2026 年的 AI 图片和视频生成工具,已经完成了从"玩具"到"工具"的质变。那些曾经只是"试试看"的生成技术,如今可以直接用来输出发布级的视觉素材了。
过去这一年,GPT Image(gpt-image-2)把中文提示词理解能力拉到了实用线以上;PixVerse、Runway Gen-3 这些图生视频工具,让 4 到 10 秒的高质量视频片段变成了日常产出;ComfyUI 的云端方案,更是直接让没有本地显卡的创作者也能跑起复杂的工作流。所以现在真正的关键,已经不是工具强不强——而是你的提示词写法和工作流设计,能不能把这些能力串成一条稳定的生产线。
这篇指南覆盖了从提示词写法到完整视频成片的全链路,串联了 8 篇深度教程。无论你是需要给文章配图的写作者、需要做缩略图的视频创作者,还是想搭建批量视频产线的内容团队,都能在这里找到可落地的方法。
先看整体地图——AI 视觉创作的五大场景和对应的工具链:
| 场景 | 核心工具 | 交付物 | 单次耗时 |
|---|---|---|---|
| 文章配图 | GPT Image / Flux | 封面 + 正文插图 | 5-15 分钟/篇 |
| 视频缩略图 | GPT Image + 字体叠加 | 1280×720 缩略图 | 3-5 分钟/张 |
| 关键帧生图 | GPT Image / Flux / ComfyUI | 分镜关键帧序列 | 10-20 分钟/组 |
| 图生视频 | PixVerse / Runway / 可灵 | 4-10 秒视频片段 | 2-5 分钟/段 |
| 剪辑成片 | Cherry Studio / 剪映 | 30-120 秒完整短视频 | 15-30 分钟/条 |

AI 图片生成:从提示词到发布级配图
AI 配图的核心不是工具选得对不对,而是提示词写得好不好。同样的 GPT Image,给一句"科技风格的图"和一段结构化提示词,出图质量的差距是天上地下。
提示词的五层结构
一条能稳定产出高质量图片的提示词,通常包含五个要素:
- 主体描述——画面中最重要的东西是什么。"一个人在电脑前写代码,屏幕上显示终端命令行界面"比"科技风格"具体得多。前者让 AI 知道要画什么,后者只是一个方向。
- 风格指令——你想要什么视觉风格。水彩、扁平插画、3D 渲染、写实摄影,选一个明确的方向。混合风格(比如"水彩风格的写实照片")通常会让 AI 困惑。
- 构图与视角——俯视、平视、特写、全景。构图决定了画面的信息密度和视觉重心。封面图适合用中景平视,正文配图适合用特写或信息图构图。
- 色调与光线——暖调、冷调、高对比度、柔光。色调直接影响情绪传达。技术类文章适合冷调蓝绿色系,教程类适合暖调橙黄色系。
- 尺寸与比例——16:9 用于文章封面和视频缩略图,1:1 用于社交媒体头像,9:16 用于短视频封面。在 API 调用时直接指定尺寸,比生成后裁剪效果好得多。
通俗讲:写提示词就像给设计师写需求文档——你描述得越具体,返回的结果越接近你要的效果。模糊的指令只会换来模糊的图片。
下面是一个实际的提示词对比:
| 要素 | 模糊版(效果差) | 结构化版(效果好) |
|---|---|---|
| 主体 | AI 工作流 | 一个创作者面对双屏显示器,左屏是图片编辑界面,右屏是视频时间线 |
| 风格 | 好看的 | 蓝绿水彩笔触,柔和晕染,手绘插画风格 |
| 构图 | (没写) | 45 度俯视视角,桌面场景,居中构图 |
| 色调 | (没写) | 主色蓝绿,辅色暖橙,整体明亮柔和 |
| 尺寸 | (没写) | 2000×1125(16:9,博客封面用) |
风格控制与一致性
做内容最怕的不是单张图不好看,而是十张图十个风格。一篇文章里出现水彩图、3D 渲染图和扁平插画图,读者的视觉体验是割裂的。
解决方法是建立风格模板:
- 固定一组风格关键词(比如"蓝绿水彩、柔和晕染、手绘笔触、白色背景"),每次生图都带上这组关键词。
- 用同一个色板(3-4 个主色)贯穿整个系列。颜色是风格一致性最强的锚点。
- 把验证有效的提示词存成模板文件,后续直接复用,只替换主体描述部分。
- 封面和正文图的风格模板要分开管理——封面的文字留白区域、信息密度和正文图不同,但色调和画风要统一。
一个实用的做法是维护一个风格池(比如 40-50 个预定义风格),每篇文章随机抽一个风格,篇内所有图共享该风格。这样既保证了单篇的一致性,又保证了不同文章之间的视觉多样性。
关于配图工作流的完整实践——从单篇配图到批量出图——在《我目前最满意的 AI 配图工作流》里详细拆解了每一步。那篇文章记录了从"一张图调半小时"到"批量出图每张不到 30 秒"的整个过程,包括风格池的建立方法和模板化提示词的具体格式。
批量出图的效率要诀
当你需要为 10 篇文章各配 5 张图时,逐张手动调试会消耗大量时间。批量出图的关键是三个环节的自动化:
模板化提示词:只替换变量部分(主体、章节标题),风格和构图固定不动。一个好的提示词模板长这样:
[风格模板:固定] + [章节标题:变量] + [可视化概念:变量] + [画面重点:变量]
API 调用:通过代码调用 GPT Image 或 Flux 的 API,一个脚本跑完全部图片。以 fal.ai 为例,单张图调用成本约 0.02-0.05 美元,批量 50 张配图的总成本在 1-2.5 美元之间。
质检筛选:批量生成 → 人工快速筛选(5 秒看一张,不合格的标记)→ 不合格的自动换变量重跑。这比逐张精调快得多,因为你把决策点从"每张图都仔细调"变成了"只处理不合格的"。
深入一步:批量出图还有一个容易忽略的环节——图片的 alt 文本。每张图都需要一段描述性的 alt 文本,既是辅助功能的要求,也是 SEO 的重要信号。在批量流程里,alt 文本应该在提示词阶段就规划好,而不是上传后再补。
AI 缩略图:让点击率翻倍的视觉策略
缩略图是内容的"门面"。YouTube 官方数据显示,90% 表现最好的视频使用了自定义缩略图。公众号、小红书的封面图同样直接影响打开率——用户在信息流里决定要不要点进去,通常只用不到 1 秒。
缩略图设计的三个原则
大字少字——缩略图在手机上的显示面积通常只有 3-4 厘米宽。这意味着文字太多根本看不清。3-5 个字就够了,字号要大到在手机信息流列表里一眼能读。很多人犯的错误是把完整标题塞进缩略图——那是标题字段的工作,不是缩略图的。
高对比度——深色背景配亮色文字,或者亮色背景配深色主体。灰蒙蒙的缩略图在信息流里直接被忽略。对比度不够的缩略图,在暗色模式的手机上几乎看不见。一个实用的检查方法:把缩略图缩到 100×56 像素(YouTube 移动端的实际显示大小),如果核心信息还能辨认,就合格。
情绪明确——缩略图只传达一个情绪:惊讶、好奇、紧迫、兴奋。不要试图在一张图里说清所有内容。一个有情绪张力的人脸表情,比任何精美的构图都更能吸引点击。
不同平台的缩略图差异
| 平台 | 推荐尺寸 | 比例 | 关键要求 |
|---|---|---|---|
| YouTube | 1280×720 | 16:9 | 人脸 + 大字 + 高饱和度,移动端只显示 100×56 |
| 公众号 | 900×383 | 2.35:1 | 标题可读 + 品牌色一致,列表页裁切到中央区域 |
| 小红书 | 1080×1440 | 3:4 | 第一张图决定生死,竖图比横图展示面积大 3 倍 |
| B 站 | 1146×717 | 16:10 | 动态封面加分,静态封面需要色彩鲜明 |
AI 缩略图的制作流程
- 确定核心元素:一个焦点词 + 一个视觉主体。"GPT Image 做缩略图"的核心元素就是"GPT Image" + 一张对比效果图。
- AI 生成底图:用 GPT Image 或 Flux 生成不含文字的背景和视觉主体。AI 生成的文字通常不够清晰,文字叠加交给后期。
- 字体叠加:用 Canva、Figma 或脚本叠加标题文字,确保字体加粗、描边、大号。
- A/B 测试:同一内容生成 2-3 版不同风格的缩略图,用 YouTube 的 A/B 测试功能或者在小红书分时段测试,保留点击率更高的那版。
用 AI 做缩略图的详细方法,包括字体叠加、人物抠图和 A/B 测试策略,可以看《用 AI 做 YouTube 缩略图:让点击率翻倍的方法》,那篇教程覆盖了从选题到最终缩略图交付的完整流程。

关键帧与图生视频:静态图变动态
AI 视频生成的当前最佳实践不是"一句话生成完整视频",而是关键帧驱动:先用 AI 生成精确的关键帧图片,再用图生视频工具把静态图变成动态片段。
这种两步法是目前 AI 视频产出质量最高、可控性最强的方法。
为什么关键帧比纯文生视频更可控
纯文生视频(Text-to-Video)的核心问题是不可控——同一段提示词生成五次,五次的构图、角色长相、场景布局可能完全不同。你无法精确指定"人物站在画面左三分之一处,面朝右边"这样的空间关系。
而关键帧驱动的流程把"构图控制"和"运动控制"拆成两个独立可调的步骤:
- 构图控制(图片生成阶段):用图片提示词精确定义画面内容、角色姿态、场景布局。这一步你可以反复调试直到满意——图片生成的成本远低于视频生成,一张图 0.02-0.05 美元,而一段视频通常要 0.1-0.5 美元。
- 运动控制(图生视频阶段):在已经确定好的画面上,只需要告诉 AI"怎么动"——镜头推近、角色转头、背景流动。因为起始画面已经固定,运动结果的可预测性大大提高。
通俗讲:纯文生视频相当于让 AI 同时决定"画什么"和"怎么动",两个变量叠加导致不可控。关键帧驱动把两个变量拆开,先搞定一个再搞定另一个。
关于关键帧提示词的系统写法,《AI 短视频关键帧提示词指南》提供了从分镜脚本到逐帧提示词的完整方法论,包括如何保持多个关键帧之间的角色一致性。
图生视频的提示词要点
图生视频的提示词和图片提示词完全不同。图片提示词描述"画面里有什么",而视频提示词描述"画面怎么变化"。很多人犯的错误是把图片提示词直接复制到视频提示词框里——这只会让 AI 重新理解一遍画面内容,而不是让画面动起来。
有效的视频提示词围绕三个维度:
运动方向:具体描述镜头或物体的移动轨迹。不要写"动态效果",要写"镜头从左向右缓慢平移,背景建筑依次入画"或"主体从画面底部缓缓升起,在中央停留"。方向越具体,结果越可预测。
运动幅度:AI 视频目前的运动幅度不宜太大。微动效果(呼吸感的缓慢放大缩小、光影流动、头发飘动)通常比剧烈运动(跑步、跳跃、转身)更自然。原因是剧烈运动需要 AI 生成更多中间帧,容易出现肢体变形或物理错误。
运动节奏:开头慢、中间快、结尾慢的节奏(类似动画中的"缓入缓出")比匀速运动更有质感。在提示词中可以用"gradually accelerate then slow to a stop"这样的表述来引导节奏。
图生视频提示词的系统化写法,在《图生视频 AI 提示词指南》里有详细拆解,包括不同运动类型(平移、推拉、旋转、变焦)的模板和常见踩坑记录。
PixVerse 实战
在目前的图生视频工具中,PixVerse 是性价比很高的选择。它支持图片输入 + 运动提示词,生成的视频在流畅度和画面一致性方面表现稳定,特别是在人物和场景的一致性保持上做得不错。
PixVerse 的几个实用参数:
- Motion Strength(运动强度):建议从中低档开始,过高容易导致画面变形
- Duration(时长):4 秒的成功率高于 8 秒,长视频建议拆成多段短片段
- Seed(随机种子):固定 seed 可以在调试时获得可复现的结果
PixVerse 的操作入门和进阶技巧,可以参考《PixVerse 视频提示词教程》,那篇教程从账号注册到高级参数调节都有覆盖,包括不同版本(4.5 / 5.0)的功能差异对比。
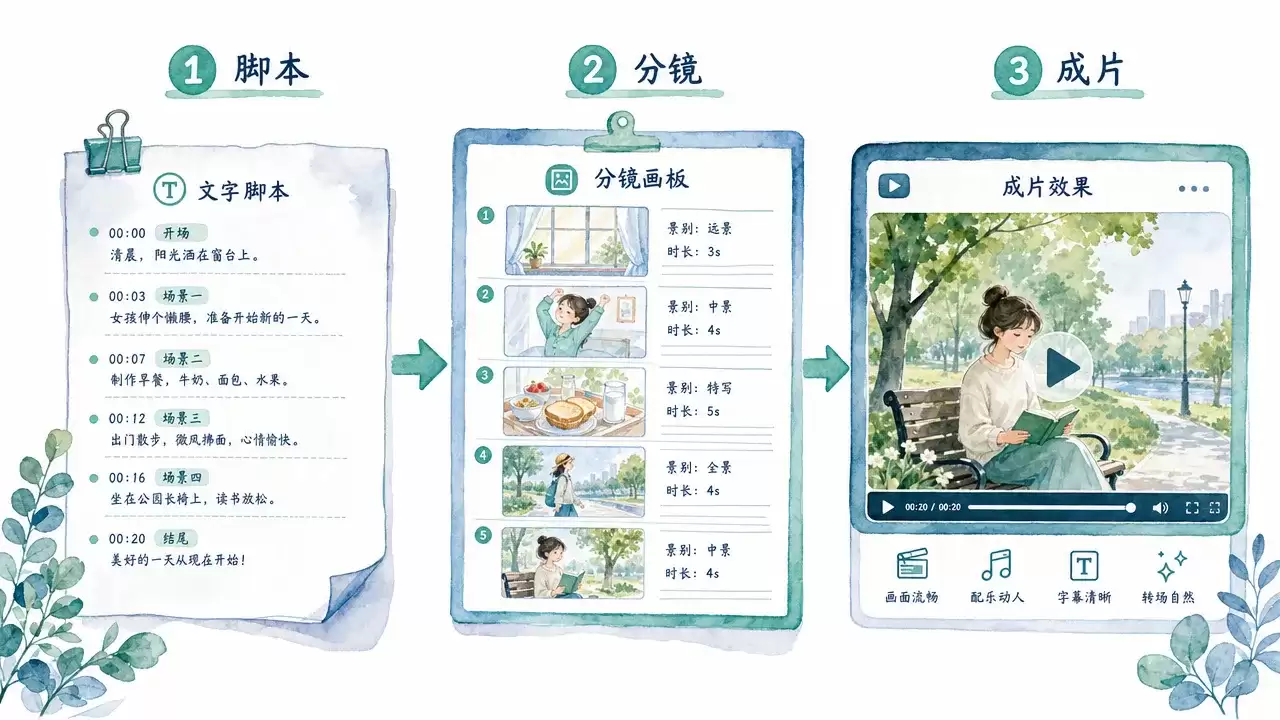
AI 短视频:从脚本到成片
AI 能帮你生成视觉素材,但一条完整的短视频不只是素材的堆砌。它需要脚本结构、分镜设计和剪辑节奏三个维度的配合。好消息是,AI 可以在每个环节提供辅助。
脚本结构的黄金公式
一条 60 秒短视频的脚本结构通常遵循"钩子-正文-行动"的三段式:
- 前 3 秒:钩子(Hook)——一句话抓住注意力。这 3 秒决定了观众是继续看还是划走。有效的钩子通常是一个反直觉的事实、一个惊人的数字或一个视觉冲击。"99% 的人不知道,AI 已经能自动做视频了。"就是一个典型的好奇驱动钩子。
- 5-45 秒:正文——2-3 个信息点,每个点用一个视觉场景承载。注意,不是越多信息越好。60 秒的视频能传达的信息量有限,贪多会导致每个点都讲不清楚。
- 最后 5-10 秒:行动号召(CTA)——关注、点赞、评论,或者引导到长视频/文章。CTA 要具体,"关注我获取更多 AI 教程"比"记得关注"好。
分镜到素材的转化
脚本写完后,关键步骤是把每个场景拆成具体的视觉画面,并标注每个画面的生成方式:
| 时间 | 场景描述 | 素材类型 | 生成方式 | 注意事项 |
|---|---|---|---|---|
| 0-3s | 人物惊讶表情 + 大字标题 | 图片 | GPT Image | 文字后期叠加,不靠 AI 生成 |
| 3-15s | 工具操作屏幕录制 | 录屏 | 真实操作 | 提前准备干净桌面,隐藏隐私信息 |
| 15-30s | AI 生成画面过程 | 视频 | 图生视频 | 用微动效果,避免剧烈变化 |
| 30-45s | 前后对比效果 | 图片组 | AI 生图 | 前后图用同一风格,只变内容 |
| 45-60s | 成品展示 + CTA | 视频 | 剪辑合成 | 叠加半透明关注引导动画 |
一个实用的技巧是:AI 生成的素材和真实录屏交替出现,比纯 AI 素材更有可信度。观众能分辨全 AI 生成的视频,但 AI 素材和真实画面穿插时,整体观感会更专业。
从脚本到最终剪辑的完整流程,《AI 短视频从脚本到剪辑的完整指南》提供了可直接复用的模板和检查清单,包括不同平台的时长和分辨率要求。
剪辑节奏与爆款逻辑
素材齐了,剪辑决定最终效果。爆款短视频的剪辑有三个共性:
- 快节奏切换——平均每 2-3 秒一个画面切换,保持观众注意力。抖音和 TikTok 的算法会监测完播率,前 5 秒不切换画面的视频完播率明显下降。
- 音画同步——关键画面切换点和音乐节拍对齐。这是专业感的重要来源。人的大脑对音画不同步非常敏感,但对同步的音画组合会本能地觉得"质量好"。
- 信息递进——每个画面都比上一个多传递一点信息,让观众觉得"下一帧更值得看"。递进是完播率的引擎——观众不是因为结尾好才看完,而是因为每一帧都比上一帧多给了一点东西才忍不住继续看。
深入一步:剪辑时有一个容易忽略的细节——转场不是装饰,是叙事工具。淡入淡出表示时间流逝,硬切表示场景并列,缩放转场表示因果关系。乱用花哨转场会让视频看起来不专业。
Cherry Studio 在 AI 视频剪辑方面做了不少自动化,包括自动节拍检测、智能转场推荐和字幕生成。它特别适合需要快速出片、不想在剪辑软件里花太多时间的创作者。具体操作可以看《Cherry Studio 爆款短视频剪辑》。
工具选型:主流 AI 视觉工具对比
选工具之前先搞清楚需求。不同工具的强项差异很大,用错工具会导致事倍功半。这一节按"图片生成 → 视频生成 → 工作流编排"三层列出主流选项和适用边界。
图片生成工具
| 工具 | 强项 | 短板 | 适用场景 | 单张成本 |
|---|---|---|---|---|
| GPT Image(gpt-image-2) | 语义理解强、中文提示词友好 | 精确空间布局弱 | 文章配图、概念图、信息图 | ≈$0.02-0.05 |
| Flux(Flux.1 Pro / Dev) | 写实质感、细节控制 | 中文提示词支持一般 | 产品图、人物图、场景图 | ≈$0.03-0.06 |
| Midjourney | 美学风格突出 | API 限制多、批量不便 | 艺术创作、概念设计 | $0.01-0.04 |
| DALL-E 3 | 和 ChatGPT 深度集成 | 风格偏单一 | 快速原型、对话式迭代 | ≈$0.04 |
选择建议:如果你主要做中文内容配图,GPT Image 是首选——它对中文语义的理解在所有模型中最好。如果需要写实产品图或人物照片级效果,Flux 更适合。日常快速验证想法用 ChatGPT 内置的 DALL-E 3 最方便,不用折腾 API。
视频生成工具
| 工具 | 强项 | 单段时长 | 图生视频支持 | 适用场景 |
|---|---|---|---|---|
| PixVerse | 性价比高、图生视频稳定 | 4-8 秒 | 好 | 短视频素材片段 |
| Runway Gen-3 | 运动控制精细 | 4-10 秒 | 好 | 高品质视频片段 |
| Kling(可灵) | 中文生态友好、国内访问快 | 5-10 秒 | 好 | 国内平台视频素材 |
| Sora | 长时长、叙事连贯 | 最长 60 秒 | 一般 | 完整短视频 |
| Veo(Google) | 与 Gemini 生态集成 | 8 秒 | 有限 | Google 生态用户 |
选择建议:多数人的入门选择是 PixVerse——它的免费额度够用于学习,图生视频的一致性表现稳定。需要更高品质时升级到 Runway Gen-3。面向国内平台(抖音、B 站、小红书)发布的内容,可灵在审核合规和访问速度上有优势。
工作流编排工具
| 工具 | 定位 | 学习曲线 | 适合谁 |
|---|---|---|---|
| ComfyUI | 节点式可视化工作流 | 陡峭 | 需要精细控制的进阶用户、批量生产场景 |
| Cherry Studio | AI 视频剪辑 | 平缓 | 需要快速出片的内容创作者 |
| n8n / Dify | 自动化编排 | 中等 | 需要批量自动化的技术用户 |
| 脚本 + API | 完全自定义 | 需编程能力 | 极致效率追求者 |
如果你对 ComfyUI 的部署和使用感兴趣,特别是不想在本地装显卡的情况,《ComfyUI 云端平台指南》对比了几个主流的云端 ComfyUI 平台,帮你省掉硬件投入——对于没有高性能显卡的创作者来说,云端方案是唯一可行的路径。
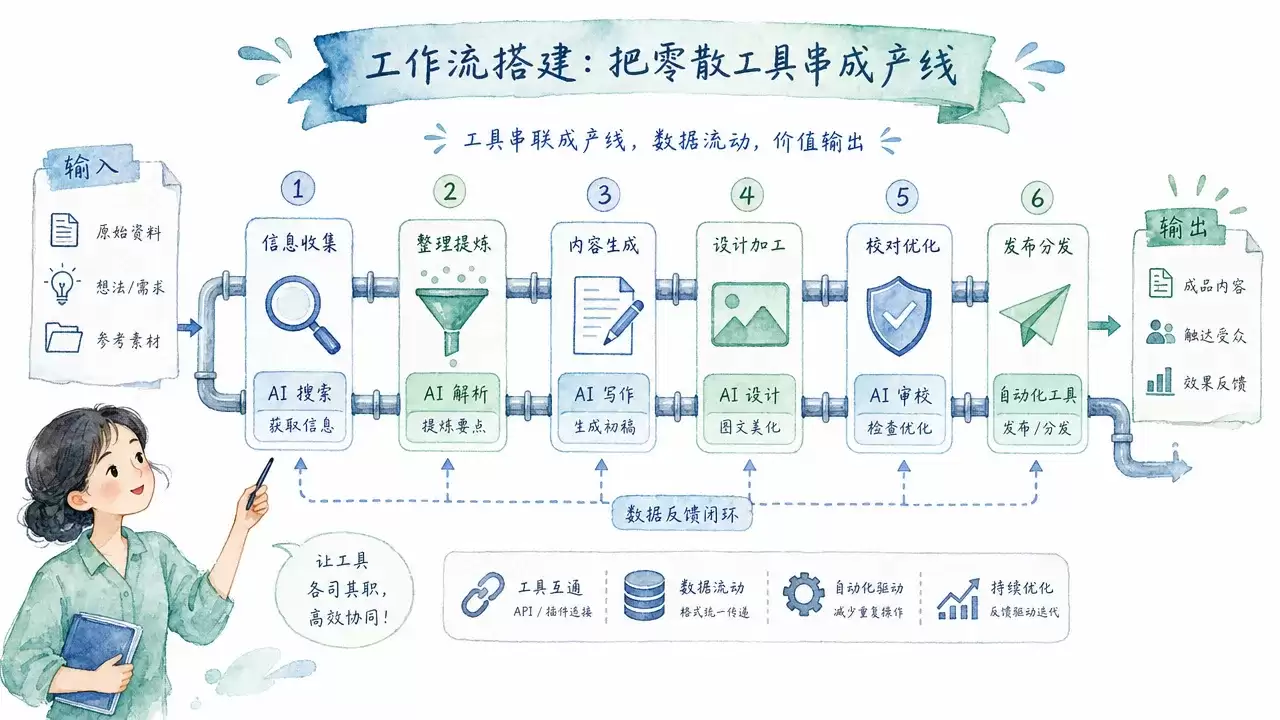
工作流搭建:把零散工具串成产线
工具选好了,下一步是把它们串起来。零散地用每个工具,和搭建一条产线之间的效率差距可以是 10 倍——不是夸张,而是因为产线消除了每次切换工具时的重复操作和决策成本。
配图工作流
适用场景:给文章、公众号、知乎批量配图。
需求分析 → 风格抽签 → 提示词模板填充 → 批量 API 调用 → 质检筛选 → CDN 上传 → 正文回写
逐步拆解关键节点:
风格抽签:从预定义的风格池中随机抽取一个风格。风格池里每个条目包含风格名称(如"蓝绿水彩")和风格描述(如"柔和晕染、手绘笔触、白色背景、蓝绿主色")。抽中的风格应用于这篇文章的全部配图——封面和所有正文图共享同一个视觉风格,保证一致性。
提示词模板填充:把风格描述填入模板的固定部分,章节标题和可视化概念填入变量部分。封面模板和正文图模板分开管理:
- 封面模板:
[风格描述] + [文章标题] + [文章主题概述],强调低信息密度和视觉冲击 - 正文图模板:
[风格描述] + [章节标题] + [可视化概念] + [画面重点],强调与段落内容的相关性
CDN 上传:上传到 Cloudflare R2 或其他 CDN,而不是 Ghost/WordPress 自带的媒体库。自带媒体库的图片加载速度受服务器带宽限制,CDN 分发后全球加载速度快 3-5 倍。上传后把 CDN URL 回写到文章的 frontmatter(feature_image / og_image / twitter_image)和正文图片标签中。
这条配图工作流的完整实现,包括模板文件、批量脚本和质量检查清单,在《我目前最满意的 AI 配图工作流》里有完整公开。
视频批量产出工作流
适用场景:批量生产短视频内容,目标是单人日产 3-5 条。
选题脚本 → 分镜拆解 → 关键帧生图 → 图生视频 → 剪辑模板套用 → 字幕生成 → 导出发布
这条管线的核心优化点是并行化和模板化:
并行化:关键帧生图和图生视频可以流水线并行——上一条视频在剪辑时,下一条的关键帧已经在生成了。图片生成(30 秒/张)和视频生成(2-5 分钟/段)是主要的等待环节,利用等待时间做其他视频的剪辑,整体产能提升一倍以上。
模板化:剪辑模板固化转场效果、字幕样式(字体、大小、位置、颜色)和音乐节拍点。每条新视频只需要替换素材和调整文字内容,不用从零配置。一个好的剪辑模板可以让单条视频的剪辑时间从 30 分钟缩短到 10 分钟。
字幕自动化:字幕用 Whisper 或类似的语音识别工具自动生成,手动校对(改错别字、加标点)远比从头手打快。国内平台还需要注意敏感词替换——AI 生成的字幕不会自动规避平台敏感词。
通俗讲:批量视频产出的本质是把创作从"作品思维"转变为"产品思维"——每条视频不是从头创作,而是在成熟的产线上替换变量。这不是偷懒,而是把精力集中在真正需要创意的环节(选题和核心信息),把重复劳动交给工具和模板。
常见误区
误区一:提示词越长越好
提示词不是越长效果越好。超过 200 词以后,AI 模型对后半段的关注度明显下降。核心信息前置,200 词以内解决问题是更好的策略。
误区二:一个工具通吃所有场景
没有万能工具。GPT Image 在语义理解上强,但不擅长精确的空间布局;Flux 在写实质感上好,但不如 GPT Image 理解复杂的中文指令。根据场景切换工具,比死磕一个工具效率高得多。
误区三:AI 生成的视频可以直接发
AI 生成的单段视频通常只有 4-10 秒,画面里偶尔会出现物理规律不对的地方——手指多一根、文字反转、物体突然消失。这些需要在剪辑阶段处理:裁掉有瑕疵的帧、用转场遮盖、或者干脆重新生成那几秒。
误区四:不需要风格一致性
很多人每张图换一个风格,最终整篇文章的视觉效果像拼贴画。同一篇内容的所有配图必须共享一个视觉风格——同一种色调、同一种画风、同一种构图逻辑。风格一致性是专业感的来源。
误区五:忽略尺寸和比例
不同平台对图片尺寸的要求差异很大。用 1:1 的图片做 YouTube 缩略图会被系统自动裁剪,裁掉的部分可能正好是你的标题文字。生成之前先确认目标平台的尺寸要求。
你的 AI 视觉创作检查清单
每次做 AI 配图或视频时,对照这份清单检查:
图片生成
- ⬜ 提示词包含五要素:主体、风格、构图、色调、尺寸
- ⬜ 同篇所有图片共享一个视觉风格模板
- ⬜ 封面图信息密度低、视觉冲击强
- ⬜ 正文图与对应段落内容直接相关
- ⬜ 图片尺寸符合目标平台要求(封面 16:9、正文 16:9 或按平台调整)
- ⬜ 图片文件大小合理(单张不超过 500KB,加载速度友好)
- ⬜ alt 文本(替代文字)填写完整,描述性自然,不堆砌关键词
视频生成
- ⬜ 先生成关键帧图片,确认构图满意后再做图生视频
- ⬜ 视频提示词描述"运动方式"而非"画面内容"
- ⬜ 运动幅度适中,微动优于剧烈运动
- ⬜ 检查 AI 视频中的物理错误(多余手指、文字反转、物体消失)
- ⬜ 多段视频片段的色调和画风一致
剪辑合成
- ⬜ 脚本结构完整:钩子 + 正文 + CTA
- ⬜ 画面切换频率 2-3 秒一次
- ⬜ 关键切换点与音乐节拍对齐
- ⬜ 字幕自动生成后已人工校对
- ⬜ 最终导出分辨率和格式符合平台要求
工作流效率
- ⬜ 提示词已模板化,只需替换变量部分
- ⬜ 有效的提示词已存档复用
- ⬜ 图片上传走 CDN 而非平台自带媒体库
- ⬜ 剪辑模板已固化转场和字幕样式

这篇指南覆盖了 AI 图片与视频生成的全链路——从提示词结构到工作流搭建。每个板块都有对应的深度教程可以继续深入:
- 图片生成 → AI 配图工作流、AI 缩略图制作
- 视频生成 → 关键帧提示词、图生视频提示词、PixVerse 教程
- 剪辑产出 → AI 短视频指南、Cherry Studio 剪辑
- 工具部署 → ComfyUI 云端平台
找到你当前最需要的环节,点进去看完整教程,然后动手搭你自己的 AI 视觉创作产线。




