翔宇工作流100个原创Skill 第10期
本期内容聚焦于一套全自动视频剪辑系统。它的运作模式非常直观:只需输入一段原始视频,系统便会自动生成带有旁白、字幕和背景音乐的完整成片,整个过程几乎无需手动操作。我们不仅会深入解析这套系统的设计思路与工程理念,还将分享一个核心洞察——这个洞察或许会重塑你的工作方式:工具不断更迭,但工作流程始终保持不变。
别被“论文级教程”这个说法吓到。有朋友反馈我的文章像学术论文,读起来有些吃力,建议我加个摘要。这大概是学生时代留下的习惯。今天这篇也不例外——万字长文,直奔主题,全是干货。
上面展示的示例(更多成果可参考相关演示视频)都是这套Skill的实际产出:AI根据输入的原始素材自动完成剪辑、配音、配乐,直接输出一部类似“舌尖上的中国”风格的短视频。
这就是“创剪 Skill”正在做的事。这个项目经历了三代工具的迭代。早在Make和N8N工作流时期,我就尝试用自动化流程剪辑视频。后来编写了一个数万行代码的创剪项目来实现相同功能。当前版本换用了Claude Code的Skill作为外壳,但核心骨架依然如故。
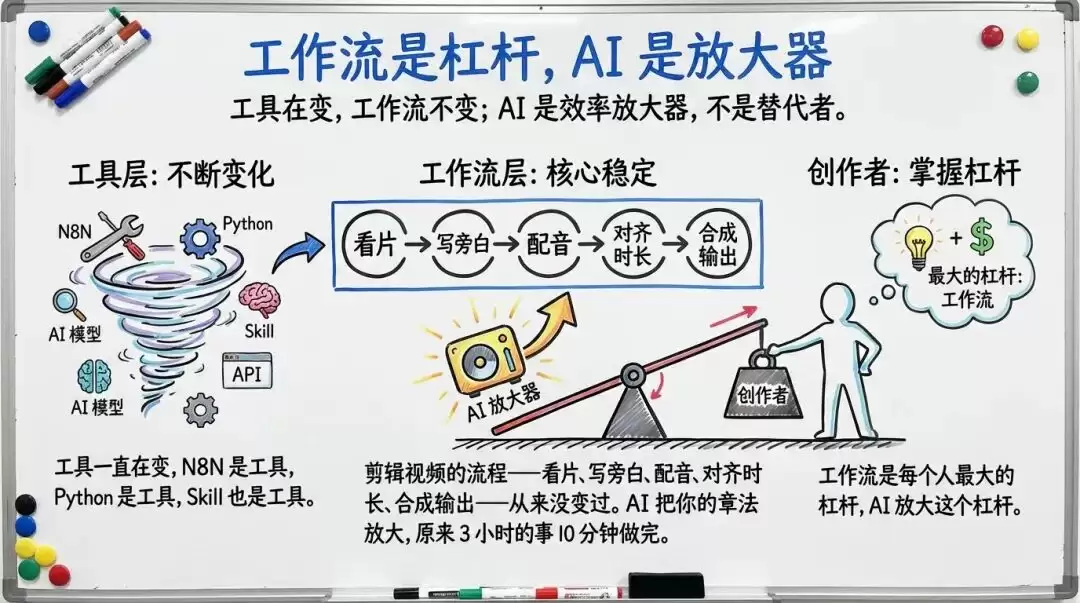
这里有一个我经过三代工具反复验证的观点:工具始终在变,工作流从未改变。
Make与N8N是工具,数万行TypeScript是工具,Skill也是工具。但剪辑视频的流程——看片、写旁白、配音、对齐时长、合成输出——这个工作流始终如一。
如果你是一名内容创作者,你一定有自己的方法论。这套方法论就是你的工作流,是你多年积累的肌肉记忆。AI所做的仅仅是放大你的能力。原本需要3小时完成的任务,AI能在10分钟内搞定。
你的价值没有改变,但效率被放大了10倍。
工作流是每个人最大的杠杆。AI只是放大器。
你是否拥有自己的工作流?那个无需思考、自然启动的做事流程?
工作流是杠杆,AI 是放大器
这个问题我问过很多人,答案大致分为两类。
内容创作者大致有两种类型。一种是“手工匠人型”,享受每一帧的精雕细琢,剪辑本身就是创作过程的一部分。另一种是“系统架构型”,认为重复劳动是对生命的浪费,能自动化的绝不手动操作。
这篇文章主要面向第二种人。如果你是第一种——理解自动化的设计逻辑,同样能让你的手工创作更有章法。
好了,回到创剪 Skill。
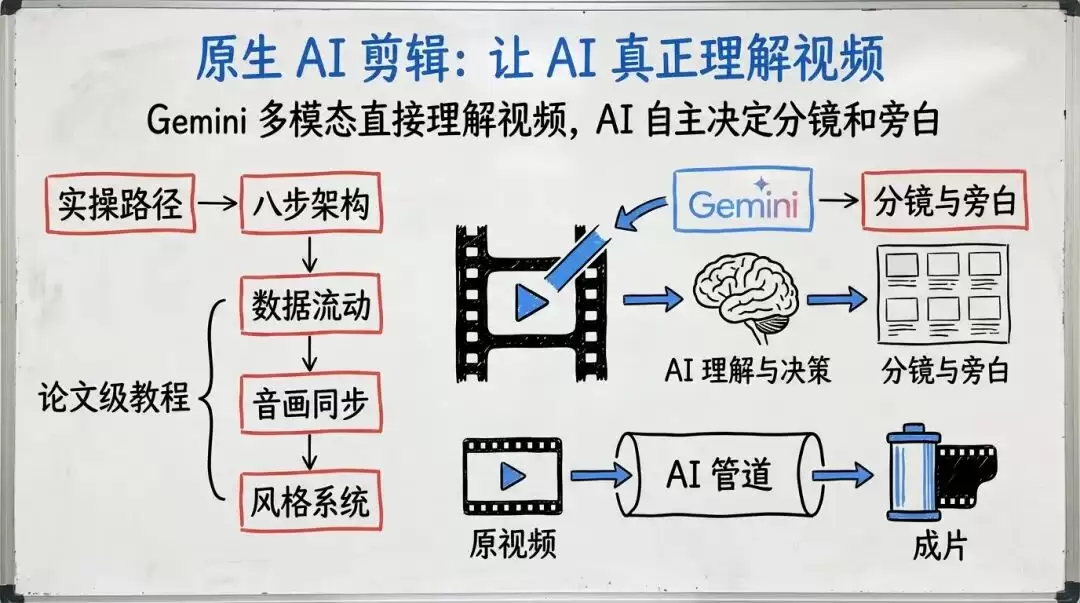
该项目的核心逻辑是“原生 AI 剪辑”——完全让 AI 理解视频内容,无需人工干预。AI 观看视频后,自主决定如何分镜、撰写旁白、保留原声或调整速度。
目前视频理解能力最强的模型是 Google 的 Gemini。它的上下文窗口能够容纳整段视频,多模态能力可以直接“看”画面并输出结构化的分镜剧本。创剪 Skill 的整个系统就是围绕 Gemini 的视频理解能力设计的。
读完这篇文章,你将掌握:
- Cherry Studio 的实操路径——如何在你的电脑上运行起来
- 八步流水线的全景架构——每一步的具体功能及设计原因
- 数据流动的完整轨迹——追踪一个分镜从诞生到成片的全过程
- 音画同步的核心难题——为什么画面和声音容易错位,以及创剪 Skill 如何应对
- 风格系统的设计哲学——一个配置文件如何定义一种美学风格
原生 AI 剪辑:让 AI 真正理解视频
一、先跑起来:在 Cherry Studio 中使用创剪 Skill
在阐述设计哲学之前,先让你能实际运行起来。动手前,花30秒理解两个概念。搞清楚这些,后续每一步你都知道自己正在做什么。
Cherry Studio。 这是一款开源的多模型AI桌面客户端,集成了300多个模型,支持macOS、Windows、Linux。它解决了两个痛点。第一:模型太多太分散。OpenAI一个网页,Claude一个网页,Gemini又一个。Cherry Studio将它们整合到同一窗口,一键切换。第二,也是更重要的:它将Claude Code Agent SDK这套复杂的底层能力封装为图形界面。无需打开终端、无需敲命令,点击鼠标就能让AI在你的电脑上执行代码、操作文件、运行Skill。Cherry Studio让“使用Skill”变得像聊天一样简单。
Agent + Skill。 Cherry Studio中的Agent模式让AI具备“动手干活”的能力。但它仍然是通才——你说“剪视频”,它可能写一段命令让你自己执行,也可能理解为“帮我写个剪辑教程”。有能力,但缺乏章法。Skill解决了这个问题。Anthropic在2025年推出的能力模块化标准,将指令、脚本、参考资源打包成一个文件夹,Agent遇到对应任务时自动加载。这不是限制AI,而是给它一条明确的路径——每次说“剪视频”,它都知道该走哪八步。
Cherry Studio提供了界面,Agent提供了执行力,Skill提供了确定性。创剪就是那个让“剪视频”变得确定的Skill。
第一步:下载安装 Cherry Studio
前往官网 cherry-ai.com,根据你的操作系统(macOS / Windows / Linux)下载对应版本,安装后打开即可。
Cherry Studio 官网首页:你的超级 AI 工作站
第二步:配置模型密钥
打开 Cherry Studio,进入设置 → 模型服务。左侧找到 CherryIN,开启开关。右侧会显示 API 密钥和 API 地址。API 地址默认是 https://open.cherryin.cc,无需修改。密钥需要前往 CherryIN 官网获取。具体步骤如下:
设置页面:开启 CherryIN 服务商

CherryIN 令牌管理:创建 Claude 令牌并复制
回到 Cherry Studio,把复制的密钥粘贴到 API 密钥栏,点击“检测”验证连通性。然后点击下方“管理”进入模型添加页面。

粘贴密钥,点击管理按钮
在弹出的模型列表中搜索 claude,找到 anthropic/claude-opus-4.6,点击添加。

模型列表:选择 anthropic/claude-opus-4.6
第三步:安装 Claude Code(Agent 底层引擎)
Cherry Studio 的 Agent 模式底层依赖 Claude Code——Anthropic 官方的命令行 AI 编程工具。没有它,Agent 就只能聊天,无法动手操作。打开 Cherry Studio,点击左侧导航栏的“代码工具”图标。上方会显示 Claude Code 选项,以及一个黄色提示:“运行 CLI 工具需要安装 Bun 环境”。点击右侧的“安装 Bun”按钮,等待安装完成。
代码工具页面:安装 Bun 环境
Bun 安装完成后,继续向下配置:
- 模型:选择你要使用的模型
- 工作目录:指定一个本地路径(例如
F:\code-ty),Skill 的所有文件都会存放于此 - 终端:根据个人偏好选择即可
配置完成后,点击底部绿色的“启动”按钮。
配置完成,点击启动
Cherry Studio 会自动打开终端,开始安装 Claude Code。你会看到 Installing @anthropic-ai/claude-code... 的进度条滚动。

终端安装 Claude Code 进行中
安装完成后,终端会显示一条黄色警告:Claude Code on Windows requires git-bash。这意味着 Windows 用户还需要安装 Git Bash。
安装完成,提示需要 Git Bash
前往 Git 官网 git-scm.com,下载 Windows 最新版本并安装。

Git 官网:下载 Windows 版本
Claude Code 启动成功:选择主题
第四步:创建 Agent
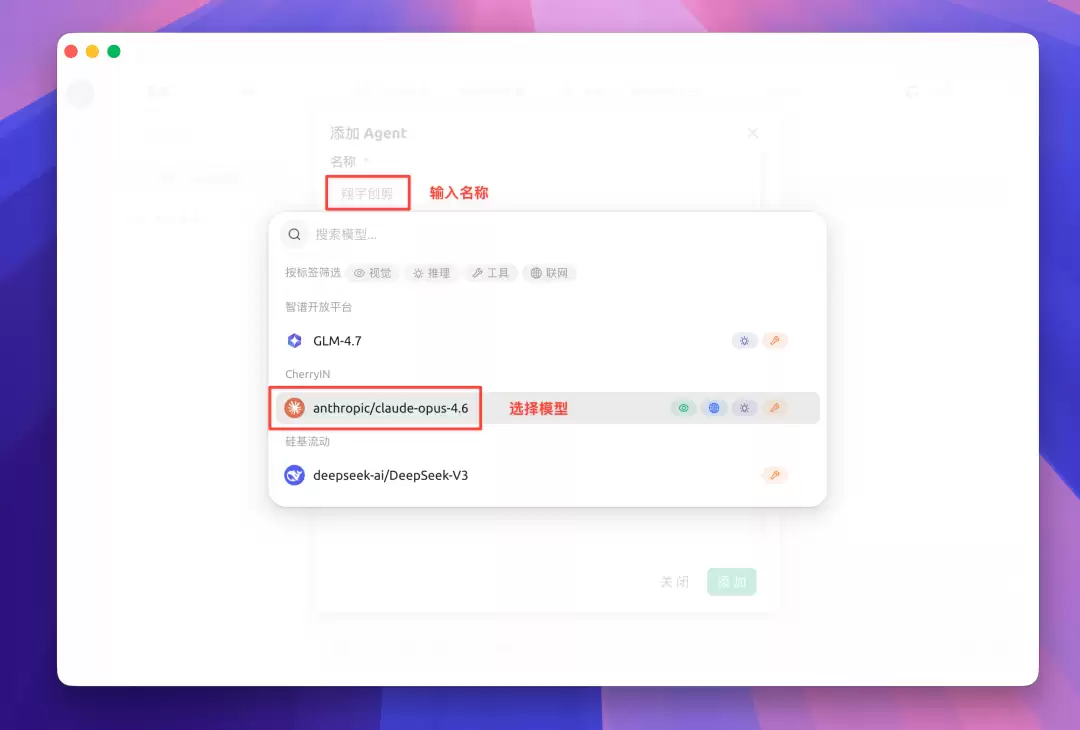
回到主界面,点击左上角“添加助手”。弹出选择框时,不要选“添加助手”——选右边的“添加 Agent”。助手只能聊天,Agent 才能动手干活。

选择添加类型:点击“添加 Agent”
在 Agent 配置弹窗中,依次填写:
- 名称:随便取,比如“翔宇创剪”
- 模型:选择刚才添加的 anthropic/claude-opus-4.6 | CherryIN
- 工作目录:指定一个本地路径,Skill 的中间产物和成片都会输出到这里
- 权限模式: 跳过所有权限检查 (请确保在隔离环境中使用做好数据备份)
- 提示词:填入
调用如下 skill: xiangyu-video-chuangcut-editing
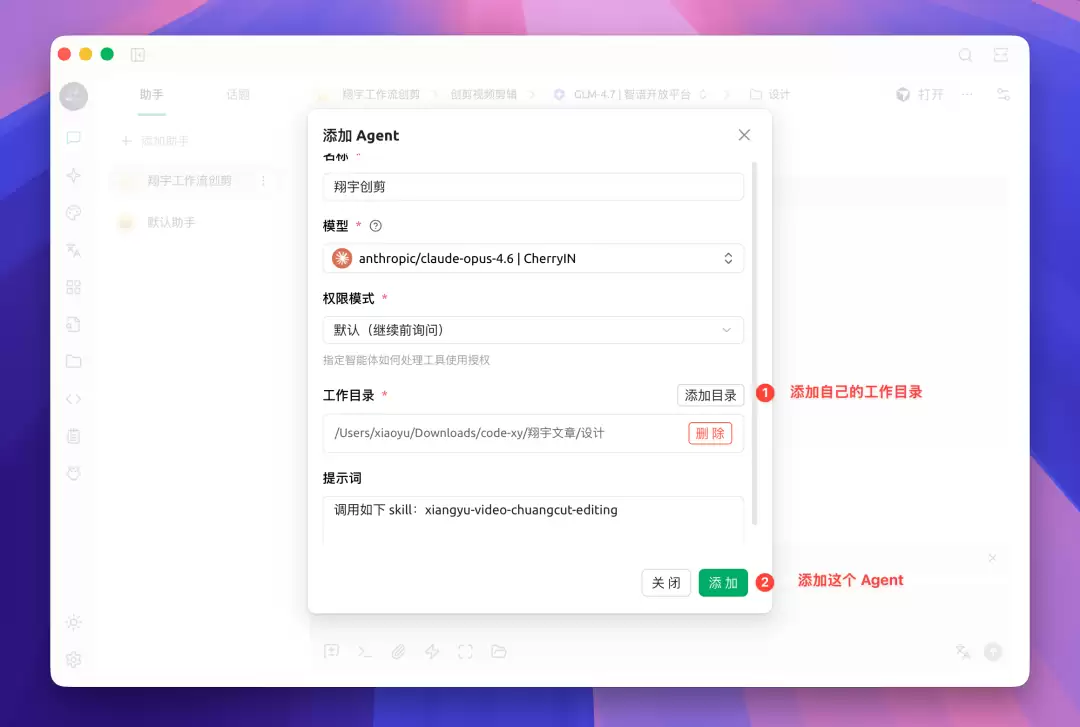
Agent 完整配置:名称、模型、工作目录、提示词
第五步:安装创剪 Skill
创剪 Skill 是翔宇自己开发的,不在 Cherry Studio 的公开技能市场里,需要手动安装。打开你刚才设置的工作目录,进入隐藏文件夹 .claude,再进入 skills/ 目录。把创剪 Skill 的整个文件夹(xiangyu-video-chuangcut-editing)复制粘贴到这里即可。Agent 会自动识别并加载它。如果没找到该文件夹,可先去市场安装任意 Skill。
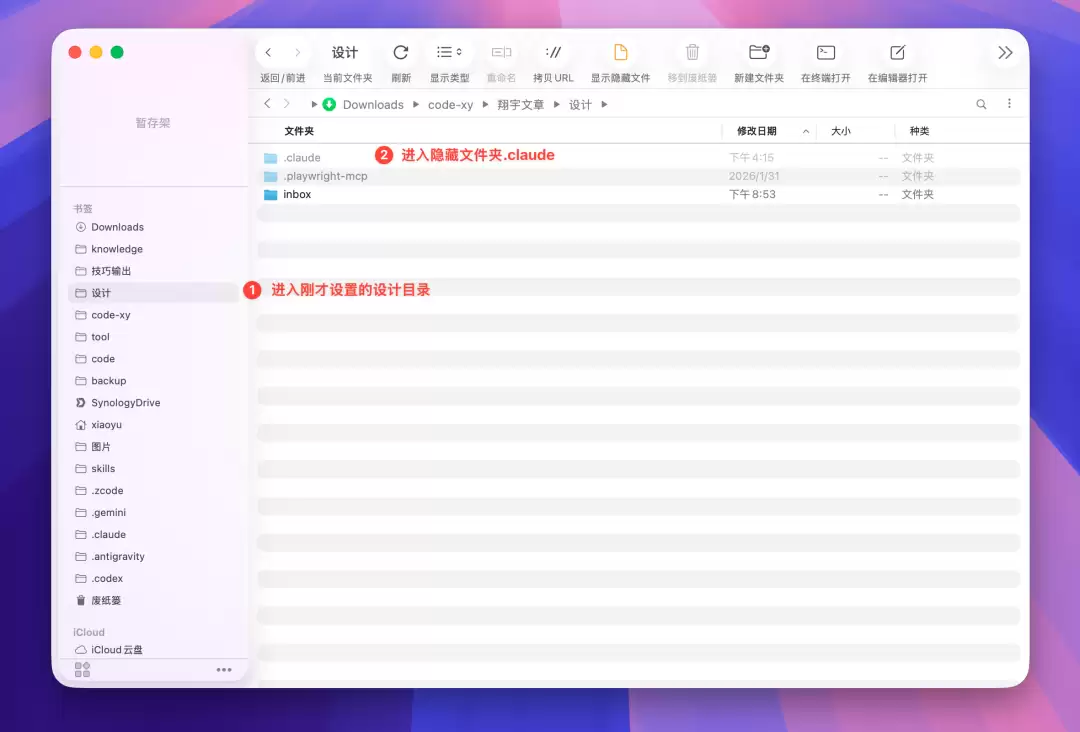
工作目录下的 .claude 隐藏文件夹
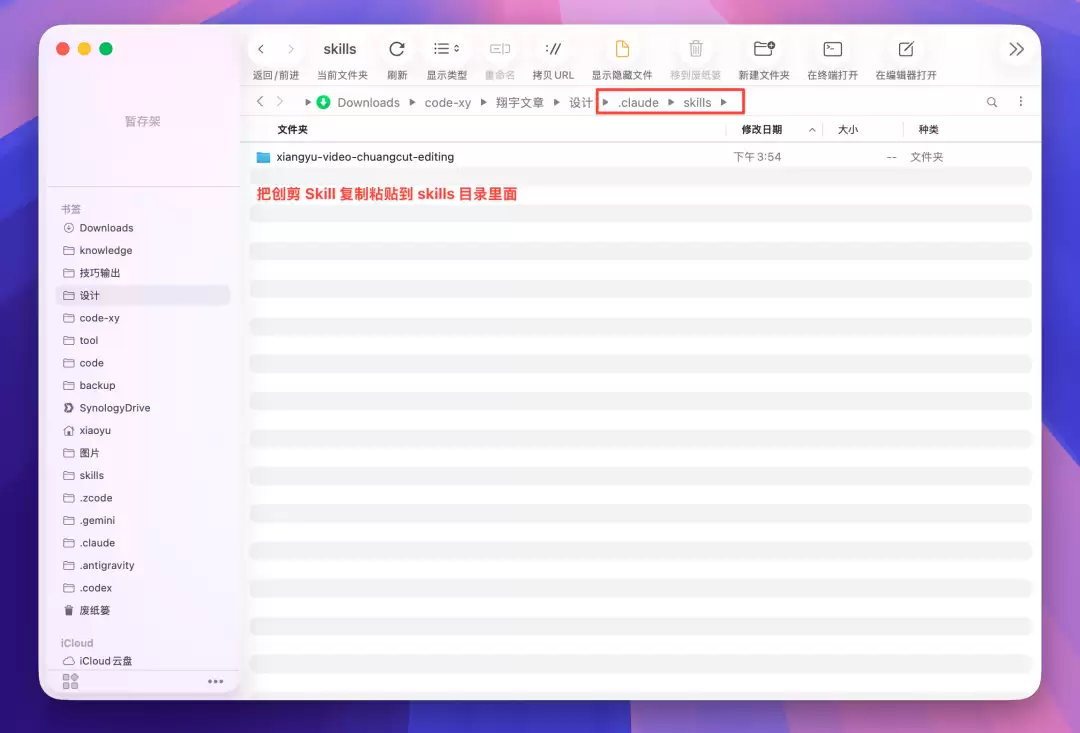
skills 目录下放入 xiangyu-video-chuangcut-editing
第六步:配置环境
创剪 Skill 运行需要两样东西:API 凭据——Gemini 看片 + Fish Audio 配音,以及运行时依赖——Python 环境 + FFmpeg。让 Agent 帮你搞定。回到 Cherry Studio,打开刚创建的 Agent 对话窗口,发送这段话:
“我刚在 .claude/skills/ 放置了创剪 Skill(xiangyu-video-chuangcut-editing),请帮我完成环境配置:1)读取 Skill 目录下的 credentials/,列出每个凭证文件需要填写的字段、用途和 Key 申请地址;2)运行 scripts/setup.sh,完成虚拟环境创建、依赖安装和 FFmpeg 验证,遇到报错直接修复。需要密钥时直接向我索要。”
Agent 会自动读取配置、运行初始化脚本、装好所有依赖。你只需要做一件事:把申请到的 API Key 填进去。

Agent 对话界面:发送环境配置指令
第七步:触发创剪 Skill
在对话框输入触发关键词——“视频剪辑”“创剪”“ChuangCut”“剪视频”,任一即可。触发后,Agent 会像导演开工前一样,通过对话逐步和你确认参数。整个过程就是聊天,不需要填表、不需要改配置文件。
第一轮对话(所有模式都会问):
- 视频文件在哪里?——给一个路径
- 要保留几个原声分镜?——比如煎牛肉的滋啦声,保留比配音更有感染力
- 选哪种模式?——自动 / 手动 / 高级
自动模式 到这里就结束了,Agent 用默认参数直接开始。第一次用,选这个就够了。
手动模式 会多问两个:选哪种风格(20 种可选,美食纪录片、TikTok 带货……)、要几个分镜。
高级模式 在手动的基础上,再问背景音乐用哪首、要不要输入创作大纲、是否生成字幕。煎烤视频就是用高级模式跑的——指定了美食纪录片风格、6 个分镜、一首自定义 BGM。
参数确认对话:选择模式和风格
第八步:等待八步流水线执行
参数确认完,Agent 自动执行八步流水线。整个过程约 5-15 分钟,取决于视频时长和网络状况。你会在对话窗口看到每一步的执行状态——初始化、AI 看片、视频切片、旁白校准、AI 配音、调速合成、拼接、输出。不需要任何操作,喝杯咖啡等着就行。执行过程中可能会遇到报错——API 超时、文件路径不对、依赖版本冲突。不用慌。Agent 会尝试自动修复常见问题(如 API 超时重试)。遇到无法自动修复的,它会告诉你问题出在哪,你按提示处理即可。需要说明的是该 Skill 仅测试了短视频的剪辑,针对长视频并未做详细测试。
第九步:获取成片
处理完成后,Agent 会告诉你成片的路径,同时生成一份 Markdown 格式的制作报告——记录每个分镜的时长、速度因子、选用的旁白版本等信息。成片在你指定的工作目录下,制作报告在同级目录,直接打开即可。
跑起来了。接下来拆开引擎盖——这八步到底在做什么,每一步的设计决策背后有什么工程哲学。
二、八步流水线总览

八步流水线全景:从视频到成片
先给你一张全景地图。八个步骤像工厂的八道工序。每道工序只做一件事,上一道的产出就是下一道的原料。这个设计在工程上叫“管道模式”,你可以把它想象成一条流水线,视频从一端放进去,成片从另一端出来。
- 第一步:初始化。告诉系统“剪什么、怎么剪”。煎烤视频选了高级模式,指定美食纪录片风格、6 个分镜、一首背景音乐。
- 第二步:AI 看片。AI 观看视频,写出分镜剧本和旁白。Gemini 识别出蒜瓣热油、煎牛肉、炒口蘑、炸鸡翅、金沙鸡翅、收尾 6 个场景。
- 第三步:视频切片与跳切检测。按剧本时间戳切片,扫描首尾修剪残留画面。煎烤视频 6 段全部干净,无需修剪。
- 第四步:旁白校准。检查旁白字数是否匹配画面时长,基于语速系数逐段校准。
- 第五步:AI 配音。为旁白生成语音,计算速度因子。5 段 AI 配音 + 1 段保留原声。
- 第六步:调速合成。调整画面速度、烧入字幕,3 路并行处理。
- 第七步:拼接。合并所有分镜,混入背景音乐,BGM 音量 15%,循环混入。
- 第八步:输出。生成最终视频和制作报告,成片交付。
每一步完成后,系统在进度文件中记录状态。中途断电或出错,重新启动时从中断点继续——这叫“断点恢复”。核心设计原则是“单一职责”:每一步只做一件事,任何一步出问题,只修那一步,不影响其他步骤。
这八步本质上做的是一件事:把不确定性逐步消除。每走一步,系统对最终成品的掌控力就多一分。下面一步一步拆。
三、每个步骤在做什么
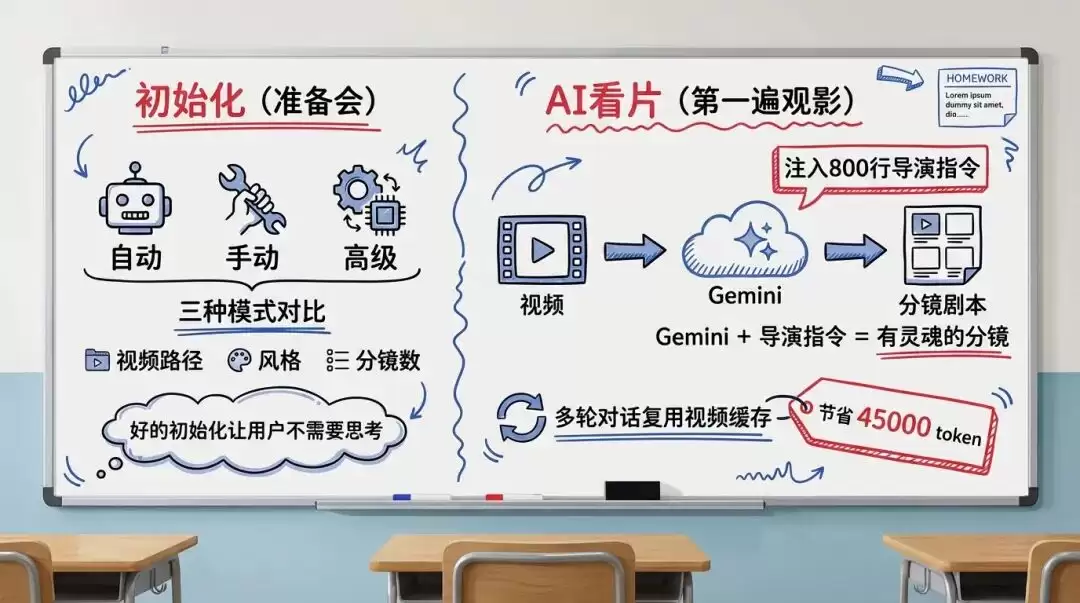
第一步:初始化,导演开机前的准备会
第一章讲了三种模式的区别,这里只说一个关键动作:系统用 FFprobe 读取视频元信息——时长 94 秒,分辨率 720×1280,帧率 60。后续所有计算(分镜时长、旁白字数)都依赖这些基础数据。好的初始化不是问更多问题,是把默认值设到最好。
第二步:AI 看片,导演的第一遍观影
这是整个系统最关键的一步。系统把视频上传给 Google Gemini,连同一份“导演指令”,告诉 AI 用什么美学标准来分析。美食纪录片风格的导演指令长达 800 多行,定义了四条守则:绝对音画同步、先解构再书写、用节奏聚焦感官、旁白是温度。正是这份指令让 AI 写出了“高温是风味的起点”“时间赋予了它独特的韧性”这样有纪录片质感的旁白,而不是“今天教大家做一道煎牛肉”这样的教程口吻。
Gemini 看完后输出一份分镜剧本:第一个镜头从第 6 秒到第 15 秒,拍的是蒜瓣在热油中翻滚;第二个镜头从第 15 秒到第 26 秒,拍的是煎牛肉……每个分镜包含起止时间和一段旁白。
这里有一个巧妙的成本优化。系统和 Gemini 的对话分两轮:第一轮上传视频并注入导演指令,输出分镜剧本;第二轮在同一个对话中生成多版旁白。因为第二轮复用了第一轮的视频上下文缓存,不需要重新上传视频,大约节省了 45000 个 token。你付出的是一次 API 调用的费用,得到的是一个不知疲倦的导演。
初始化与 AI 看片:导演的准备会和第一遍观影
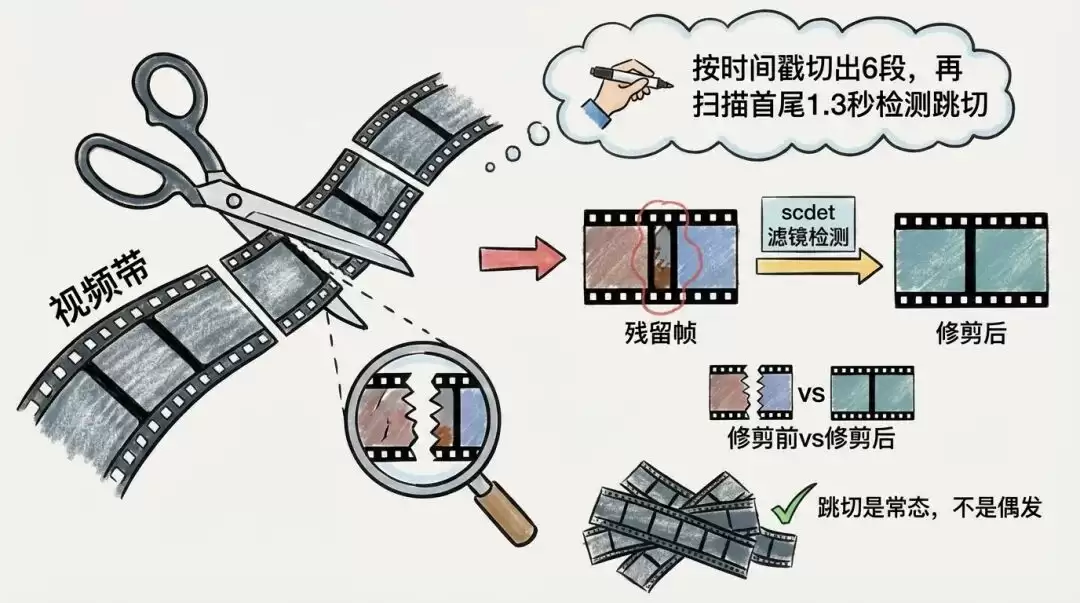
第三步:视频切片与跳切检测,剪刀落下,再擦去毛边
按分镜剧本的时间戳,用 FFmpeg 把完整视频切成 6 段素材。切完后,系统扫描每段首尾各 1.3 秒,检测有没有残留画面——比如蒜瓣的画面闪了一帧才切到煎牛肉,观众就会感知到一次不自然的“跳”。系统用 FFmpeg 的 scdet 滤镜扫描并自动裁掉残留帧。煎烤视频的 6 个切点都干净,全部跳过修剪。但广州美食视频就没这么幸运:8 段中有 5 段需要修剪,烤鸭那段开头 1.03 秒残留着肠粉画面。把不干净的剪刀口擦干净。这一步不影响内容,但决定品质。
视频切片与跳切检测:剪刀落下,再擦毛边
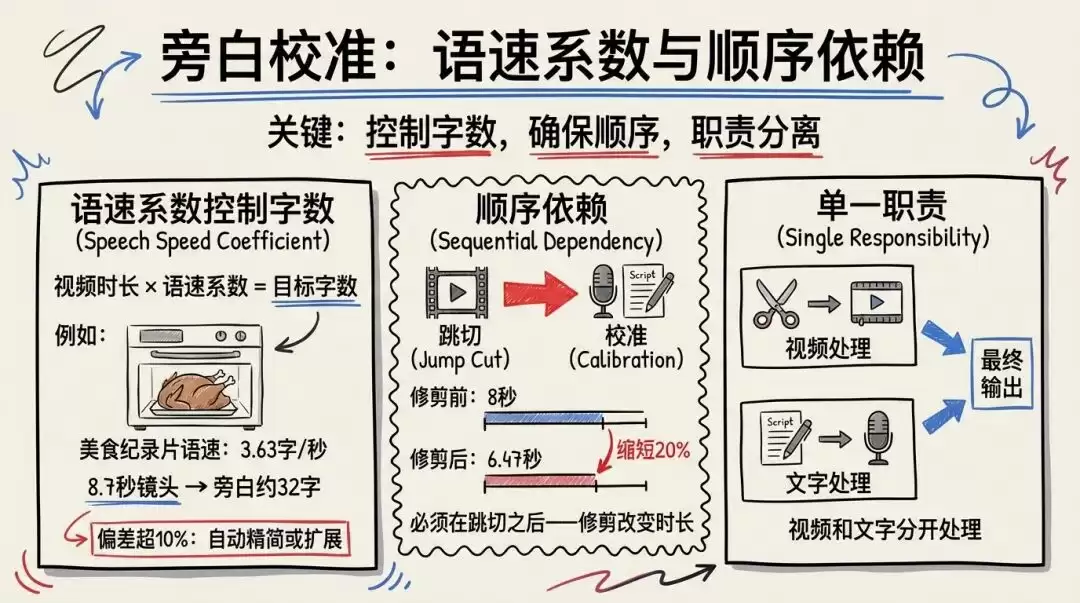
第四步:旁白校准,编辑的红笔
美食纪录片的语速大约每秒 3.63 个字。一个 8.7 秒的蒜瓣热油镜头,旁白应该在 32 个字左右。系统逐段检查旁白字数。如果偏差超过 10%,就自动精简或扩展。比如一段旁白本来有 45 个字,但画面只有 8 秒,按 3.63 字/秒算应该是 29 个字,偏多了 55%,系统会把旁白精简到 29 字左右。
注意这一步排在跳切检测之后。为什么?因为跳切修剪可能会改变画面时长。广州美食视频中,烤鸭分镜原本 8 秒,修剪后变成 6.47 秒,缩短了将近 20%。如果在修剪之前算字数,就会算多。这是一个典型的“顺序依赖”设计——步骤的排列顺序不是随意的,后面的步骤依赖前面步骤的准确输出。
旁白校准:语速系数与顺序依赖
第五步:AI 配音,声音的诞生
校准后的旁白送给 Fish Audio 生成配音。这里有一个不常见的设计——系统不是生成一版配音,而是同时生成三版:一版语速快、一版语速中等、一版语速慢。三版并发生成,哪版的时长最接近画面时长,就选哪版。为什么?因为语音合成引擎无法精确控制输出时长。你告诉它“把这 32 个字念出来”,它可能念出 8 秒,也可能念出 11 秒,取决于它如何处理停顿、语气和节奏。生成三版,选最接近的,比生成一版然后反复重试更高效。选中后,系统计算一个关键数值:速度因子。这个概念在后文“音画同步”部分会详细解释。另外,煎烤视频的第二段“煎牛肉”被标记为保留原声。这正是保留原声的价值——有些声音,比任何旁白都有感染力。
第六步到第八步:从碎片到成品
- 第六步:调速合成。把画面速度、配音、字幕三者融合为一个片段。字幕用 ASS 格式生成,可以指定字体大小(48 号)、描边颜色(黑色双重描边)、位置(底部居中)、每行字数(20 字自动换行)。三路并行处理,三个分镜同时合成。
- 第七步:拼接。6 段首尾相连,背景音乐压到 15% 音量循环混入。15% 是一个经过实践验证的数值,再高会盖过旁白,再低存在感不够。
- 第八步:输出。成片复制到输出目录,生成一份制作报告,记录每个分镜的时长、速度因子、选用的旁白版本等信息。
八步流水线可以分成三个阶段来记忆:分析准备(第 1-4 步)——从一段视频到一份精确的剧本;素材加工(第 5-6 步)——从剧本到一堆带声音的片段;合成输出(第 7-8 步)——从一堆片段到一部成片。

从配音到成品:三版择优与三路并行
四、数据在步骤间如何流动
第三章是每一步各自在做什么。这一节换个视角——跟着一个具体分镜走完全程,看数据如何变形流动。以煎烤视频的第四个分镜“炸鸡翅”为线索。
- AI 看片:Gemini 在第 59-69 秒识别出炸鸡翅画面(9.7 秒),写下旁白初稿,以 JSON 格式写入分镜剧本。
- 跳切检测:切出视频片段,扫描首尾画面干净,时长保持 9.7 秒。
- 旁白校准:9.7 秒 × 3.63 字/秒 = 35 字,系统微调定稿。
- AI 配音:定稿旁白合成出 12.4 秒配音——比画面长了近 3 秒。速度因子 = 9.7 ÷ 12.4 = 0.78,视频需要减速到 0.78 倍。
- 调速合成:视频 0.78 倍速 + 配音正常速度 + 字幕按标点断句,三者合并。观众看到稍慢的炸鸡翅画面配上从容旁白——美食纪录片,慢一点反而更有质感。
- 拼接:炸鸡翅排第四位,和其他五段拼接,背景音乐贯穿始终。
数据在步骤间的形态不断变化:视频文件 → 分镜剧本 → 视频片段 → 音频文件 → 合成片段 → 成片。每一次交接,形态变了,但信息被完整保留。好的管道设计,就是让每一步只需要知道上一步给了它什么,不需要知道更远的事。

数据追踪:一个分镜从诞生到成片
五、为什么画面和声音总是对不上
这是整篇文章的核心问题。本质是精度不对等:视频时长精确到毫秒,语音合成的时长精度只到“大概差不多”。35 个字可能合成出 8 秒,也可能 13 秒。再叠加跳切修剪改变视频时长——画面和声音几乎不可能天然对齐。
创剪 Skill 的解法是一道除法:速度因子 = 视频时长 ÷ 音频时长。等于 1.0 完美同步,大于 1.0 画面加速,小于 1.0 画面减速。煎烤视频 6 个分镜实测:蒜瓣热油 1.00,煎牛肉保留原声,炒口蘑 1.14,炸鸡翅 0.78,金沙鸡翅 0.84,收尾 0.94。6 个分镜只有一个命中 1.0。时长天然不匹配,是常态而非例外。

音画不同步的根源:精度不对等
三道防线:预防、补偿、硬底线
- 上游预防:旁白校准阶段用语速系数提前控制字数。蒜瓣热油之所以命中 1.0,正是上游预防的成功案例。
- 下游补偿:用 FFmpeg 变速调整画面播放速度。0.8 到 1.2 范围内人眼几乎感觉不到——你不会注意到炸鸡翅慢了 22%,美食画面本来就适合慢节奏。
- 硬底线:速度因子超出 0.5 到 1.5,分镜直接丢弃。不修复,不降级,直接放弃。少一个好镜头,远好过多一个坏镜头。
这背后是一个重要的设计哲学:消除问题优于处理问题。

三道防线:预防、补偿、硬底线
六、AI 不是万能的,但可编辑就够了
讲完了音画同步的工程方案,必须说一个很多人不愿意面对的事实:Gemini 会犯错。它是一个概率模型,不是一个精密仪器。每次分析同一段视频,输出可能不一样。时间戳可能偏了两秒,旁白可能出现幻觉——明明画面里是炒口蘑,它写的是“翻炒着鲜嫩的牛肉”。上下文窗口虽然大,但对 94 秒视频中某个 0.3 秒的转场,它的判断本质上是猜的。这不是创剪 Skill 的问题,这是大模型的底层特性。
字数校准能修正一部分偏差,速度因子能补偿一部分偏差,硬底线能过滤极端情况。但总有一些分镜,Gemini 给的时间戳就是不准,配音和字幕就是对不上。翔宇做了三代工具,这个问题每一代都存在。
那怎么办?答案藏在 Skill 的本质里:它跑在你的本地环境,所有中间产物都是可编辑的。分镜剧本是 JSON 文件,你可以手动改时间戳。旁白是文本,直接改措辞。配音是音频文件,可以重新生成。字幕是 ASS 文件,可以微调起止时间。甚至速度因子,也可以手动覆盖。出了问题不可怕。让 Agent 重新跑一下那个步骤,或者你自己改两行配置,问题就解决了。这就是“可编辑”的价值——不是追求一次完美,而是让修正的成本足够低。
可编辑的不只是中间产物,Skill 本身也是可编辑的。翔宇不认为今天的创剪 Skill 是最终版。Agent 具有自主能力,你完全可以用自然语言告诉它“把导演指令改成更幽默的风格”“语速系数调高一点”“加一个新的风格模板”——它会直接帮你修改 Skill 的配置文件和脚本。不需要懂代码,聊天就能调试。产出可编辑让你修正错误,Skill 可编辑让你定义自我。
八步流水线的断点恢复设计,本质上就是为“可编辑”服务的。你不需要从头跑,只需要从出错的那一步重新开始。
大模型能力在指数级增长,今天偏两秒的时间戳明年可能只偏 0.1 秒,八步流水线里真正不可替代的只有两步:AI 看片和风格系统,其余六步本质上都在补偿模型能力的不足。
工具会越来越简单,但前提是你现在就用原生的方式去构建它。当所有人都能用一句话让 AI 剪视频时,真正的差距在你的风格系统、导演指令和沉淀了三代工具的工作流。工具普惠化,认知垄断化。
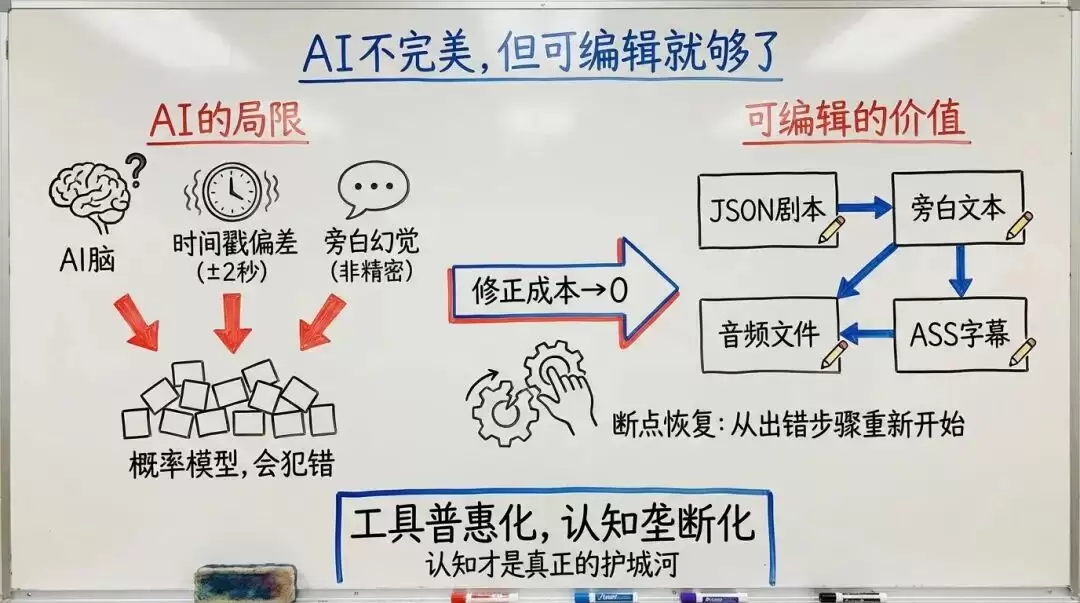
AI 不完美,但可编辑就够了
七、风格系统:一个文件定义一种美学
创剪 Skill 内置 20 种风格。每种风格用一个配置文件定义四样东西:
- 导演指令:告诉 AI 用什么美学标准分析视频。美食纪录片的导演指令要求“绝对音画同步、先解构再书写、用节奏聚焦感官”,而 TikTok 带货风格的导演指令则要求“节奏紧凑、卖点前置、情绪感染”。
- 配音音色:美食纪录片用沉稳男声,带货用活力女声。每种风格绑定一个 Fish Audio 的音色标识。
- 语速系数:美食纪录片 3.63 字/秒,慢节奏,有呼吸感。带货 3.8 字/秒,快节奏,信息密度高。深度拉片 3.13 字/秒,最慢,学术气质。
- 分镜时长范围:美食 6-12 秒慢节奏,带货 4-8 秒快节奏,演讲访谈 10-20 秒长镜头。
这四样东西写在同一个文件里,一个 YAML 格式的配置文件,大约 100 行。20 种风格覆盖了大多数场景:通用解说、商品评测、TikTok 带货、搞笑混剪、综艺解说、游戏解说、演讲访谈、纪实故事、历史纪录、自然萌趣、儿童动画、毒舌影评、电影解说、深度拉片、美食纪录片、治愈风景、文案配画、黑帮狠人、专业播音、短视频复刻。
要新增一种风格,只需写一个新的配置文件,不需要改任何代码。同一段煎烤视频,换成 TikTok 带货风格,会剪出节奏更快、文案更直接的完全不同的短片。“姐妹们看这个鸡翅!外酥里嫩!”vs“热油,是成就酥脆的魔法”——同一段画面,两种完全不同的表达。
如果你是做内容的人,你会发现这正是“内容复用”的终极形态:一次拍摄,多种表达,覆盖多个平台的调性。创作者的时间应该花在创意上,不是在重复劳动上。
风格系统的核心思想是“配置即行为”。你不需要理解系统内部的代码,只需要修改一个配置文件,就能改变系统的输出。把“变化的部分”(风格偏好)和“不变的部分”(处理流程)分离开来。

风格系统:配置即行为
八、结语:好的工程设计不是解决难题,而是让难题不出现
八步流水线的设计哲学可以用一句话概括:把一个复杂的创作问题拆解成八个简单的工程问题。音画同步就是最好的例子。创剪 Skill 不试图消灭偏差,而是用字数控制缩小、变速播放消化、硬底线过滤——接受不完美,设计容忍偏差的系统。
这不只是工程设计。这是一种面对不确定性的态度。你不需要控制一切,你只需要预设一条安全边界:接受小偏差(0.8-1.2),砍掉大偏差(<0.5 或 >1.5)。
回到开头那句话:工具一直在变,工作流不变。创剪 Skill 换了三代壳,但骨头没变。你的价值不在于你用什么工具,而在于你对“如何做好一件事”的理解。这个理解,纳瓦尔管它叫“特定知识”——不是学校教的,不是搜索引擎能查到的,而是你在实践中一点一点磨出来的。
你的工作流,就是你的特定知识。AI 能放大它,但替代不了它。十年后回头看,真正值钱的不是你用过哪个工具,而是你在使用工具的过程中,沉淀下来的那套做事的章法。那才是你的护城河。
今天你带走了什么?
四个核心洞见:
- 工具在变,工作流不变——你的工作流就是你的特定知识,AI 放大它但替代不了它
- 消除问题优于处理问题——好的系统让难题不出现,而非堆叠防御机制
- 精度不对等是常态——接受不完美,设计出容忍偏差的系统
- AI 不完美但可编辑——修正的成本足够低,就等于没有问题
一键复刻
看到这里,你应该想亲手试试了。把下面这段提示词复制给 Claude Code,你就能从零搭建自己的 AI 剪辑系统:
“你是一位高级多媒体系统架构师,精通视频处理管道设计。请帮我从零构建一个 AI 视频剪辑自动化系统,要求如下:
核心目标:输入一段原始视频,输出一部带旁白、字幕、背景音乐的成品短片。全程自动化,人不干预。
技术栈:Python 3.12+ / Gemini API / Fish Audio API / FFmpeg
八步管道设计:
- 初始化:收集用户输入(视频路径、风格选择、分镜数量),用 FFprobe 读取视频元信息(时长、分辨率、帧率),创建运行目录和配置文件
- AI 视频分析:将视频上传至 Gemini,注入风格化导演指令,输出 JSON 格式的分镜剧本,包含每个分镜的起止时间戳和旁白文本。利用 Gemini 多轮对话的隐式缓存,第二轮生成多版旁白时复用第一轮的视频上下文
- 视频切片 + 跳切检测:按分镜时间戳用 FFmpeg 无损切割视频片段。对每段首尾各扫描 1.3 秒,用 scdet 滤镜检测场景跳切,自动裁剪残留帧。跳切检测阈值 8%,裁剪后最小保留 2 秒
- 旁白字数校准:基于语速系数(如美食纪录片 3.63 字/秒)计算每段旁白的目标字数。偏差超过 ±10% 则自动精简或扩展旁白。必须排在跳切检测之后,因为修剪会改变视频时长
- TTS 配音:为每段旁白并发生成三版配音(快/中/慢语速),计算速度因子 = 视频时长 ÷ 音频时长,自动选择速度因子最接近 1.0 的版本。支持标记特定分镜为“保留原声”
- 调速合成:用 FFmpeg setpts 滤镜调整视频播放速度,atempo 调整音频速度,生成 ASS 格式字幕(48号字体、黑色双重描边、底部居中、20字换行),三者合并为完整片段。最大并发 3 路
- 最终拼接:用 FFmpeg concat demuxer 无损拼接所有分镜。若有 BGM,以 15% 音量循环混入
- 输出报告:复制成片到输出目录,生成 Markdown 格式的制作报告
关键机制:
- 速度因子硬底线:超出 0.5-1.5 范围的分镜直接丢弃,不做降级处理
- 断点恢复:每步完成后写入 progress.json,支持中断后从断点继续
- 风格配置化:每种风格用一个 YAML 文件定义(导演指令、音色ID、语速系数、时长范围),新增风格不改代码
- 双重音画同步保障:上游字数校准 + 下游变速补偿
请完整实现这个系统,确保八个步骤顺序执行并支持断点恢复。”




