动态主题模型(Dynamic Topic Models)——追踪主题随时间演变的概率时间序列模型
摘要
随着电子文档档案的爆炸式增长,自动组织、搜索与索引技术面临着前所未有的挑战。本文提出了一系列概率时间序列模型,专门用于分析大型文档集合中主题的演化规律。核心思路简洁明了:在表示主题的多项分布自然参数上,引入状态空间模型来描述时间动态。为解决推断难题,我们设计了基于卡尔曼滤波与非参数小波回归的变分近似方法,从而实现对潜在主题的近似后验推断。除了构建定量预测模型,动态主题模型还提供了一个定性视角,让人们直观地观察大型语料库中内容的变迁。作为验证,我们对《科学》(Science)杂志1880年至2000年经OCR处理的档案进行了分析,结果令人信服。
1. 引言
面对电子文档档案的快速增长,传统手动管理方式早已难以应对。近期机器学习与统计学的研究成果,开发了基于层次概率模型的新技术,能够在文档集合中自动发现词语模式——这些模型被称为“主题模型”。为何如此命名?因为发现的模式往往对应着构成文档的潜在主题。这类模型灵活性极强,已被推广到图像、生物数据和调查数据等多个领域。
在传统的可交换主题模型中,假设每个文档中的词语是从多项分布的混合中独立抽取的。混合比例每篇文档随机抽取,而混合分量(即主题)由所有文档共享。这样的设计对大型非结构化文档集合是一种强大的降维工具,文档级别的后验推断在信息检索、分类和主题浏览中同样极具价值。但问题在于,将词语视为可交换的,虽然简化了问题,却忽略了文档顺序所蕴含的时间信息。对于诸多集合——如学术期刊、电子邮件、新闻文章、搜索查询日志——内容本身便随时间演变。以《科学》杂志为例,1903年关于“Laborde教授的大脑”的文章,与1991年关于“皮层运动图重塑”的文章虽同属神经科学,但研究范式与语言风格差异巨大。因此,明确对潜在主题的动态进行建模具有重要意义。
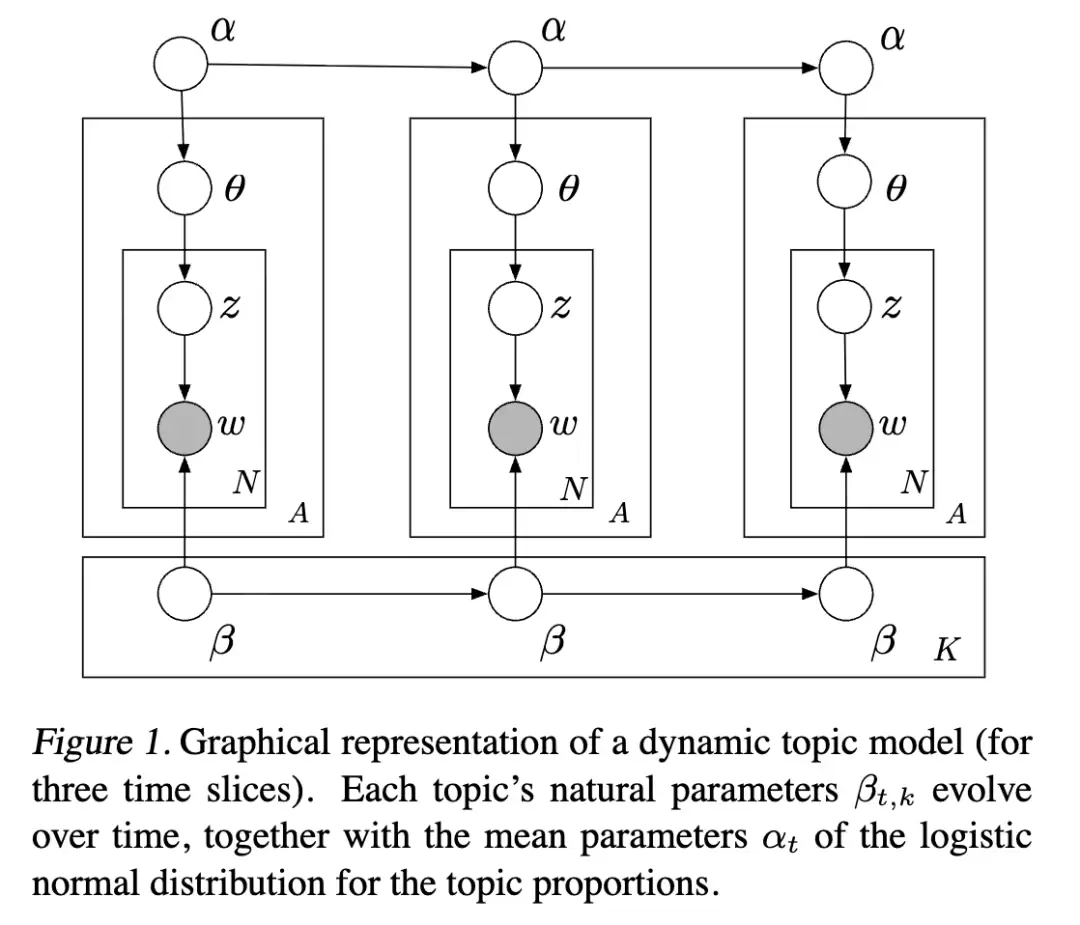
本文提出一种动态主题模型,能够捕捉按时间顺序组织的语料库中主题的演变。我们以《科学》杂志100多年的OCR文档数据来验证该模型。该杂志由爱迪生于1880年创办并持续出版至今。在模型设计中,文章按年份分组,每年的文章均源自上一年的主题演化而来。
后续结构如下:第2节扩展经典的状态空间模型,建立主题演变的统计框架;第3节开发高效的近似后验推断技术,从顺序文档集合中推断出不断演变的主题;第4节展示定性结果,证明动态主题模型如何让大型文档集合的探索更具趣味性,同时呈现定量结果——相比静态主题模型,它在预测精度上表现更优。
2. 动态主题模型
传统时间序列建模通常针对连续数据,而主题模型是为分类数据设计的。我们的做法是在潜在主题多项式的自然参数空间以及文档特定主题比例(对数正态)的自然参数空间上,运用状态空间模型。

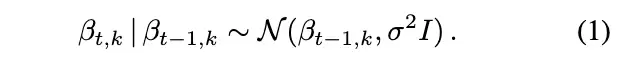
简而言之,我们通过动态模型将高斯分布链式连接,再将生成的值映射到单纯形,从而对成分随机变量序列进行建模。这实际上是逻辑正态分布在时间序列单纯形数据上的扩展(Aitchison, 1982; West and Harrison, 1997)。


3. 近似推断
在自然参数上使用时间序列模型,好处是可以利用高斯模型描述时间动态;但坏处在于高斯模型与多项分布模型之间存在非共轭性,导致后验推断十分棘手。这里我们提出一种变分方法来进行近似后验推断。之所以选择变分而非随机模拟,是因为文本分析中的数据集通常规模庞大,变分方法提供了一套确定的替代方案。尽管吉布斯采样在静态主题模型中效果良好,但非共轭性使得采样方法在动态模型中推进困难。



3.1. 变分卡尔曼滤波

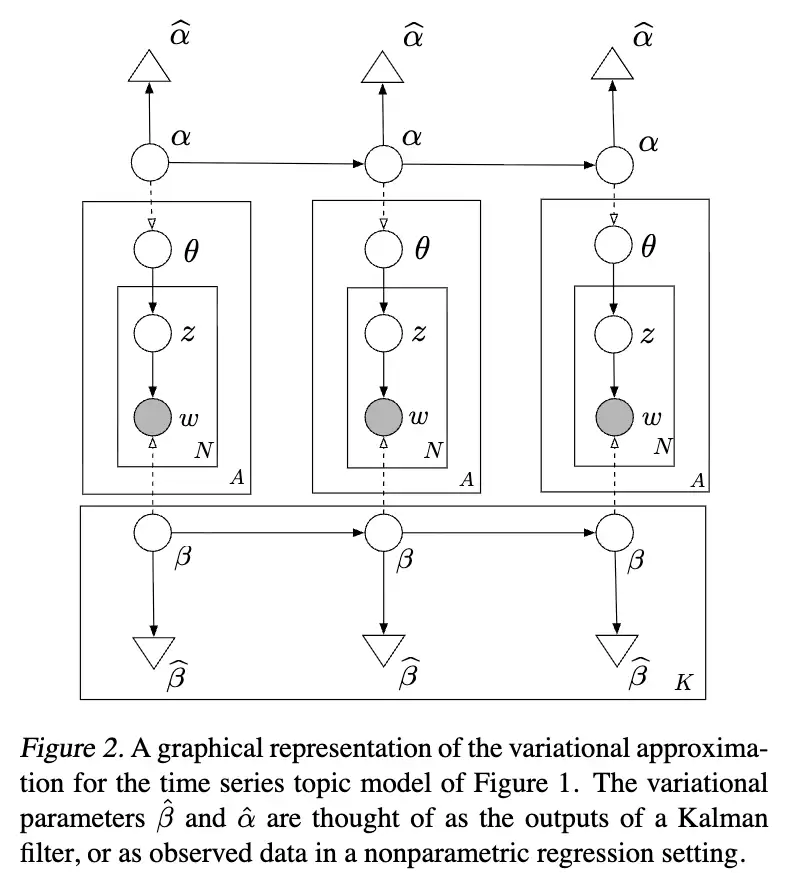

3.2. 变分小波回归


图3展示了运行上述算法和卡尔曼变分算法,对一元语法模型进行拟合的示例结果。两种变分近似都平滑了一元语法计数中的局部波动,同时保留了可能表明期刊内容发生显著变化的尖锐峰值。虽然拟合结果与使用标准小波回归对归一化计数的拟合相似,但这里的估计值是通过最小化KL散度得到的——这与标准变分近似的做法完全一致。
在第2节的动态主题模型中,算法内核与上述描述类似。区别在于,我们不是根据真实观测计数来拟合观测值,而是根据公式(3)中文档级变分分布下的期望计数来进行拟合。
4. 《科学》杂志的分析
我们分析了来自《科学》杂志的30,000篇文章子集,覆盖了1881年至1999年这120年间,每年250篇文章。数据由JSTOR收集——这个非营利组织通过对原始印刷期刊运行OCR引擎,维护了一个在线学术档案库。JSTOR对生成的文本建立索引,并通过关键词搜索提供对原始内容扫描图像的在线访问。
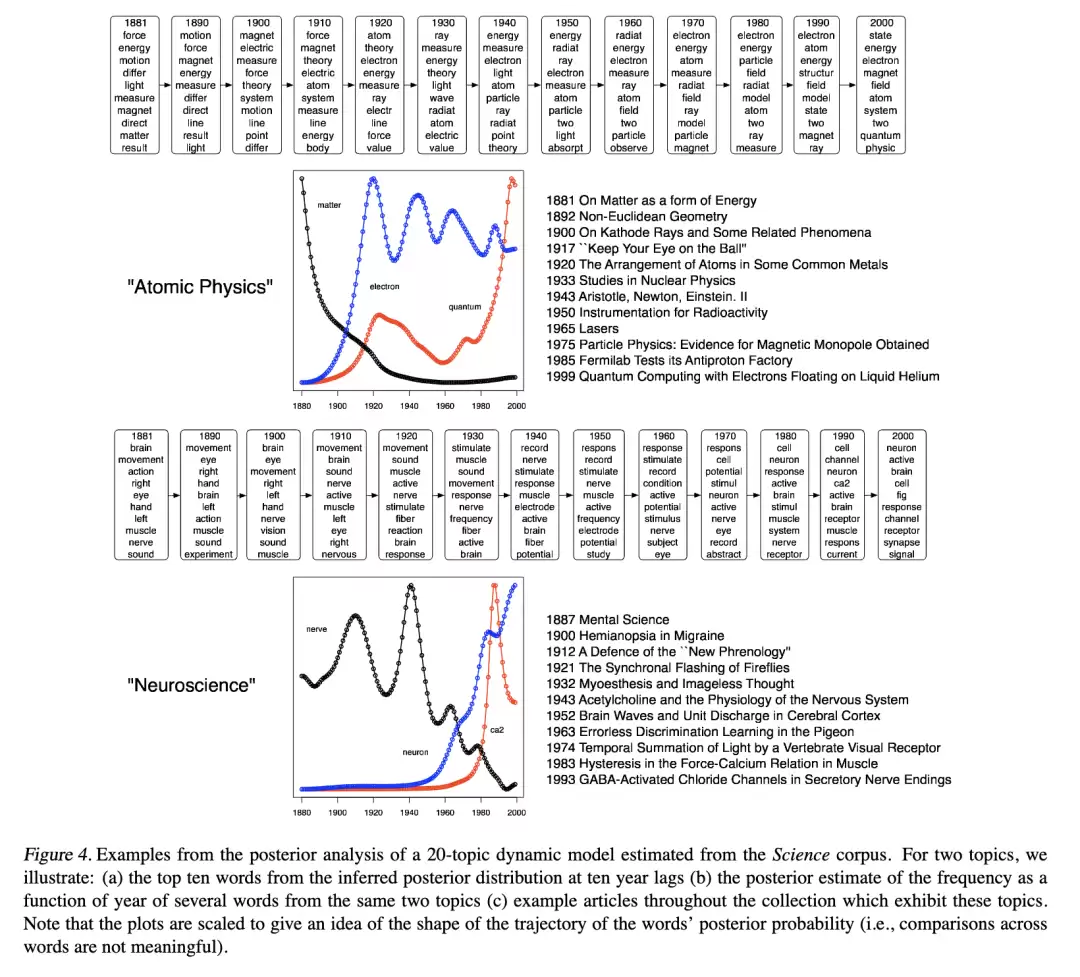
语料库大约有750万个单词。我们通过提取词干、去除功能词、过滤掉出现次数少于25次的词来精简词汇表,最终得到总词汇量15,955个。为了探索语料库及其主题,我们估计了一个包含20个分量的动态主题模型。在一台1.5GHz PowerPC Macintosh笔记本电脑上,后验推断大约耗时4小时。图4展示了其中两个主题的结果——根据使用卡尔曼滤波变分近似估计的后验平均出现次数,显示了这些主题在每十年中的前几个词,同时附有体现这些主题的示例文章。很明显,模型捕获了不同的科学主题,并且可以用于检查词语使用的演变趋势。
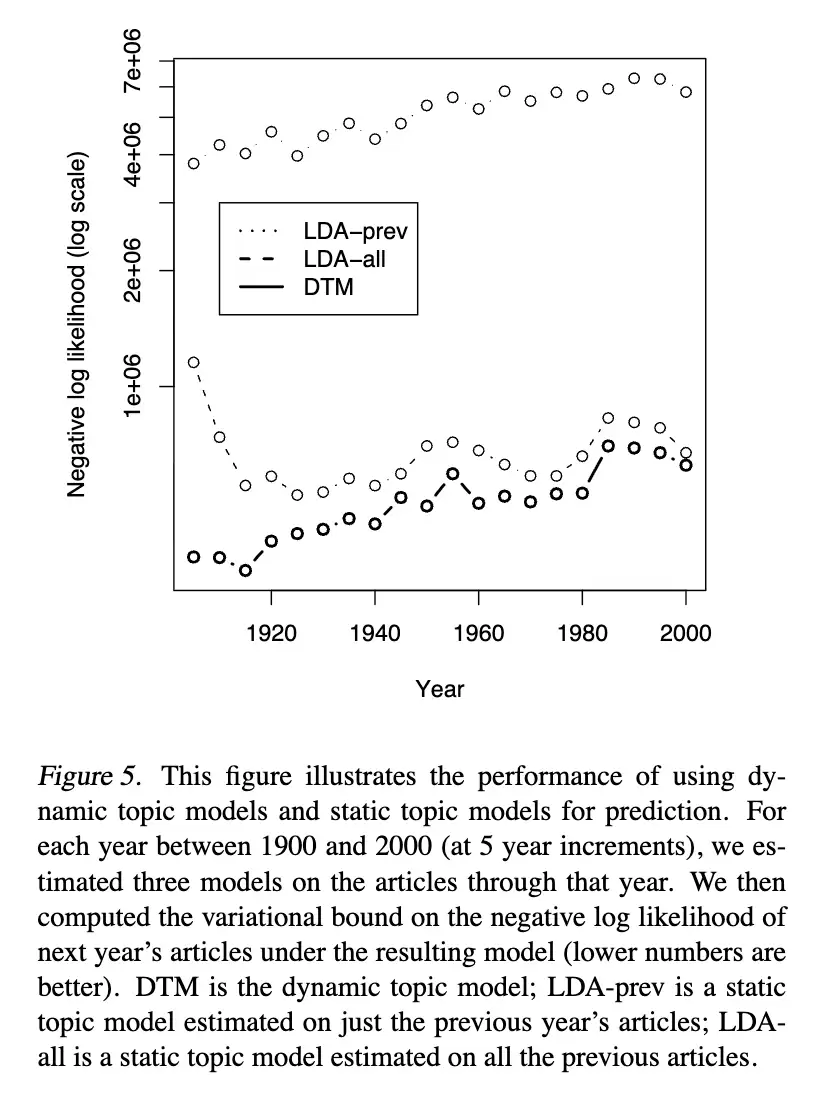
为了定量验证动态主题模型,我们设计了一个任务:根据往年所有文章预测《科学》杂志下一年的内容。我们比较了三种20主题模型的预测能力:根据往年所有数据估计的动态主题模型、根据往年所有数据估计的静态主题模型,以及仅根据前一年数据估计的静态主题模型。所有模型都估计到相同的收敛标准,且根据所有往年数据估计的主题模型和动态主题模型在同一点初始化。
结果很显著:动态主题模型表现最优,总是赋予下一年文章更高的似然值(图5)。有趣的是,每种模型的预测能力都随着时间推移而下降。一个可能的解释是:科学语言的专业化程度在不断提高。