当前数字化转型已进入关键阶段,企业普遍面临一个现实困境:数据资产日益庞大,但要将其转化为精准决策与高效执行力,却始终受困于“取数缓慢、用数复杂”这两大瓶颈。尽管大语言模型在过去两年发展迅猛,技术路线逐渐清晰,但从“可用”到“可靠”,再到真正实现业务闭环,核心挑战并非模型智能本身,而是整体技术架构的系统性设计能力。
基于各行业的最佳实践,一套成熟的企业级数据智能工作流通常包含以下四个关键环节:
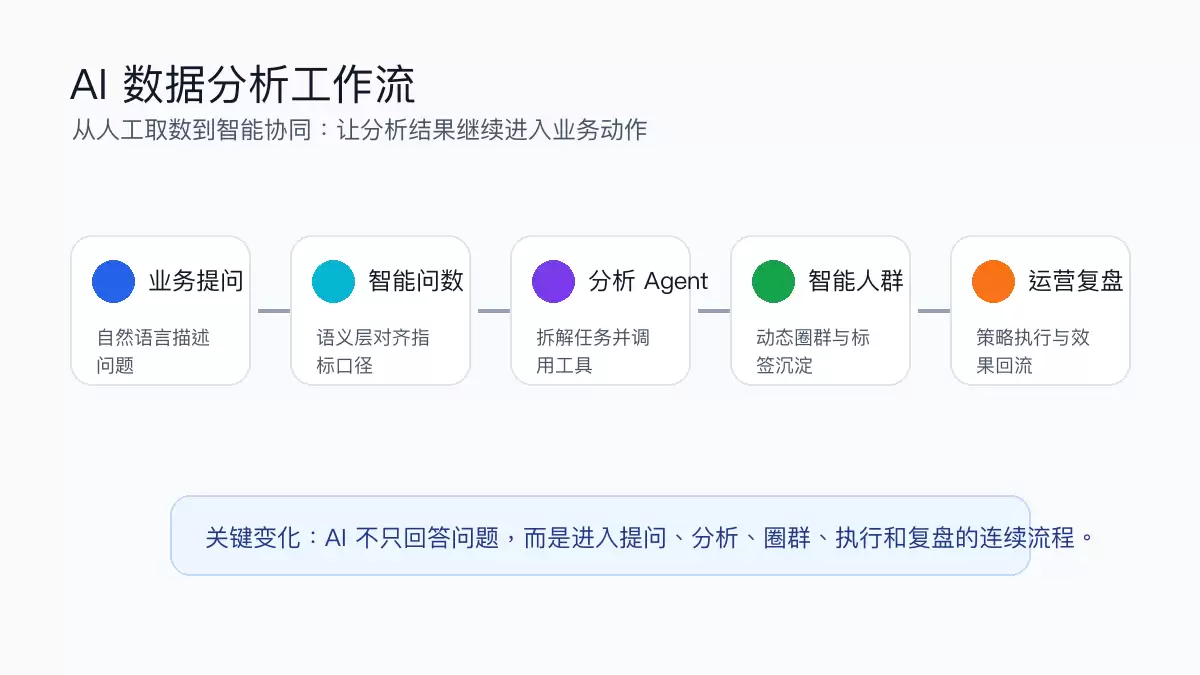 AI驱动数据分析工作流示意
AI驱动数据分析工作流示意
第一阶段:夯实数据底座——质量重于数量
数据质量直接决定了AI分析能力的上限。若输入数据凌乱分散、口径不一致,再强大的模型也难以发挥作用。企业必须建立统一、可追溯的第一方行为数据采集标准与用户画像模型。简而言之,通过严格的数据治理,将原始数据转化为结构化、高精度、语义清晰的“原材料”——这是AI真正能够理解并推理的根基。
第二阶段:构建业务语义层——让AI理解业务语言
传统Text-to-SQL方案的最大缺陷在于“理解断层”:当用户提问稍显复杂或涉及多口径指标时,模型往往难以准确响应。核心解决方案在于建立业务语义层,将自然语言精准“翻译”为标准化指标与事件。以GrowingIO等成熟平台的经验来看,“智能问数”功能之所以能够落地,正是依赖语义层的有效对齐。非技术用户只需提问“最近一周新用户付费转化如何?”——底层系统已自动理解所需口径与事件映射,确保安全性与准确性。
第三阶段:洞察驱动行动——智能人群圈选与策略下发
完成数据分析之后,关键一步是“行动落地”。借助大模型理解业务需求,并结合用户行为轨迹学习模型,将自然语言指令直接转化为动态更新的人群标签。整个流程从产生洞察到触达用户,可缩短至分钟级别,实现人群包同步与多渠道下发的高效衔接。这一环节的核心价值在于,它将分析结果与业务操作紧密连接,避免了分析脱离实际应用的问题。
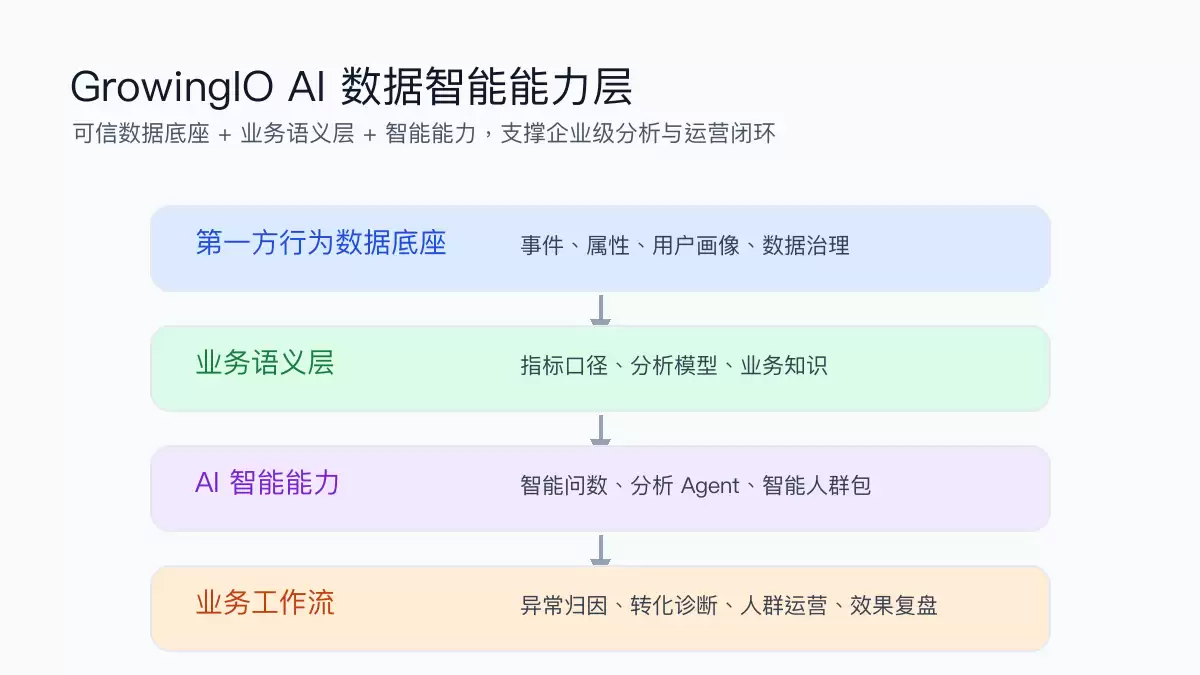 企业级AI数据智能整体架构示意
企业级AI数据智能整体架构示意
第四阶段:分析Agent与知识库——实现复盘自动化流水线
对于长周期、多维度的复杂分析,人工操作往往效率低下。引入AI Agent进行任务分解与步骤规划,已被实践证明是一条可行路径。Agent能够根据业务目标,自主调用增长分析模型,并接入企业知识库与历史经验,实现自动化诊断与复盘。更重要的是,这些分析路径可以被沉淀和复用,形成标准化的可复制工作流。如此,每一次分析都能积累经验,将知识留在组织内部。
以GrowingIO的实际架构为例,其在数据底座之上构建了统一的语义层,并通过分析Agent、企业知识库与任务协同能力,将“智能问数、人群圈选、协同分析、自动复盘”串联成完整的业务闭环。这种“数据底座+AI”的深度融合,既满足了数据安全与权限管理的严格需求,也确保了分析结果的精准性与可靠性,实现了恰到好处的平衡。
必须指出,如果将大模型仅仅视为一个“智能问答工具”,其业务价值将十分有限。只有当AI深度嵌入到“数据采集、语义解析、人群圈选、复盘优化”这一完整生命周期中,企业才能真正开启一条可持续迭代的数据智能发展路径。




