2026届后端面试趋势:数据库、Redis、JVM深度考察成新常态
上周刚有位同学结束某大厂后端实习的三轮技术面,每一轮都被反复追问同一个核心模式的问题:
“你提到熟练使用MySQL,那请解释MVCC是如何具体实现幻读解决的”
“你说熟悉Redis,那么在RDB和AOF混合持久化机制下,宕机恢复时究竟会丢失多少数据”
“你表示调优过JVM,那CMS和G1在并发标记阶段的核心差异是什么”
他坦言自己准备了不少后端八股文,但遇到这些追问式问题,当场就卡住了。
回顾近两个月收集的十几位同学的真实面经,一个清晰的趋势已经浮出水面:大厂面试已不再问“Redis有哪些基础数据类型”这类入门级问题了。
2026届的技术面试,在数据库、Redis、JVM这三大核心领域,已经从“了解即可”全面进化到了“必须能画出示意图、讲清并发冲突、算得出具体数据损失”的硬核水平。
这不是面试变难了,而是大厂的筛选标准彻底变了。
为什么数据库、缓存、JVM成了面试“必杀题”
这背后有一个本质逻辑:大厂的核心业务瓶颈,99%都集中在数据层、缓存层和运行时层。
一个典型的高并发电商系统中,订单库扛不住压力是数据库问题;热点商品击穿缓存是Redis问题;服务频繁Full GC导致响应时间飙高是JVM问题。
面试官真正想招的,不是“会用工具的人”,而是线上出故障时,能在一小时内精准定位到问题出在哪一层,并给出有效止血方案的工程师。
过去问“索引失效的场景”,考察的是记忆力。现在问“你在线上真实遇到过索引失效导致的慢查询吗,是怎么复现和排查的”,考察的是你有没有真正踩过坑、解决过问题。
所以这三项技术成为“三连杀”,因为它们正是线上生产故障中最核心的三个重灾区。
三个核心机制深度拆解:别再死记硬背,去理解它
你不需要背诵一百道面试题。你需要真正理解三个关键机制,用一套工程思维把它们串起来。
数据库核心:MVCC不是魔法,而是基于版本链的并发控制
核心原理在于:InnoDB通过隐藏字段、undo日志和Read View机制,实现了不加锁的一致性读。
具体实现方式:每一行数据都包含两个隐藏列——DB_TRX_ID(最近修改该行的事务ID)和DB_ROLL_PTR(指向undo日志中旧版本的指针)。更新数据时不覆盖原纪录,而是生成一个新版本,旧版本通过undo日志链式串联起来。
为什么这样设计:核心是为了解决读写冲突。读操作读取的是“快照版本”,不会阻塞写操作;写操作加行锁,也不会阻塞读操作。这正是高并发场景下读性能不降级的根本原因。
解决了什么问题:在可重复读隔离级别下有效解决幻读问题。配合间隙锁,能保证同一事务内两次范围查询的结果完全一致。

面试官真实追问:如果两个事务同时修改同一行数据,MVCC如何防止丢失更新?
正确答案:MVCC本身不解决写写冲突。写写冲突依赖行锁机制,先获取到锁的事务提交后,后一个事务会发现数据版本已变化,进而触发重试或报错。
Redis核心:持久化不只是备份,更是对恢复时间的数据承诺
核心原理在于:RDB是内存全量快照,AOF是追加操作日志,混合持久化是两者的最优折中方案。
具体实现方式:RDB通过fork子进程,将内存中的全量数据序列化写入磁盘。AOF则将每一条写命令追加到文件末尾,重启时通过重放命令来恢复数据。
为什么这样设计:RDB恢复速度快,但可能丢失最后一次快照之后的数据。AOF数据丢失少,但恢复速度慢,尤其当日志文件很大时。混合持久化在AOF文件中先写入RDB格式的基线全量数据,再追加增量命令,兼顾了恢复速度和数据完整性。
解决了什么问题:让你在宕机后,能根据业务SLA灵活选择可接受的数据丢失窗口和恢复时间窗口。
真实面经问题:如果Redis实例分配了10GB内存,RDB的fork瞬间是否会导致响应变慢?
会的。fork时采用写时复制技术,父进程修改内存页时会先复制再修改,内存压力大时可能触发swap甚至OOM。解决方案:降低fork频率或改用无盘复制。
JVM核心:垃圾回收不是“全自动”,而是“停顿与吞吐的权衡”
核心原理在于:GC算法的演进,本质就是在三个关键指标间做博弈——停顿时间、吞吐量和内存占用。
具体实现方式:G1将堆划分为大小相等的Region,不要求物理连续。标记阶段会记录每个Region的垃圾比例,回收时优先回收垃圾最多的Region(这就是Garbage First名称的由来)。
为什么这样设计:CMS在并发标记阶段会产生浮动垃圾,且内存碎片问题严重。G1通过Region分区和停顿预测模型,能将GC停顿时间控制在预期范围内(比如200ms以内)。
解决了什么问题:大堆内存(几十GB)场景下的可控停顿。以前用Parallel GC,Full GC可能暂停几秒;用G1或ZGC,可以把停顿降到几十毫秒级别。
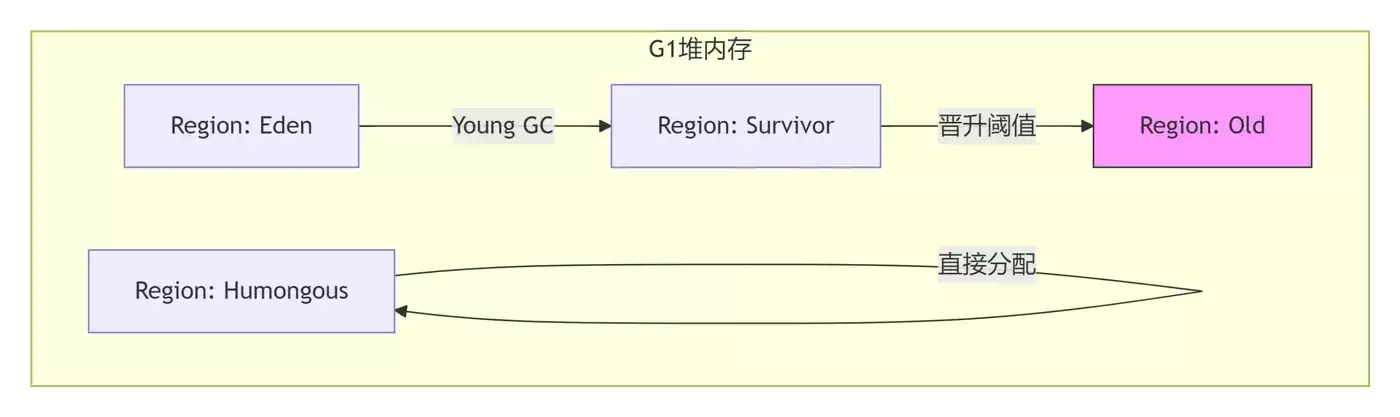
面试官追问:你们线上为什么从CMS切换到G1?
真实回答:CMS的Full GC会触发串行标记,导致线上服务明显抖动。G1的Mixed GC能逐步回收Old区,抖动曲线平滑很多。
一个真实案例:懂与不懂,差距可能差一个数量级
去年某团队遇到线上故障:每天下午3点,订单查询接口的响应时间从20ms突然飙升到3秒,持续15分钟后自动恢复。
不懂的人的做法:重启服务、盲目加机器、怀疑网络问题。
懂的人的做法:先查慢查询日志,发现某个带order by create_time limit 10的查询扫描了50万行。再看执行计划,发现索引用了(user_id, status),但order by字段不在索引中,触发了filesort。最后结合监控发现,3点正好是定时任务批量更新订单状态的时间,大量数据被锁或标记,统计信息失效,优化器选错了索引。
最终解决方案:重建复合索引(user_id, create_time)覆盖查询,把order by变成索引有序扫描。同时设置innodb_stats_auto_recalc为ON,避免统计信息过旧。
从发现问题到定位根因,只用了40分钟。不懂的人可能要重启三次、折腾半天才能恢复。
这个差距,面试时一问便知真假。
你现在能落地执行的三件实事
这些话是说给2026届应届生和初级工程师的。以下三件事不需要进入大厂也能自己做。
第一件事:别只背题,去搭一个会“坏”的本地环境
本地用Docker跑MySQL、Redis和Java应用。写一个脚本故意制造慢查询、缓存穿透和内存泄漏,然后自己动手排查。
怎么制造慢查询:在一个千万行级别的表里用where name like '%xxx%'。怎么制造内存泄漏:在Java里不断往static List里add对象。然后你会真正理解explain怎么读、jmap怎么用、Redis的latency monitor怎么输出关键指标。
第二件事:为每个技术点画一张“故障决策树”
举个例子:Redis变慢了 → 先查slowlog get → 如果没有慢命令,再查info commandstats看哪个命令调用最频繁 → 再查是否频繁fork(看latest_fork_usec)→ 再查是否内存碎片过高(mem_fragmentation_ratio)。
把这棵树画出来,面试时你说“我会按这个顺序系统性排查”,比背十篇技术博客有用十倍。
第三件事:把“为什么这样设计”贴在你桌面上
你不是在学Redis持久化,你是在学“怎么在磁盘性能和数据安全之间做工程取舍”。你不是在学JVM GC,你是在学“怎么用停顿换吞吐、用内存换速度”。
每次学习一个机制,问自己三个问题:
- 它解决了什么核心痛点(如果没有它会怎样)
- 它做了哪些取舍(它没有解决什么问题)
- 如果让我来重新设计,我会怎么改进
这才是面试官真正想听到的工程思维。
你的项目如果挂了,你能自己找到根因吗
回到最开始那个同学的故事。他后来告诉我,面试官给了他一个真实场景题:
线上某接口P99延迟突然从50ms暴涨到2000ms,你只有一台机器的ssh权限,不能重启,不能回滚,你怎么在三十分钟内给出结论:是数据库变慢了、是Redis超时了、还是JVM GC导致的问题?
他当时没能答出来。
接下来这个问题,不要求你立即回答:
你现在写的代码或测试的系统,如果明天上线后出现同样的突增延迟,你有现成的排查工具链和清晰的排查步骤吗?
如果没有,那面试官问的不只是技术——他问的是:你是否真的在工程环境里被真实故障教育过。




