无机材料,堪称诸多尖端技术的“基石”——能源存储、半导体制造、碳捕获、催化等领域,无一不依赖其突破。然而,从浩瀚的化学空间中挖掘一种全新材料,其难度无异于大海捞针。尽管密度泛函理论(DFT)计算堪称精准的“标尺”,但高昂的计算成本使其在大规模筛选中捉襟见肘。
近年来,机器学习原子间势(MLIPs)逐渐崭露头角,成为替代DFT的有力工具。不过,这类模型的性能高度依赖训练数据的质量与规模——数据量需足够庞大,种类需足够多样,方能发挥其潜力。
近期,研究团队发布了名为“开放材料2024”(OMat24)的数据集,堪称当前最大的开放式无机材料DFT训练资源之一。该数据集囊括了超过1.18亿个DFT标注的结构,覆盖周期表中绝大多数元素,并特意纳入了大量远离平衡态的构型。基于此数据集训练的EquiformerV2和eSEN等模型,在Matbench-Discovery基准测试中取得了当前最优成绩,材料稳定性预测的F1分数飙升至0.92以上,形成能预测误差也压缩至约20 meV/atom。
尤为关键的是,研究人员发现OMat24显著缓解了长期困扰机器学习势函数的一个核心难题——所谓“系统性软化”。简言之,模型对能量、受力以及声子性质的预测更加可靠。可以说,OMat24有望成为未来无机材料基础模型与机器学习势函数发展的核心基础设施。
事实上,新材料的发现对于应对能源危机、气候变化以及先进制造等全球性挑战至关重要。但无机材料的组成与结构空间过于庞大,仅靠实验室试错几乎不可能实现。DFT计算虽已成为材料发现的得力助手,但即使借助高性能计算平台,大规模筛选中计算成本依然高得惊人。
人工智能的崛起,使机器学习原子间势成为DFT的理想替代方案。MACE、CHGNet、MatterSim、ORB等模型相继涌现,在能量和力的预测上取得了显著进步。然而,多数模型的训练数据主要来自平衡态或近似平衡态结构,例如Materials Project、Alexandria和MPtrj等数据库。这导致模型在面对缺陷结构、高温结构、界面以及非平衡态体系时,泛化能力明显不足。
研究人员指出,这种数据偏差还会引发一个普遍问题——系统性软化。具体表现为模型低估非平衡结构的能量、原子受力以及声子频率,从而直接影响材料稳定性的判断和热输运模拟的准确性。为解决这一“软肋”,他们构建了OMat24,旨在通过前所未有的数据规模与结构多样性,为下一代材料基础模型奠定坚实基础。
方法
OMat24以Alexandria数据库中约450万个平衡态晶体结构为起点。为捕获更多远离平衡态的新构型,研究人员采用了三种策略:第一种是Boltzmann采样,即对晶体结构施加随机扰动,并根据预测的能量进行筛选;第二种是高温从头算分子动力学模拟(AIMD),分别在1000K和3000K的高温下采样;第三种是扰动后重新弛豫过程中的轨迹采样。通过这一系列操作,他们获得了覆盖更广结构空间的训练样本。
所有结构均使用VASP进行DFT计算,为能量、原子力和晶胞应力打上标签。最终数据集包含约1.18亿个结构,其中训练集约1亿个,验证集500万个,并专门搭建了多个独立测试集,用于评估模型在不同场景下的泛化能力。研究人员利用OMat24训练了EquiformerV2和eSEN等图神经网络模型,并在Matbench-Discovery等标准基准上进行评测。
结果
构建迄今最大的开放无机材料训练数据集
首先来看OMat24的总体规模。该数据集拥有超过1.18亿个DFT结构,比现有的公开无机材料数据集体量大一至两个数量级。与以往主要聚焦平衡态结构的数据集不同,OMat24特别强调非平衡态结构的采样,从而更全面地覆盖真实材料模拟中可能出现的各种构型空间。
统计结果也颇具亮点:大多数结构原子数少于20个,但同时也包含大量来自AIMD模拟的大尺寸晶胞。能量、力和应力的分布范围明显宽于Alexandria和MPtrj,表明非平衡态采样非常充分。周期表中元素的覆盖范围,也在当前公开数据集中名列前茅。
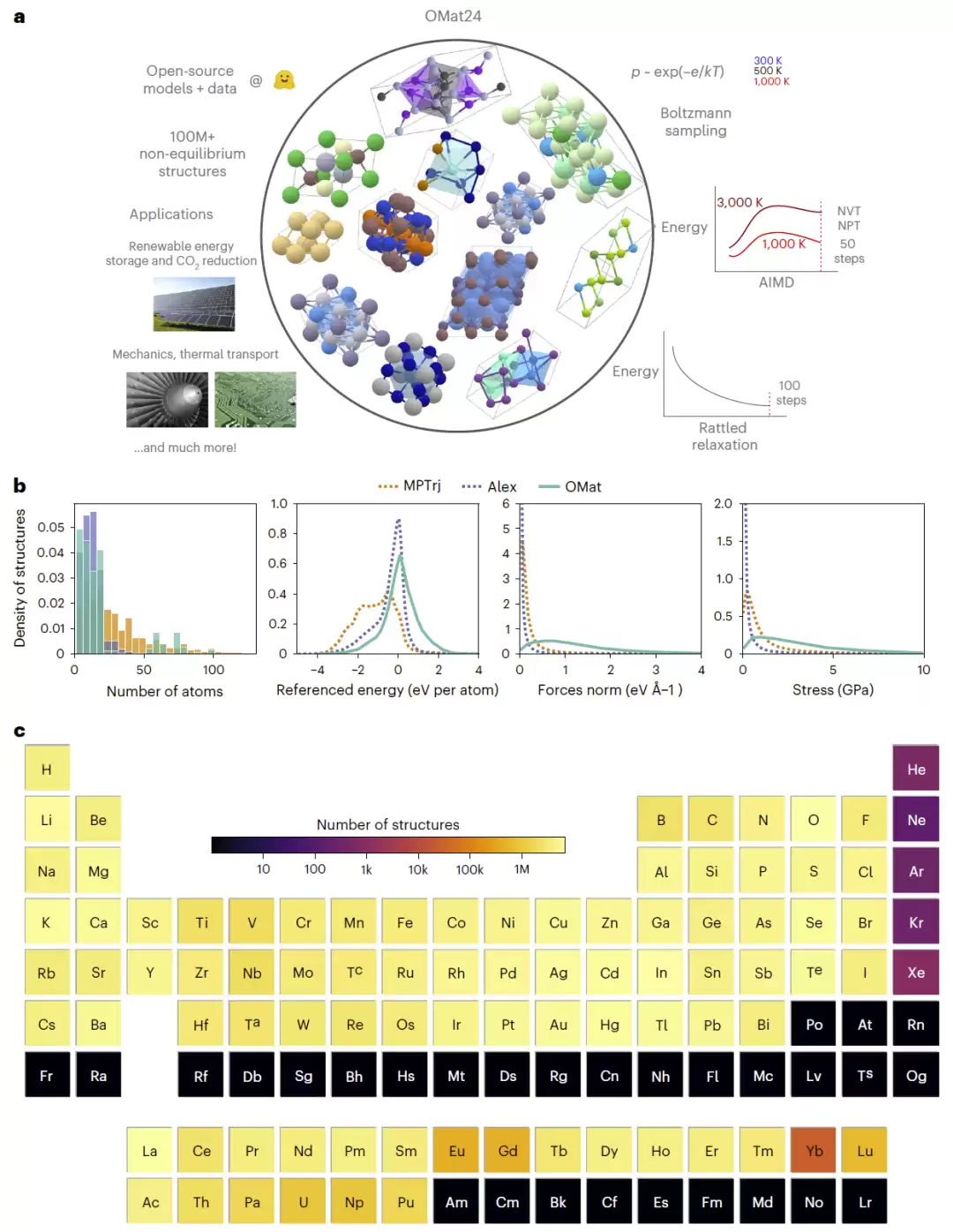
图1:OMat24数据集构建流程、采样策略、结构分布以及元素覆盖范围。
建立严格的数据划分与泛化评测体系
为避免训练集与测试集之间出现数据泄露,研究人员精心设计了多个测试集。
其中,WBM测试集用于与Matbench-Discovery排行榜对标;OOD-Composition测试集用于评估模型对未见组成的预测能力;OOD-Element测试集则专门测试模型对未知元素组合的泛化性能。此外,还单独保留了一个ID测试集用于常规评估。
研究人员强调,相比简单的随机划分,这种设计能更真实地反映模型在材料发现任务中的实际表现。尤其是WBM测试集,分布偏移最大,因此成为衡量模型泛化能力的重要标杆。
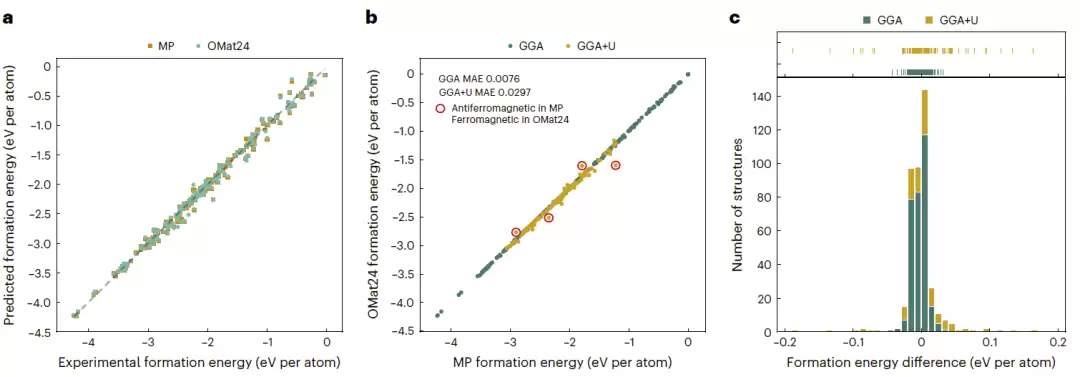
图2:OMat24训练集、验证集及多个测试集划分策略与分布。
OMat24训练模型刷新Matbench-Discovery纪录
研究人员利用OMat24预训练了eSEN和EquiformerV2模型,并在Matbench-Discovery基准上进行了测试。
结果令人振奋:eSEN-30M模型取得了0.925的F1分数,形成能预测误差仅为18 meV/atom,直接刷新了当时公开排行榜的纪录。多个基于OMat24训练的模型同时跻身排行榜前列,表明性能提升并非源于特定模型架构,而是数据集本身的强大能力。进一步分析还发现,即使原本针对催化体系设计的OC20预训练模型,在使用OMat24后也取得了明显进步,证明大规模非平衡态数据对材料基础模型具有普适价值。
研究人员梳理Matbench-Discovery的发展历程后发现,自OMat24公开以来,排行榜前五的模型均使用该数据集进行训练或预训练。可以说,它已成为该领域事实上的核心训练资源。

图3:Matbench-Discovery排行榜性能比较及OMat24模型发展历程。
显著缓解机器学习势函数的系统性软化问题
系统性软化是近年来材料机器学习势函数研究中的一个棘手难题。研究人员从三个层面进行了评估:
第一个是零阶软化,即模型低估非平衡结构能量;第二个是一阶软化,即模型低估原子受力;第三个是二阶软化,即模型低估声子振动频率。
实验结果非常明确:仅用MPtrj训练的模型普遍存在明显的软化现象。但经过OMat24预训练后,无论是eSEN还是EquiformerV2,零阶和一阶软化几乎完全消失。在声子频率预测上,直接使用OMat24训练的模型也表现出最小的软化偏差。
研究人员认为,导致软化的根本原因在于训练数据中缺乏远离平衡态的结构。OMat24通过引入大量高温、扰动和非平衡构型,使模型学会了更真实的势能面形状,从而提升了其对缺陷、界面、表面以及声子性质的预测能力。
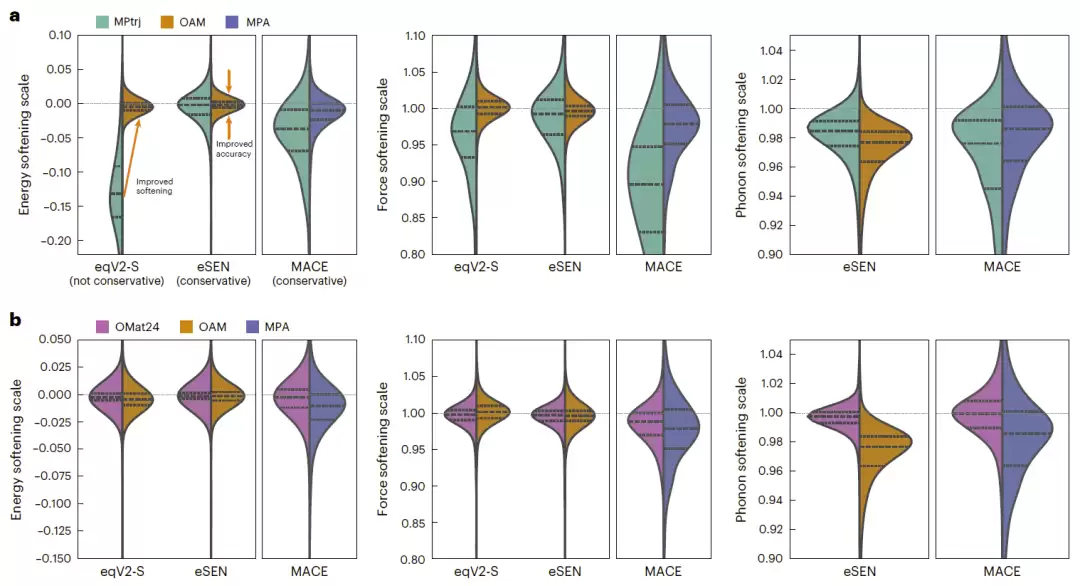
图4:OMat24对能量、力和声子预测中系统性软化现象的改善效果。
讨论
在研究人员看来,OMat24无疑是无机材料机器学习领域的一个重要里程碑。与之前公开的数据集相比,其最大优势不仅在于规模达到亿级,更在于大量非平衡态样本的加入,使模型能够学习到更完整的势能面信息。
研究结果也印证了这一点:OMat24不仅提高了材料稳定性预测的精度,还切实缓解了长期困扰机器学习势函数的系统性软化问题。而且,这种改进在不同模型架构中均能体现,表明数据的质量和多样性可能比模型结构本身更为关键。
当然,OMat24并非没有短板。研究人员坦诚地指出了几点:数据主要基于PBE和PBE+U计算,不可避免地继承了这些DFT泛函的误差;数据集主要包含体相晶体结构,表面、缺陷和低维材料相对缺乏;对于磁性材料,不同磁序的状态也未得到充分考虑。未来,可考虑基于SCAN、r2SCAN甚至更高精度的量子化学方法来构建下一代材料数据集。
不过,研究人员相信,OMat23(注:原文为OMat24,保持一致性)还将推动多保真学习、主动学习、数据压缩以及材料基础模型的发展。正如当年ImageNet推动计算机视觉的变革一样,OMat24有潜力成为无机材料AI时代的重要基础设施,为新能源材料、催化剂、半导体以及量子材料的发现注入新动力。
参考资料
Barros-Luque, L., Shuaibi, M., Fu, X. et al. The Open Materials 2024 (OMat24) inorganic materials dataset and models. Nat Comput Sci (2026).
https://doi.org/10.1038/s43588-026-00996-w





