前言
PyTorch是什么?简单来说,它就像深度学习领域的“瑞士军刀”——你需要做一顿大餐,锅碗瓢盆缺一不可;而做深度学习,PyTorch就是那个为你备齐了所有工具的专业工具箱。它把各种现成的操作和模块封装好,让你在研究或开发人工智能时,不必从零开始造轮子,直接拿来用就行。
它的优点很突出:支持GPU加速,运算速度飞快;自动求导机制让模型“自己学会”调整参数。有了它,你就能把精力集中在设计网络和解决实际问题上,而不是纠结于底层计算。
什么是Tensor?
深度学习模型的灵魂是数据,而Tensor就是数据的“通用语言”。无论是图像、声音、视频还是文本,最终都会被转换成Tensor来喂给模型。如果你不会创建和操作Tensor,那几乎等于没踏进深度学习的门槛。
Tensor是PyTorch中的核心数据结构,可以想象成一个“高维数组”。它和NumPy数组很像,但多了一个杀手锏:支持GPU加速。正因为这个特性,它成了深度学习的标配。

举个例子:一张普通图片,本质上是一个二维矩阵(宽×高),再加上颜色通道,就变成了三维的Tensor(高度、宽度、颜色通道)。你训练一个分类模型,输入输出都是Tensor。从数据到模型,Tensor贯穿始终。
torch的导入
在开始之前,先把基础工具请进来。这两行代码是PyTorch的标配,几乎每个项目都会用到:
如果你要处理视觉任务,torchvision里已经打包好了常用数据集、预训练模型和数据变换工具,一行就能搞定:
Tensor的创建

我们来创建张量,从一维到三维,一步步来。
一维、二维
先看一维:就是一个简单的数组。
二维相当于矩阵,比如3行4列:
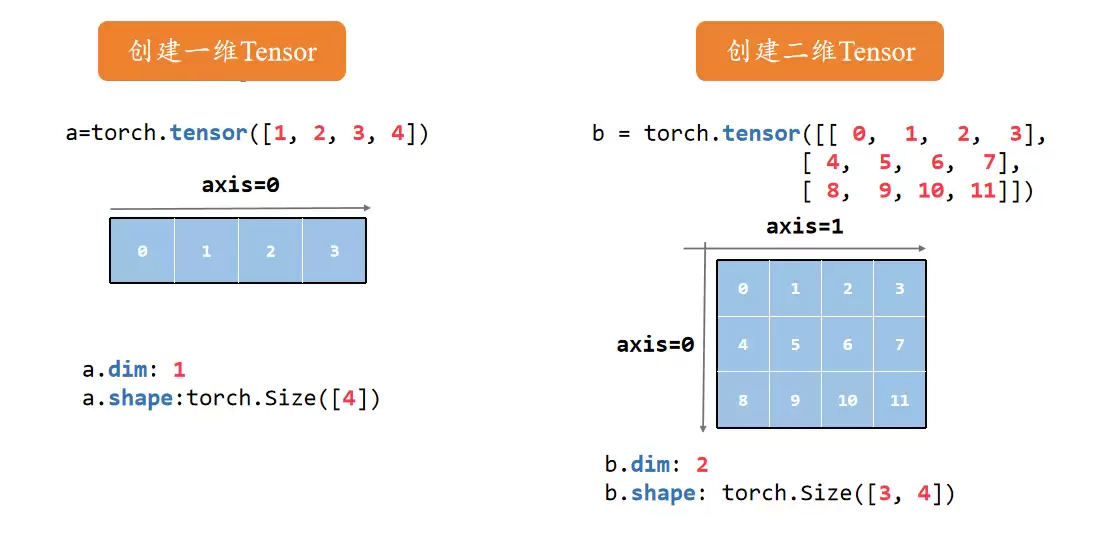
三维
三维张量就像一摞矩阵叠加在一起,比如3层、每层3行4列:

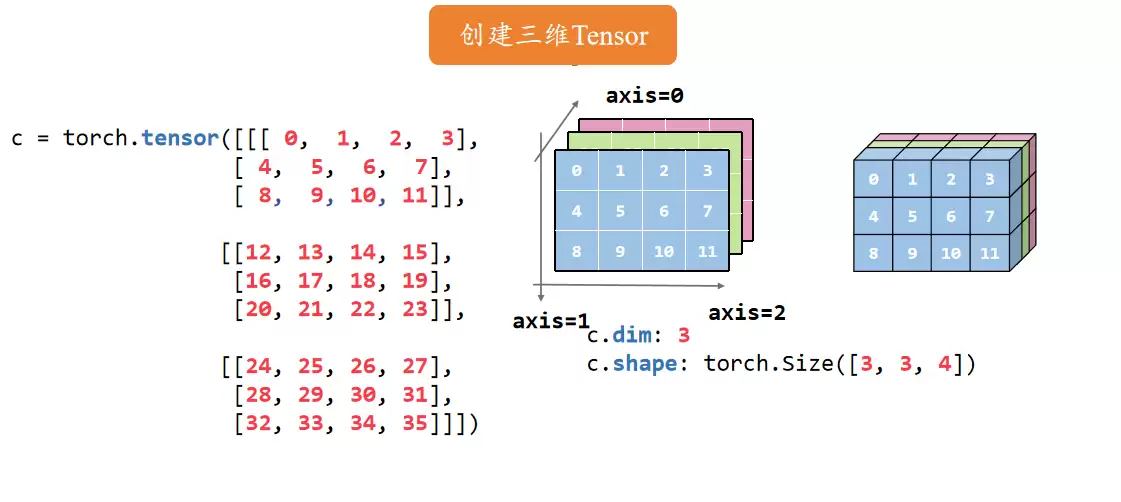

4维张量
假设你现在有3张图片,每张图片用三维张量表示(高度、宽度、颜色通道)。那么这3张图片就拼成了一个四维张量:第一个维度是照片数量,第二个是通道数,第三和第四是高度和宽度。
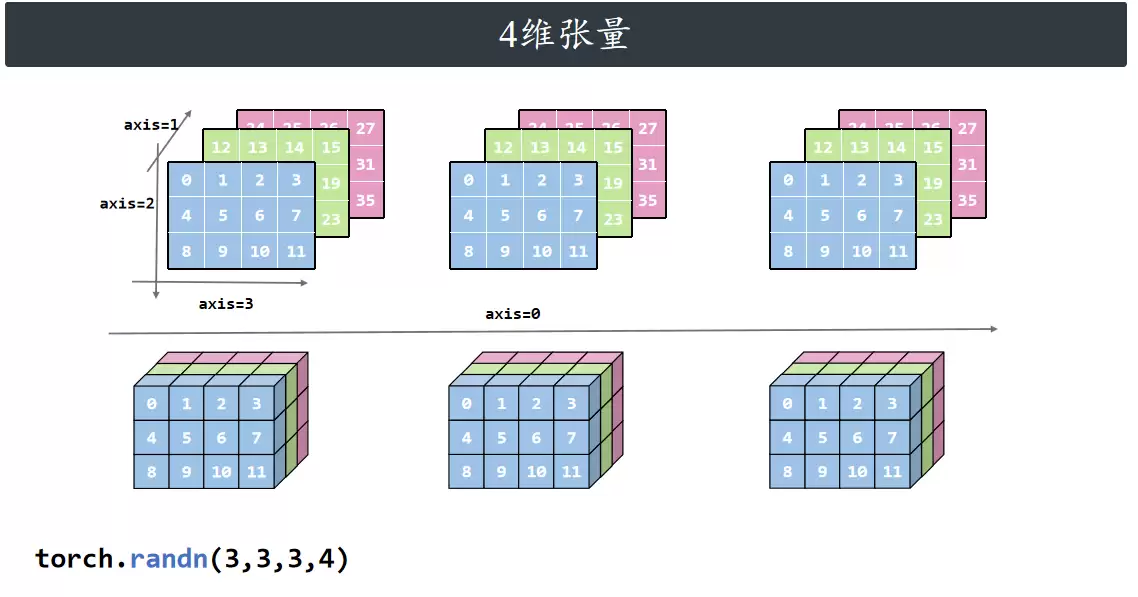

5维张量
再升级:如果你有2个视频,每个视频有3帧画面,每帧又是一张图片的三维表示,那么整个数据就是五维张量:视频数、帧数、通道数、高度、宽度。

Tensor运算
Tensor运算是神经网络进行数学计算的基石。前向传播也好,反向传播也好,都离不开加法、乘法、矩阵乘法、逐元素操作这些基本运算。其实每一次训练,都是Tensor在背后做了一堆数学体操。
举个例子:输入数据先经过各个层之间的矩阵乘法(也就是Tensor运算),得到预测结果;然后计算损失,再用梯度下降更新参数,整个过程每一步都依赖于Tensor运算。
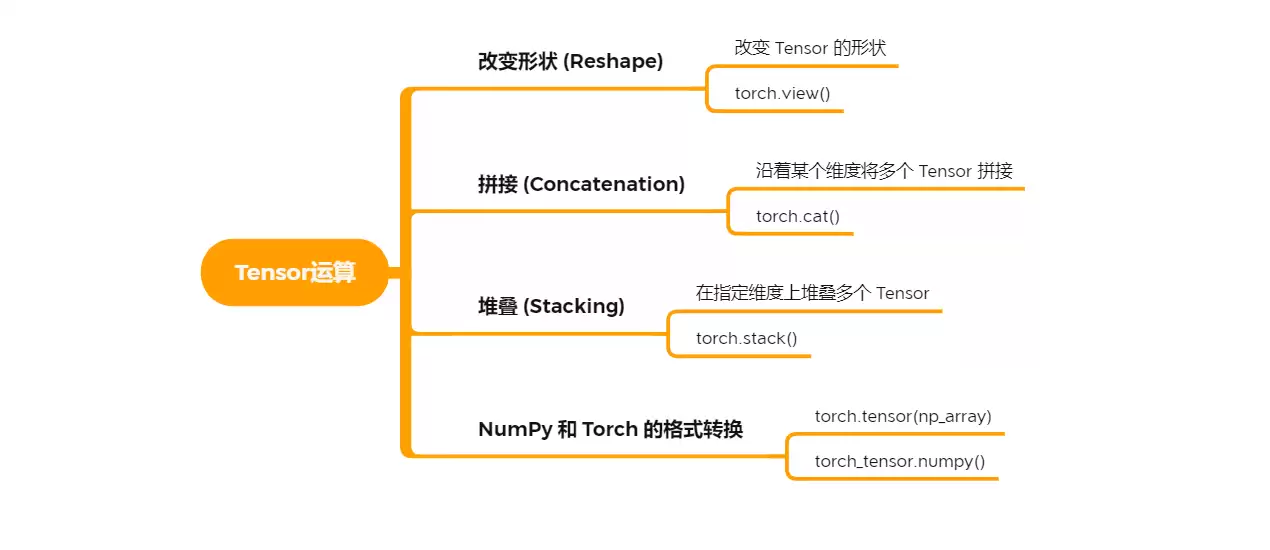

改变形状
用 view() 可以随意改变张量的形状,只要元素总数不变就行:

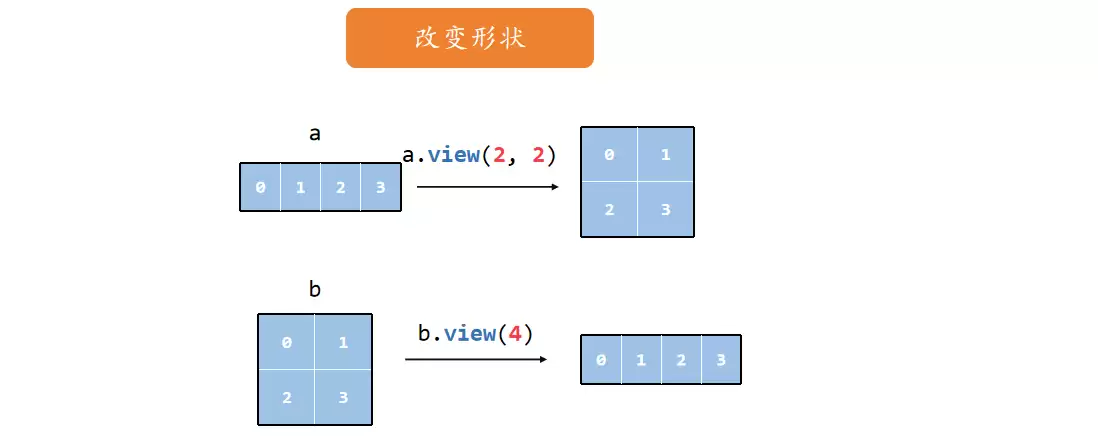

拼接
torch.cat 沿着已有维度拼接,不会增加新的维度。比如把两个2×3的张量沿着行方向(dim=0)拼成4×3,或者沿着列方向(dim=1)拼成2×6:

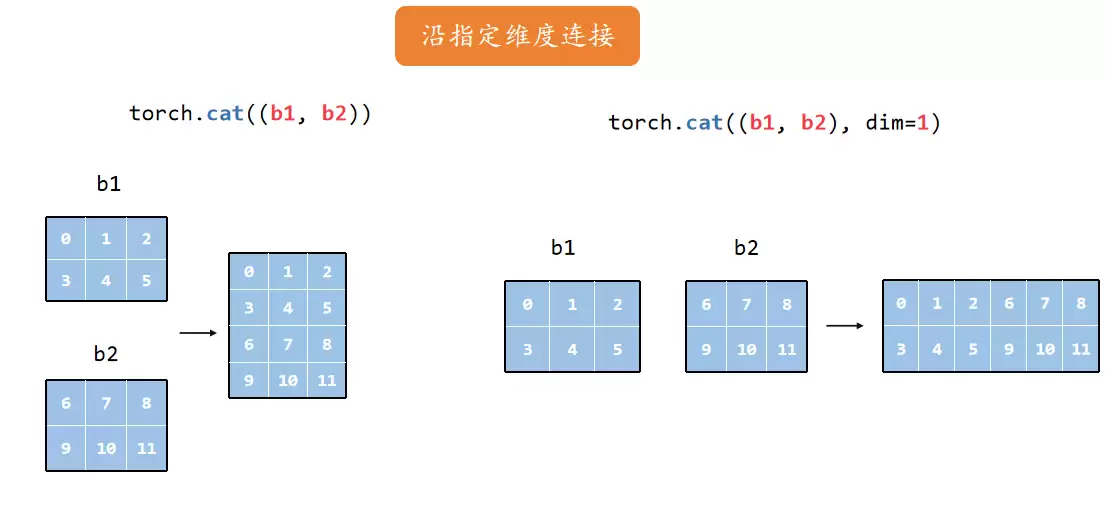

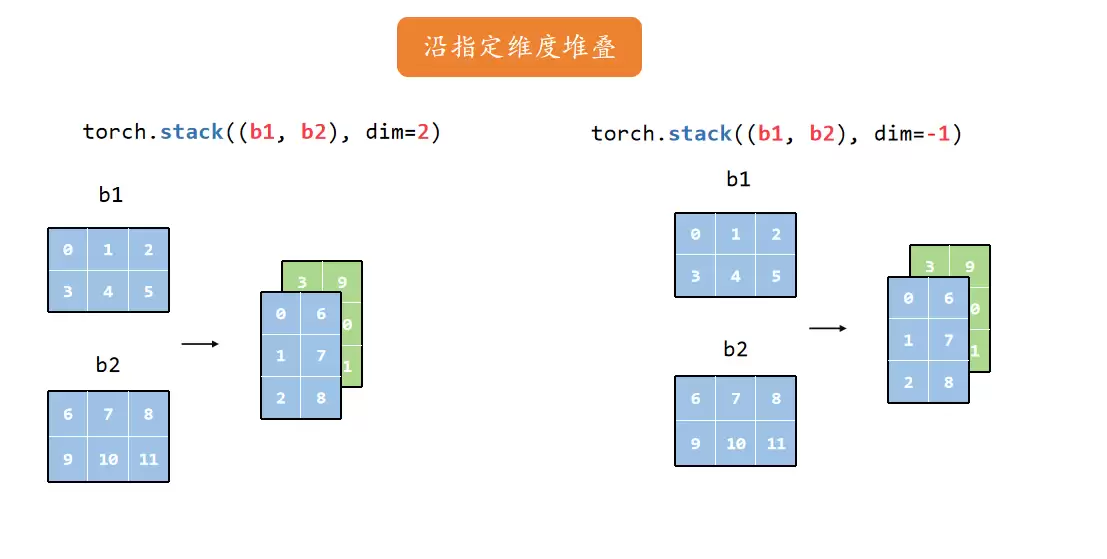
堆叠
torch.stack 则是沿着一个新维度堆叠,它会增加维度。比如两个2×3的张量沿dim=0堆叠变成2×2×3,沿dim=1堆叠变成2×2×3(注意区别),沿dim=2堆叠变成2×3×2。灵活运用就能组合出各种形状。



格式转换
为什么要在NumPy和PyTorch之间来回转换?主要是为了“借力”。NumPy在数据预处理和科学计算上功能丰富,你可以先用它整理数据;处理完后再转成Torch Tensor,送到GPU上加速训练。另外,像SciPy、Pandas这些库也常用NumPy格式,互通起来很方便。而GPU加速是PyTorch的专属福利,NumPy只能在CPU上跑。



层 layer
在神经网络里,层就是构建模型的最小积木。每一层负责把输入加工一下,变成更有用的特征。常见的层包括:
- 线性层(Linear Layer):实现全连接操作。
- 卷积层(Convolutional Layer):专门处理图像的局部特征。
- 池化层(Pooling Layer):压缩特征图尺寸,减少计算量。
- Dropout层:随机让一些神经元“失活”,防止过拟合。
- 归一化层(Normalization Layer):把数据拉回标准范围,让训练更稳定。


神经网络之所以能解决复杂问题,就是因为我们可以像搭积木一样把不同的层堆叠起来,每种层各司其职:有的负责提取特征,有的负责降噪,有的负责增强泛化能力。在PyTorch中,torch.nn 模块已经把这些层都准备好了,直接调用即可。

加载数据
数据是模型训练的燃料。PyTorch提供了两个核心工具:Dataset 负责封装数据,DataLoader 负责批量加载。一般流程是:先用 Dataset 定义好数据(每个样本是一个 (Feature, Label) 元组),然后通过 DataLoader 分批取出。数据通常分成训练集(80%)和测试集(20%)。
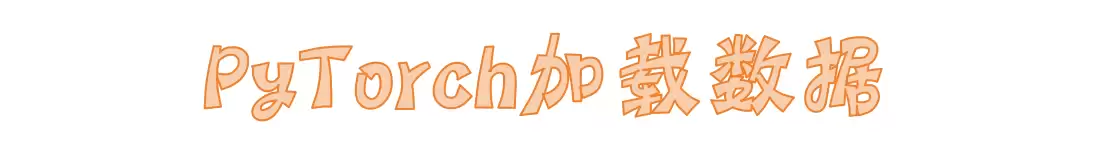


先导入需要用到的模块:

假设我们已经有数据了——100个样本,每个样本5个特征,标签是二分类(0/1)。用 TensorDataset 把它们打包:

接下来按比例划分训练集(80个)和测试集(20个):

最后创建 DataLoader,每次加载16个样本,并且打乱顺序,防止模型学到数据顺序的“偏见”:

把上面几步拼在一起,就是完整的加载流程——先定义数据、划分、再创建加载器:



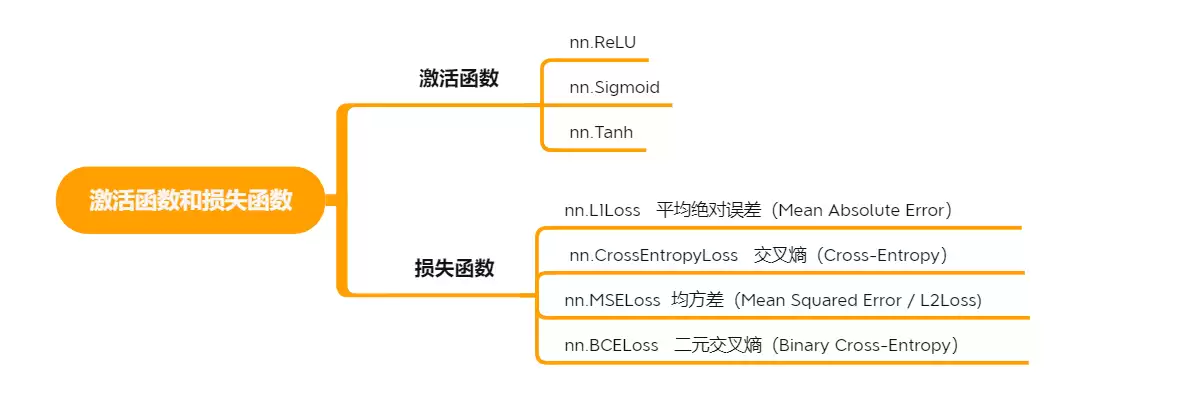
激活函数和损失函数
这两个概念是神经网络的“心脏”和“裁判”。激活函数决定一个神经元该不该“兴奋”,损失函数则告诉网络它预测得有多偏。



激活函数
激活函数的核心作用是引入非线性。如果没有它,整个网络就只会做线性组合,永远模拟不了复杂的函数关系。只有加了非线性,神经网络才能逼近任意复杂函数。最常用的激活函数之一就是ReLU:

损失函数
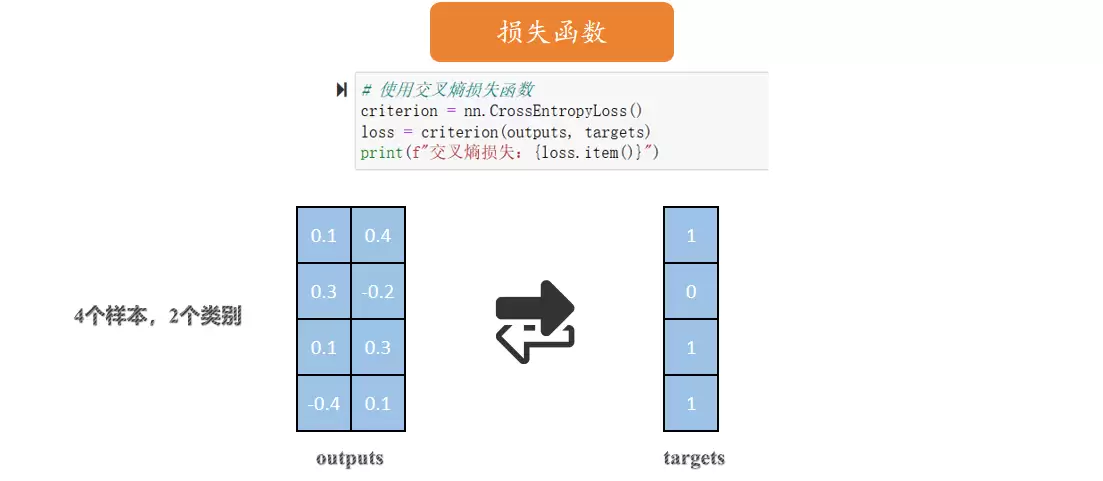
损失函数衡量预测值与真实值之间的差距。训练过程就是不断最小化这个差距。不同任务选不同损失:回归任务一般用均方误差(MSE),分类任务常用交叉熵损失(CrossEntropyLoss)。


保存/加载模型
训练一个模型往往要花不少时间,保存起来以后直接用或者接着训练,是基本功。PyTorch提供了两种主流方式。




保存和加载模型的参数(权重)
这种方式只保存模型的“记忆”——也就是权重和偏置等参数,不保存模型结构。保存时用 state_dict:

state_dict 是一个Python字典,包含了模型所有可学习参数。这是最常用、最灵活的方式:只存参数,体积小,跨版本兼容性好。缺点就是加载时需要自己重新定义模型结构:

总结: 只存参数(state_dict),不存结构。优点是灵活、节省空间、不易有版本兼容问题;缺点是需要手动定义模型结构才能加载。
保存整个模型(包括结构和参数)
另一种方式是把整个模型对象“打包”,结构和参数一起保存:

model.pth 里包含了网络结构和所有参数。加载时只需一行:

这种方法简单方便,拿过来就能用,不用重新定义结构。但缺点也明显:如果PyTorch版本变了,或者代码结构改了,就可能加载失败。所以生产环境中更推荐只保存参数的方式。
GPU训练
CPU和GPU
对于深度学习,GPU是更优的选择。可以这样理解:CPU像5~6个大学教授,样样精通但数量少;GPU像100个高中生,虽然单个能力有限,但胜在人多,特别适合处理大量并行的简单计算——而深度学习里大量的矩阵乘法正是这种场景。


在PyTorch中选择GPU还是CPU,通常分三步走。
Part 1:检查并设定设备

torch.cuda.is_a vailable() 负责探测是否有支持CUDA的GPU存在,返回True或False。然后torch.device() 根据结果选择设备。
Part 2:把模型放到设备上

这一行把模型(包括所有参数)移动到选定的设备上。
Part 3:把数据也放过去

这里inputs是模型输入(比如图片批张),labels是对应的标签。记得也要把它们移到同一设备上,否则模型和数据在不同的设备上会报错。
完整代码连起来:

定义模型
在PyTorch中定义模型主要有两种方式,下面逐一介绍。


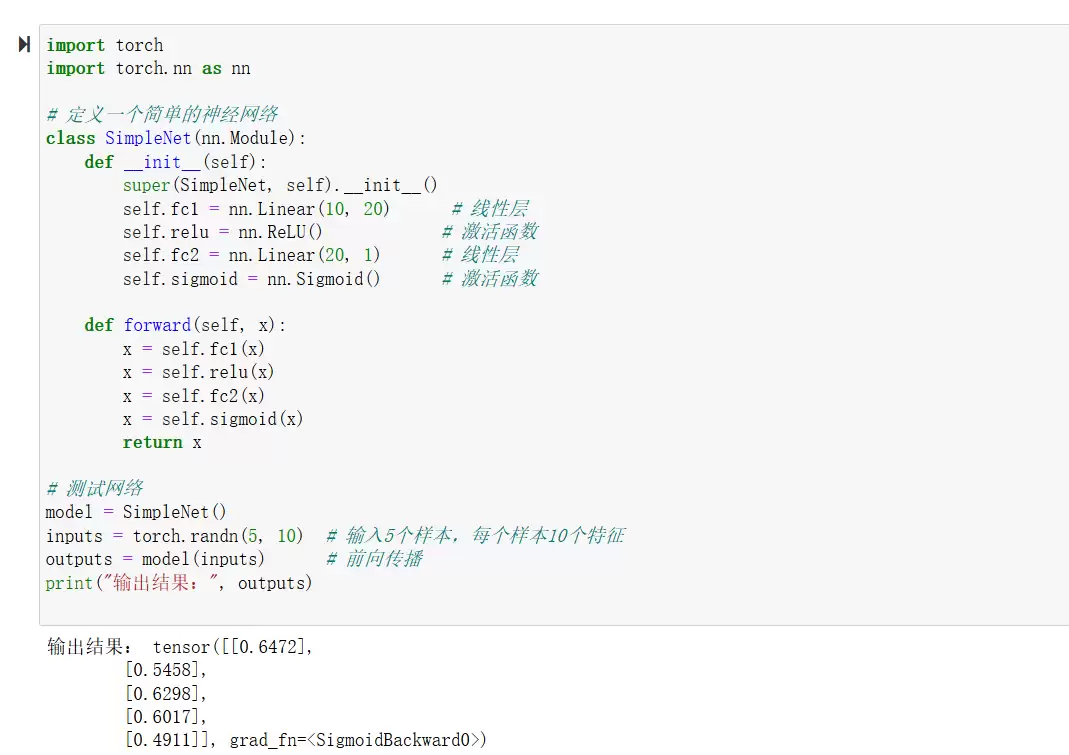
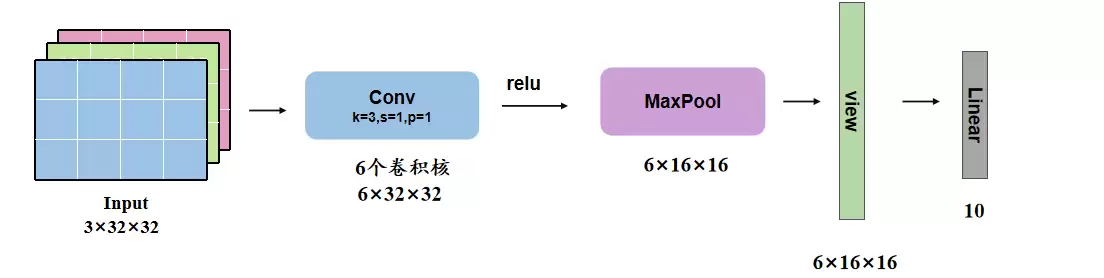
nn.Module类
这是最正统的方式。你需要继承 nn.Module,在 __init__ 中定义各层,在 forward 中编写前向传播逻辑。反向传播PyTorch会自动帮你搞定。




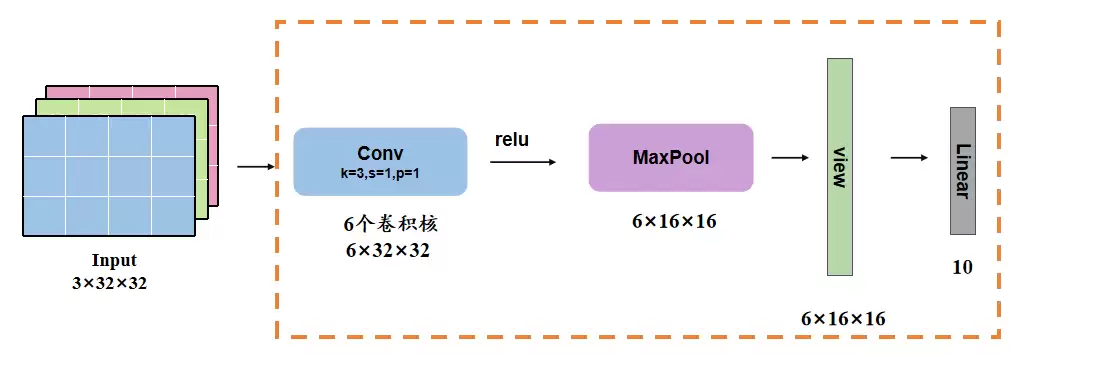
torch.nn.Sequential
如果你希望网络结构是简单的串行流水线,nn.Sequential 会更方便。它就像一个管道,把各层按顺序连起来,数据依次流过每一层。


综合使用
实际项目中,两种方式可以混用。比如用 nn.Sequential 把卷积+激活+池化封装成一个模块,把全连接部分封装成另一个模块,然后在自定义的 nn.Module 里组合它们:

模型训练
torch.optim
torch.optim 包提供了各种优化器,比如SGD、Adam、RMSProp等。优化器的任务就是根据损失函数计算的梯度来更新模型参数,让预测越来越准。以SGD为例:

注意三个关键动作:zero_grad() 清空上次的梯度(防止累加),然后计算损失后调用 backward() 反向传播,最后 step() 更新参数。
训练过程
训练就是反复的循环:把数据喂给模型 → 计算损失 → 反向传播 → 更新参数。每一轮(epoch)都会让模型更适应任务。下面是一个典型的训练循环:

模型评估
训练完的模型好不好,得拿数据说话。评估指标因任务而异:分类任务常用准确率(accuracy)、精确率(precision)、召回率(recall)、F1值;文本生成任务则可能用BLEU。下面是一个典型的评估循环,计算模型在测试集上的准确率:

这里有两个容易忽略的细节:
model.eval()将模型切换到评估模式,让Dropout和BatchNorm等层按评估方式运行。torch.no_grad()禁用梯度计算,测试时不需要反向传播,这样做能节省大量内存和加速计算。




