KubeSphere v4.2.1 正式发布。这次更新诚意十足,没有在花哨功能上做表面文章,而是扎实聚焦于网关平滑演进、多集群协同治理、节点级精细化调度等企业真正面临的实际痛点。从整体来看,一系列增强能力既兼顾了实用性,也稳定了运行稳定性——这才是专业云原生管理平台应有的节奏。
先说说网关的变化。本次版本对网关全生命周期管理架构进行了深度重构,在运维效率、权限管控和可观测性方面都带来了实质性突破。
- 静默式平滑升级
管理员只需在控制台一键触发,网关升级流程便会自动执行。系统按照滚动更新机制分批替换网关实例,整个过程无需中断服务,也无须切换流量。这意味着版本更新、安全补丁、配置调整都不会影响业务运行,真正实现了“零感知升级、无扰式运维”——对于生产环境的高可用网关来说,这一能力可以说是刚需。 - 故障秒级诊断
以往排查网关问题常依赖日志插件扩展,路径冗长迂回。现在运维人员可以直接在控制台实时查看网关工作负载状态和原生运行日志,问题定位从“分钟级”压缩至“秒级”。这一提升对排障效率和人力节约的效果立竿见影。 - 分级流量治理
平台管理员可在集群维度统一规划企业空间级和项目级的网关策略。网关资源能够分层部署,权限实现细粒度隔离。不同业务在入口路由、流量分区、访问控制上的差异化需求都能精准匹配——这才是企业级精细化运维应有的形态。
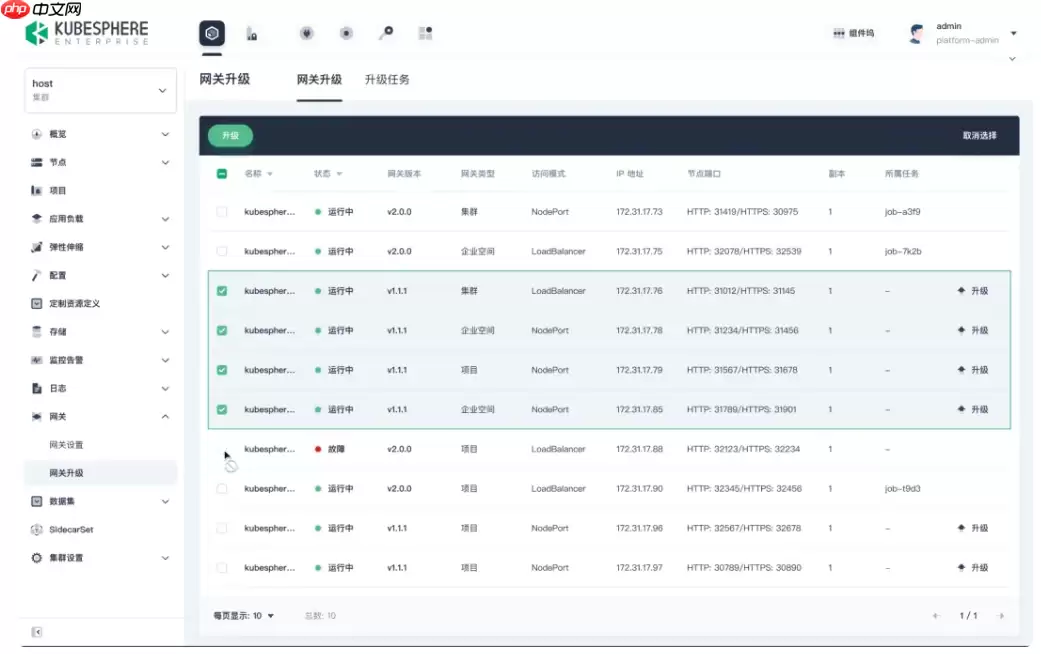
多集群管理一直是 KubeSphere 的优势领域,本次 v4.2.1 在可视化升级和状态一致性保障上进一步强化。
- 成员集群在线版本升级
提供图形化升级界面,多集群批量升级流程一目了然,人工误操作风险大幅降低。同时升级过程中的日志可实时追踪,各集群的升级进度和异常信息都能快速掌控。 - 多集群状态智能同步
集群状态同步引擎升级,新增主动探测机制。离线、失联、异常等状态识别逻辑也进行了优化,跨集群状态数据的高准确率和强一致性有了可靠保证。
接下来重点介绍新增的 节点组(Node Group) 功能。该功能支持将物理机、虚拟机等底层节点按业务逻辑划分为多个逻辑分组,并实现节点组与企业空间的双向绑定。有了这一能力,企业可以面向复杂场景构建更灵活、更可控的资源调度体系。例如:
- 在多团队共用集群、信创环境硬隔离、AI 计算与常规业务混部等典型场景中,核心业务可独占高性能计算节点或专用硬件资源,租户间的资源抢占和性能干扰问题得以彻底解决。
- 节点组的归属关系还能自动聚合资源使用数据,支撑部门级、项目级的精细化成本分摊与核算。
- 公有云节点、私有云节点、边缘节点也可分别纳入独立节点组,构建覆盖异构基础设施的统一资源调度平面。
v4.2.1 还集成了 KubeEye 开源巡检框架,这是一套高度可定制、可扩展的 Kubernetes 集群健康检查能力。用户只需定义好巡检规则和执行计划,集群节点、工作负载、服务组件即可自动进行合规扫描和健康评估,并生成结构化巡检报告。管理员能够提前发现潜在隐患和配置偏差,这比出现问题后再排查要主动得多。
弹性伸缩能力也在本次版本中全面升级。通过融合垂直 Pod 自动扩缩(VPA)、事件驱动伸缩(KEDA)和增强型水平 Pod 自动扩缩(HPA),形成了一套多维度、自适应、低干预的智能资源调度体系。
容器垂直伸缩(VPA)
基于真实资源消耗行为进行智能调优:
- 利用历史 CPU 和内存使用趋势,自动分析并推荐每个容器
requests和limits的最优配置值。这样既能提高资源利用率,又能避免 OOM 或 CPU throttling 等风险,兼顾效率与稳定性。 - 在 Auto 模式下,VPA 可自动更新 Deployment、StatefulSet 等工作负载中 Pod 的资源请求参数,并通过滚动重建方式让新配置生效。
需要注意的是:不建议对同一工作负载同时启用多种伸缩策略,否则策略冲突可能导致调度行为失控。
事件驱动伸缩(KEDA)
它能将外部事件源转化为 Kubernetes 的弹性信号:
- 内置支持超过 80 种 Scaler 类型,涵盖主流消息中间件、数据库、监控系统、云厂商服务以及自定义扩展器,几乎覆盖所有事件触发场景。
- 当事件队列处于空闲状态时,相关工作负载的副本数可自动缩容到 0,彻底释放闲置资源。对于定时任务、突发流量处理等场景,长期低负载业务的运行成本能够显著降低。
- 还支持为同一伸缩目标配置多个事件触发器,实现多条件联合判断下的精准弹性响应。
容器水平伸缩(HPA)增强版
本次升级让扩缩容行为的可控性和鲁棒性都提升了一个台阶:
- 支持独立配置扩容(scaleUp)和缩容(scaleDown)策略,包括稳定窗口期、扩缩速率限制等参数。指标瞬时抖动引发的频繁震荡能被有效抑制。
- 对于 CPU 和内存指标,支持多种目标设定方式:百分比、平均值、绝对值,满足不同业务 SLA 要求。
特别提醒:升级后的 HPA V2 不兼容旧版 HPA V1 的 YAML 定义,需要手动迁移;而且 HPA V1 和 V2 不能共存于同一个工作负载,否则会导致调度冲突。
总体而言,KubeSphere v4.2.1 将 VPA、HPA 和 KEDA 一站式集成,形成了“纵向调优—横向扩缩—事件响应”三位一体的弹性调度范式。在保障业务连续性的同时,资源利用效率、成本优化能力和交付敏捷性都得到了兼顾。
v4.2.1 还围绕异构基础设施统一纳管和数据访问效能提升,面向工程仿真、工业数字孪生、高并发实时分析等典型负载,推出了三大基础能力升级。这些能力可为上层专业调度平台提供标准化、高可靠的算力底座。
- GPU / vGPU 异构算力统一纳管与适配
实现对物理 GPU 和虚拟 GPU(如 NVIDIA vGPU、Intel GVT-g)的自动识别、注册和基础调度。图形渲染、科学计算、AI 推理等多种硬件加速场景均可兼容,推动了异构算力资源的标准化建模和可视化运营。 - 深度集成 Volcano 批量调度引擎
提供面向大规模批处理任务的基础编排能力,支持队列优先级管理、资源配额分配、作业依赖调度等核心功能。对于 CAE、EDA、基因测序等专业调度平台,它相当于一个可插拔的任务调度适配层,能够保障复杂计算任务稳定高效执行。 - NFS 与对象存储本地缓存加速
深度集成 Fluid 云原生数据编排系统,实现 NFS 协议存储和主流对象存储(如 S3、OSS、Ceph RGW)的智能本地缓存加速。通过预加载、热点数据驻留、边缘缓存等机制,远程存储 IO 延迟显著降低,I/O 密集型应用的数据吞吐性能全面提升,高并发读写场景下的系统稳定性和响应效率也得到保障。
上述能力共同构筑起一个更高效、更开放、更贴近企业真实生产需求的云原生基础设施平台。企业无需重构现有架构,即可获得统一、标准、弹性的异构算力供给能力,资源调度智能化水平和整体运营效能都能得到全面提升。
其他关键优化项
- 应用管理:优化了操作超时机制、日志流式加载体验和命名空间配置流程,新增历史部署版本自动清理功能,整体交互更流畅、更可靠。
- 可观测性:支持指标告警和事件告警的持久化落盘;新增 Doris 作为审计日志、事件记录、系统日志及通知历史的后端存储选项;开放了租户级网络拓扑与流量可观测功能权限。
- 资源管理:容器健康探针支持 HTTP 请求头(HTTP Headers)自定义配置;Pod 事件列表支持滚动加载,大数据量场景下的浏览体验更好。




