海量独特的CDRH3序列,各子文库之间重叠度很低,各自贡献了丰富的多样性。总体而言,这个ARM文库的氨基酸频率很好地再现了天然初始B细胞库的特征,同时有效去除了不良基序。
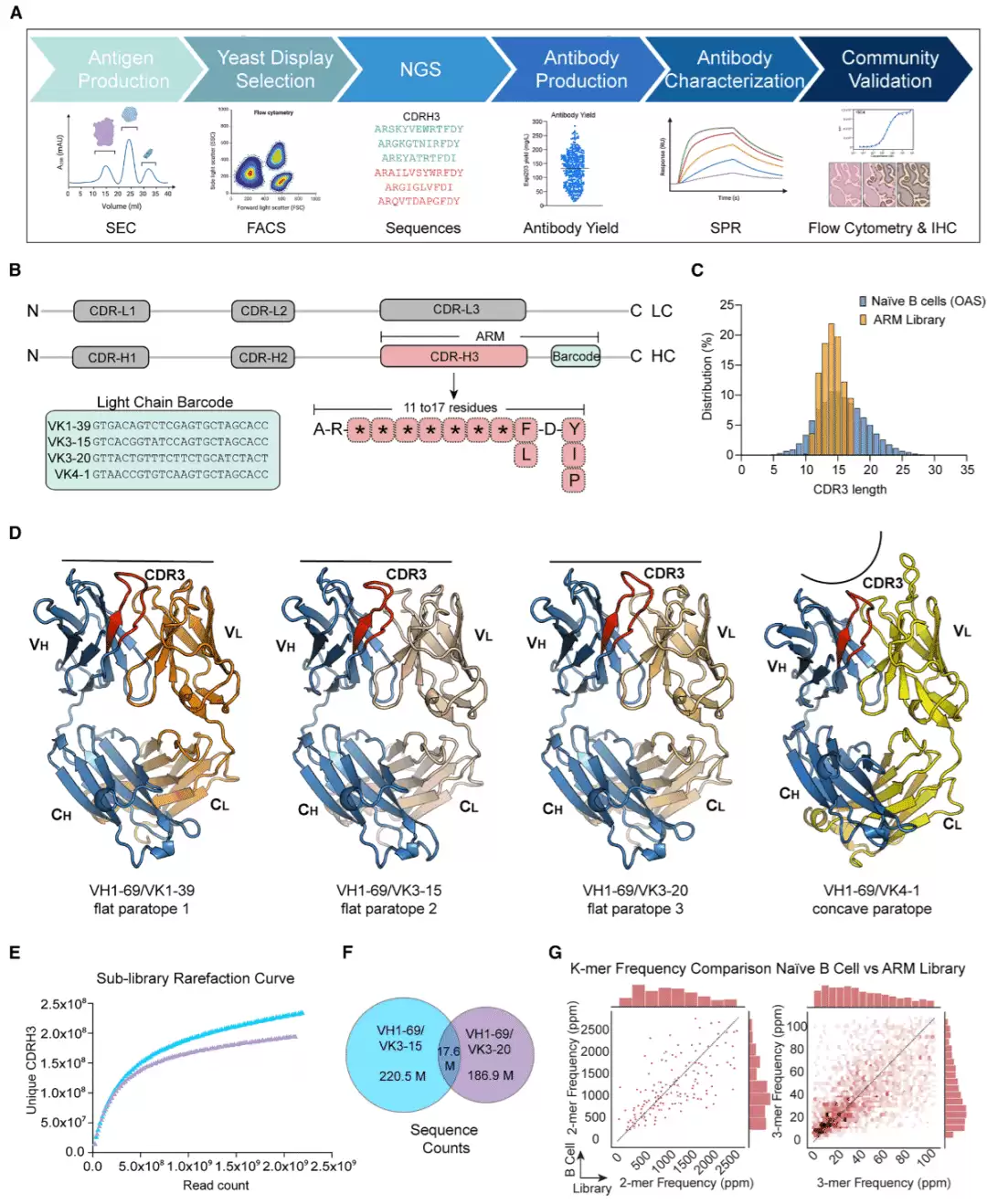
图1:用于 Fab 酵母展示的 ARM 文库构建。
高通量抗体发现流程成功产出丰富候选分子
为了检验这个最小化Fab文库的真实筛选能力,研究团队同时向十个靶点发起挑战:PD-L1、PD-L2、TIGIT、LOX1、DKK1、IL-23R、DCC、ROBO1、ROBO2和syncytin-2。这些抗原在大小、序列相似性和结构类型上差异显著,足以全面检验文库的性能。筛选流程包括一轮磁珠分选加三轮流式分选,全程逐步降低抗原浓度,以施加压力筛选强结合群体。每一轮筛选后,均对ARM区域进行深度测序,动态追踪每个CDRH3克隆的命运。
根据最终轮次中频繁出现的ARM序列,对CDRH3进行聚类,并订购了代表性重链。由于插入片段较短,成本优势十分明显。最终订购了429条重链,获得了424个产量合格的抗体。质量控制结果显示:301个抗体无聚集或降解问题,354个无多特异性反应,共有285个抗体双通过。后续的动力学和细胞结合实验进一步筛选出一批性能优异的候选分子,部分针对TIGIT和LOX1的抗体表现甚至与商业抗体相当。针对ROBO1/2和syncytin-2的优选抗体,其热稳定性也令人印象深刻。
一个特别亮眼的例子是ROBO1和ROBO2。这两个轴突导向受体,目前高质量的商品化IHC抗体非常稀缺。尽管筛选使用的是人源抗原,但部分抗体对小鼠同源蛋白也表现出强烈的交叉反应。经过抗体工程改造后,在小鼠胚胎组织切片上,这些抗体产生的免疫染色模式与已验证的商业抗体高度一致,有力证明了这个文库不仅能筛选出“结合”抗体,更能产出经得起实际生物学实验检验的高质量试剂。
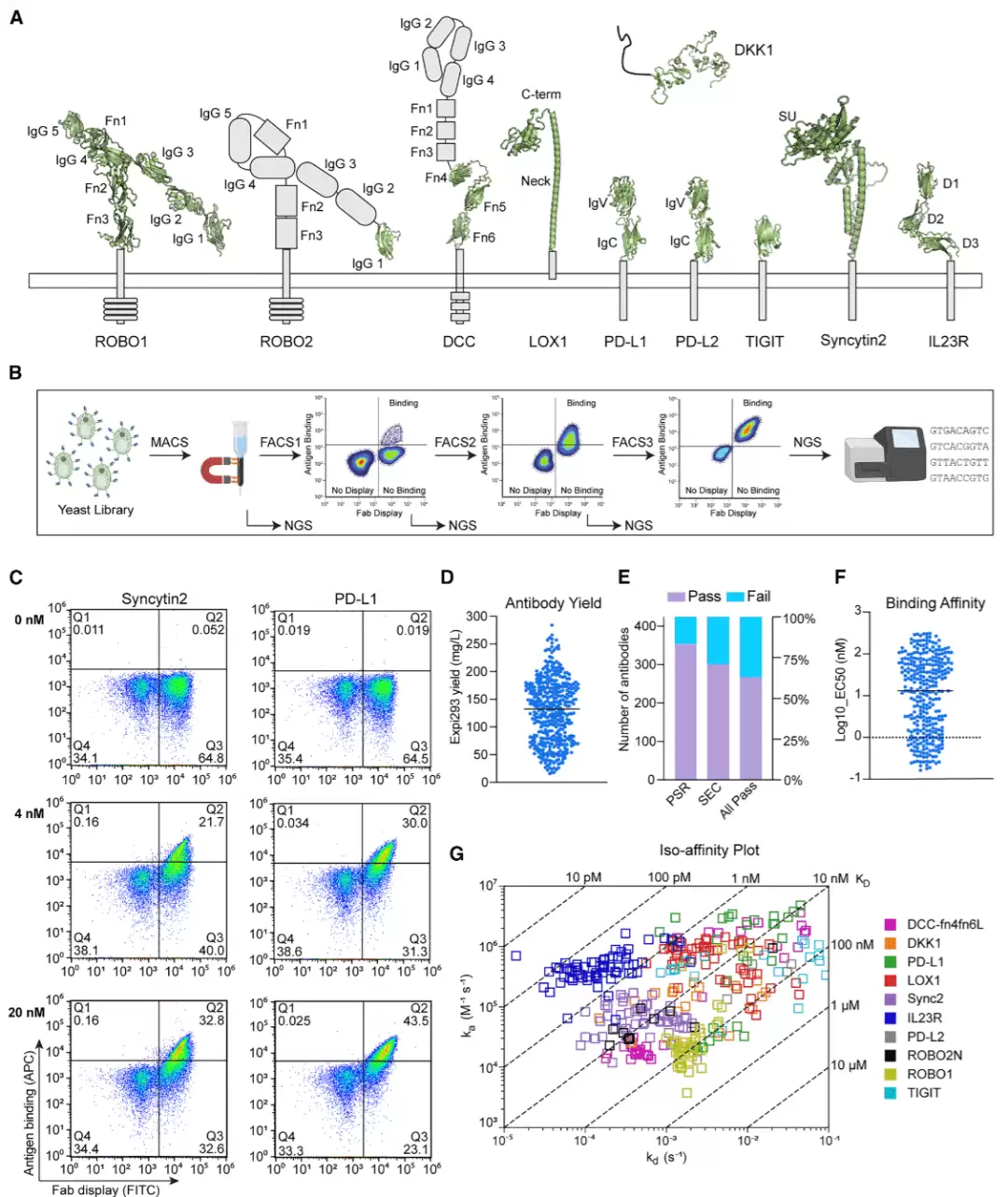
图2:针对十种细胞表面糖蛋白的抗体发现活动。
深度测序揭示文库的稳健性与特异性
深度测序数据清晰地展示了抗原驱动的富集模式。例如,针对IL-23R的一个富集聚类,其CDRH3环的基部序列高度一致,而环顶部则保留变异,说明文库能在同一骨架下产生功能相似的多种结合模式。对于高度同源的ROBO1和ROBO2N,独立筛选得到的ARM序列聚类几乎相同,表明文库在识别保守表位时,会自然收敛到相似的解决方案。与此同时,不同抗原的筛选又展现出高度特异性——随着筛选轮次推进,聚类数量逐步减少,而每个聚类内部的序列数量在增加,这说明筛选过程并非随机放大,而是真正的抗原驱动选择。
跨抗原的序列相似性分析也印证了这一点。PD-L1和PD-L2虽然结构相似,但外结构域序列相似性有限,最终筛选出的CDRH3序列几乎没有重叠。而ROBO1和ROBO2N则因共享保守表位,筛选结果呈现明显相关性。整体结果显示,ARM文库能根据抗原表面特征,产生可重复、稳健且具有抗原驱动性的序列富集。
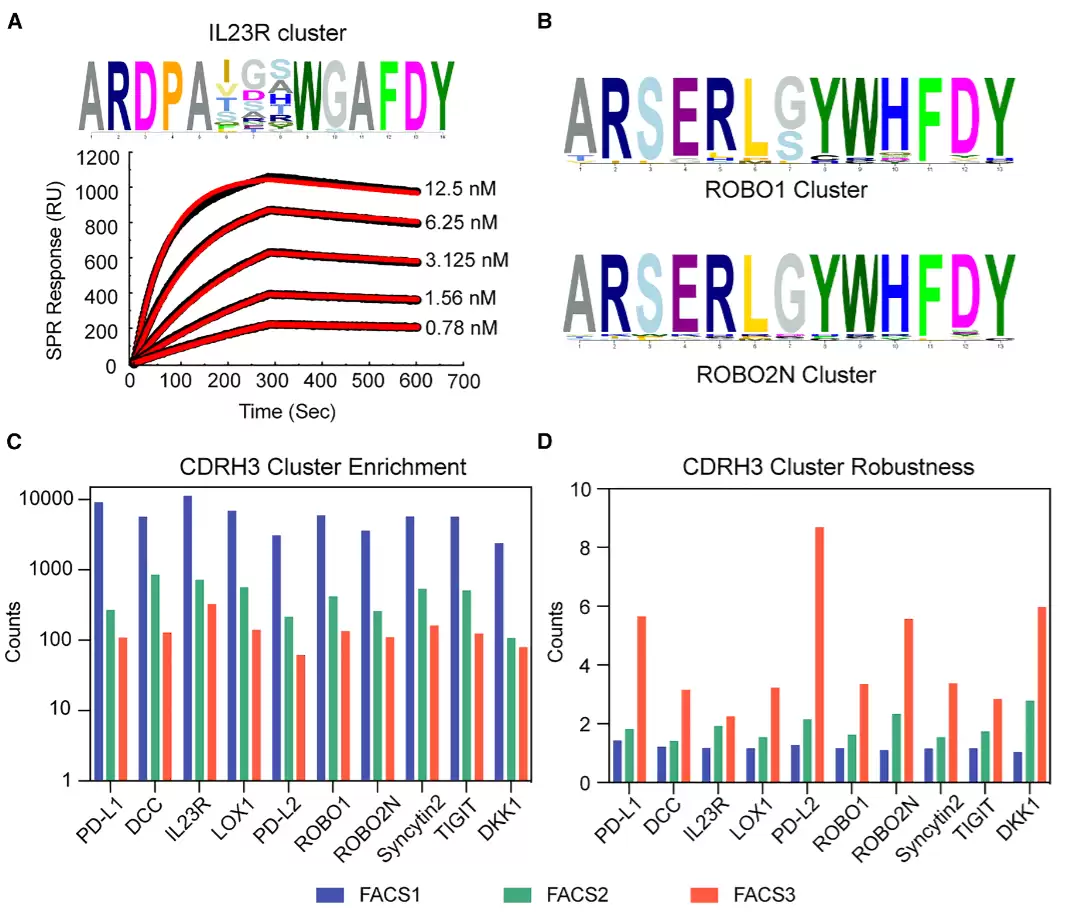
图3:抗原驱动的序列富集显示稳健且独特的 CDRH3 序列模式。
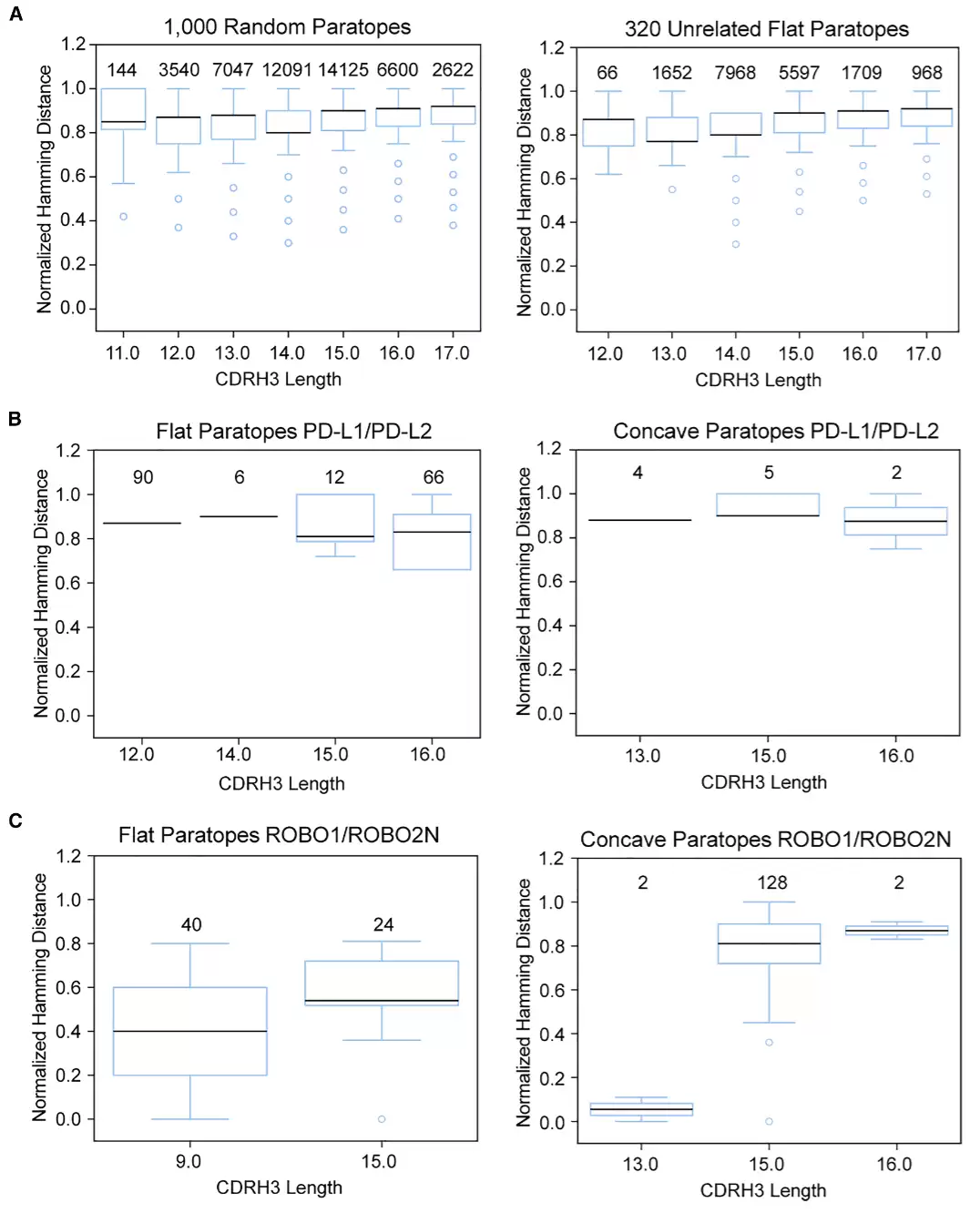
图4:使用归一化汉明距离评估不同抗体筛选活动之间的序列多样性。
机器学习的介入:弥补实验筛选的“盲区”
实验筛选虽然高效,但并非十全十美。有些克隆可能因展示效率、生长速率甚至筛选动力学上的细微差异,在后续轮次中被低估或丢失。在ROBO2N的筛选中,研究团队发现最终轮次被一个优势克隆主导,而早期轮次里还隐藏着丰富的ARM多样性。正是针对这一痛点,机器学习开始大显身手。
他们针对ROBO2N的数据训练了一个逻辑回归模型,以ARM序列中的k-mer频率作为特征。模型的训练目标是区分相对于磁珠分选,在第一轮流式分选中是否出现富集。经过充分训练和评估后,他们用模型对第一轮流式分选中具有足够计数的1909个ROBO2N ARM进行评分,从中选出了29个模型评分很高、但在后续实验中被“埋没”的ARM序列。为确保这些候选与已发现的抗体不同,还特意要求它们保持足够的序列编辑距离。
将这些机器学习选出的ARM重新表达为抗体后,通过表面等离子体共振和细胞展示检测,结果令人振奋:排名靠前的机器学习抗体,大部分结合动力学表现优异,甚至优于实验筛选中占优势的短CDRH3克隆。多个抗体成功结合ROBO2,且对ROBO1有交叉反应,对PD-L1等阴性对照则无反应。更进一步,通过表位分箱分析,机器学习选出的两个抗体还能同时结合ROBO2N,说明它们识别了不同的表位,成功拓展了实验筛选获得的表位空间。他们还尝试将基于ROBO2N训练的模型,直接用于预测ROBO1上哪些抗体更可能结合——模型给出的高分,精准指向了那些识别共享N端表位的抗体。这一结果相当出色:机器学习不仅能“抢救”被实验流程忽略的克隆,还能在同源抗原之间,预测出共有的结合模式。
同样的策略也被应用于PD-L2的筛选。原始实验只获得了少数良好抗体。通过逻辑回归模型从早期数据中重新选择,他们发现的候选抗体,在细胞结合效力上毫不逊色。ROBO2N和PD-L2的例子共同证明,深度测序产生的ARM数据集中,隐藏着大量未被传统分选流程充分利用的信息。
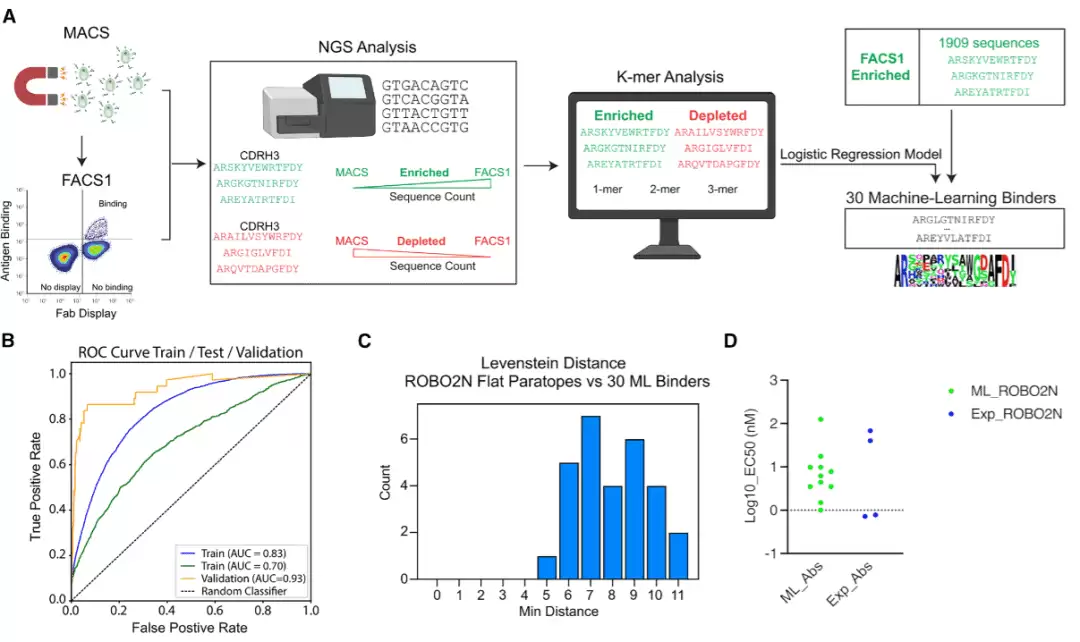
图5:逻辑回归模型从早期分选群体中“抢救”被动力学细胞分选丢失的 ROBO2N 结合抗体。
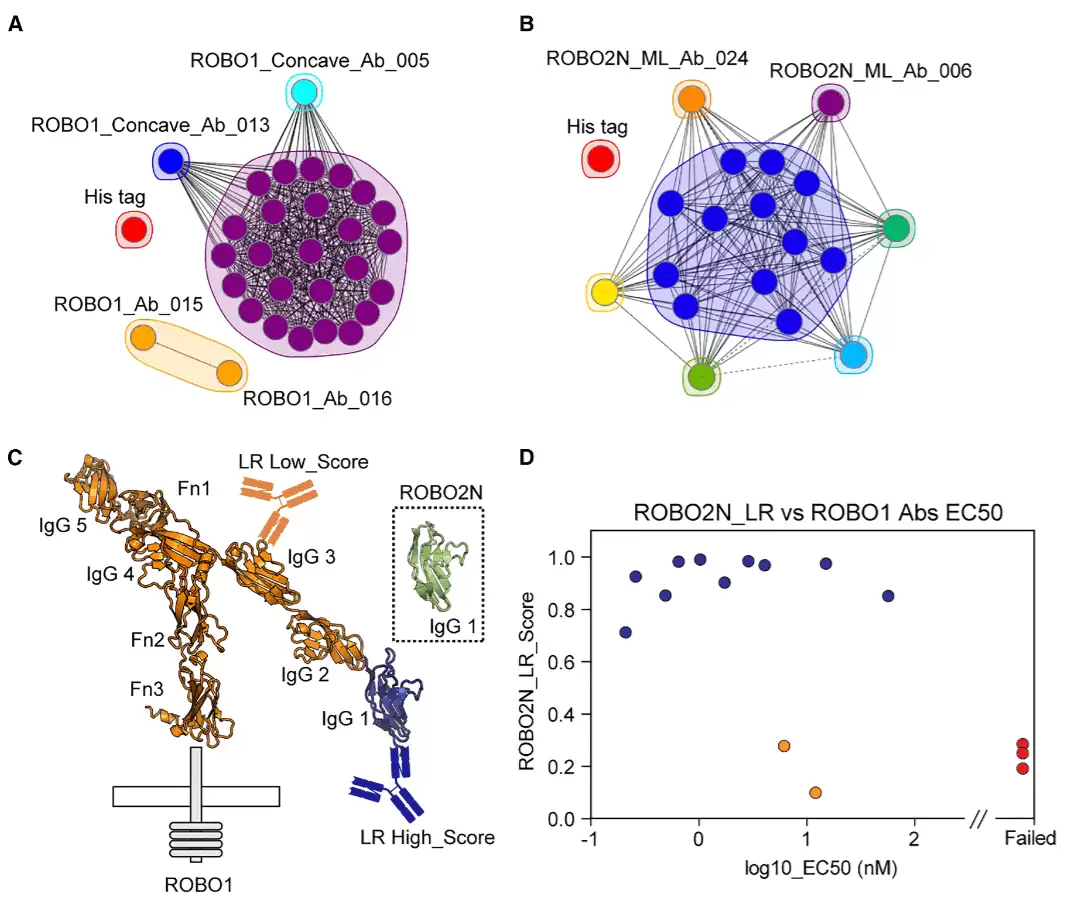
图6:利用逻辑回归模型进行交叉反应抗体的表位分箱与评分。
讨论
必须承认,机器学习在蛋白质结构预测方面已取得令人瞩目的进展,但在抗体-抗原相互作用的从头预测上,依然面临挑战,尤其是在缺少高质量结构数据和大规模互作数据的情况下。合成抗体文库为机器学习生成系统化数据集提供了绝佳路径,但以往文库的序列空间过于复杂,反而成为障碍。ARM文库通过将主要多样性集中于CDRH3,大幅压缩了互补位序列空间,使其变得可追踪、可学习。
从十个不同抗原的测试结果来看,这种设计无疑是成功的。文库既保证了筛选的稳健性,又能产生抗原特异性识别模式。同时必须指出的是,细胞分选有其局限性,最终富集的克隆不一定总是最优的。而ROBO2N和PD-L2的结果,恰好证明了“计算-实验”混合策略的价值:早期分选轮次保留的大量信息,可以通过机器学习重新激活,让那些低频但有潜力的抗体也能进入后续验证。这种策略,有效缓解了实验中克隆丢失和富集偏倚的问题。
表位分箱实验中的一个有趣发现是,ROBO1和ROBO2N上存在抗体识别的“热点”区域,多数抗体集中于此。这可能反映了抗原本身存在优势结合表面,但也可能与文库设计有关——由于只主要改变CDRH3,固定了CDR1和CDR2,一定程度上限制了依赖其他CDR多样性的互补位类型。这也提示我们,未来要覆盖更广泛的表位空间,或许需要引入更多支架或适度扩展其他CDR区域的多样性,同时保持一个可学习的紧凑体系。
这项研究一个最值得称道的贡献,是公开了大规模下一代测序数据和数百个抗体的实验表征结果。这些数据不仅服务于当前的筛选,更为未来的计算模型——无论是表位分箱、亲和力成熟、抗体排序还是零样本发现——提供了宝贵的训练语料。随着更多抗原、支架和实验标签的加入,类似ARM的紧凑抗体表示,完全有潜力成为机器学习驱动抗体发现的核心数据接口。
总的来说,研究团队构建并验证了一套可扩展的高通量抗体发现框架,成功地将合成Fab展示、深度测序、生物物理表征和机器学习筛选融为一体。它既能针对多种细胞表面抗原快速产出高质量抗体,又能借助机器学习的力量,从实验筛选的“盲区”中发现惊喜。这项工作不仅为抗体发现提供了一个“实验-计算”闭环的生动范例,也为面向大规模抗体设计模型的数据集建设,铺设了一块坚实的基石。




