大语言模型的推理效率,一直是业内关注的硬骨头。传统自回归模型(比如GPT系列)生成文本时一个字一个字地往外蹦,虽然质量高,但速度上不去;而扩散模型虽然理论上能并行生成,却往往卡在双向注意力机制上,没法利用KV缓存这类硬件加速技巧。最近,腾讯微信AI团队放出了一个新方案——WeDLM(WeChat Diffusion Language Model),试图用拓扑重排的思路,把扩散模型和因果注意力捏到一起,效果还真不错。

这个框架的核心妙处在于:它并没有碘伏现有的注意力机制,而是引入了一种拓扑重排策略,让扩散模型的并行生成过程可以自然适配标准的因果注意力。这意味着,KV缓存优化不再被双向注意力卡脖子,硬件加速的效率一下就上来了。更关键的是,这种设计并没有牺牲文本质量——在高难度推理任务(比如数学题、代码生成)上,WeDLM的表现反而让人眼前一亮。
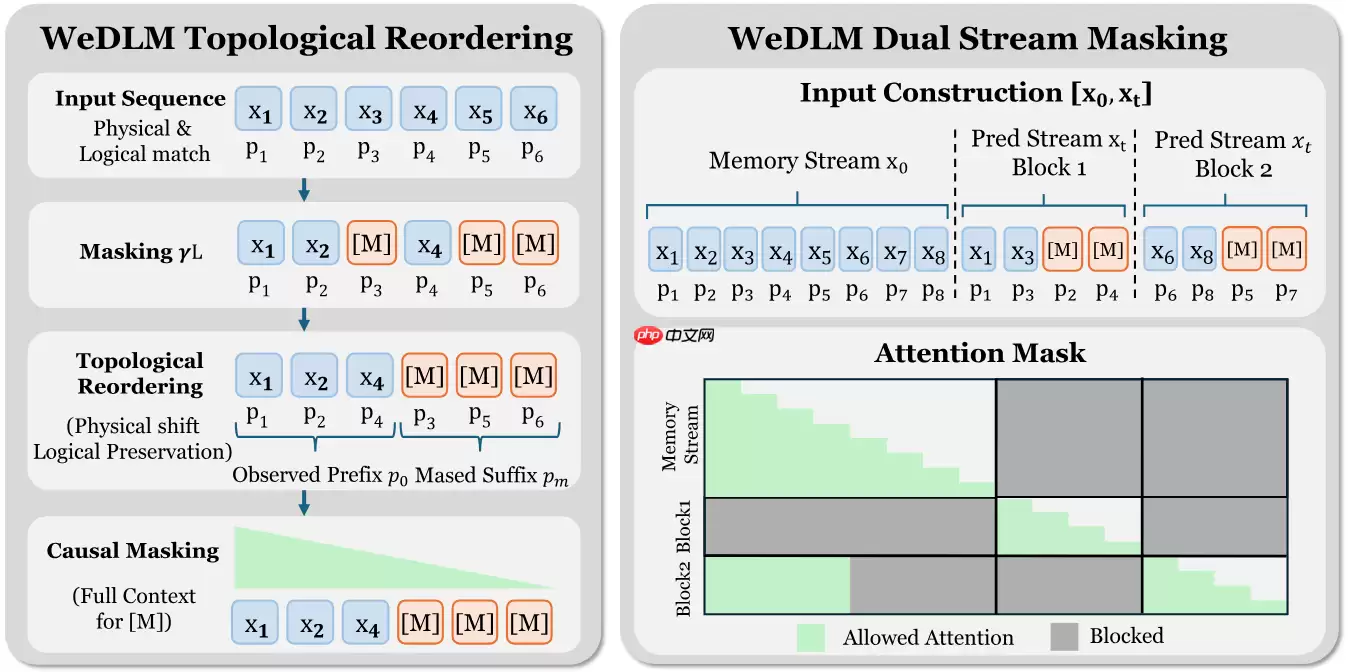
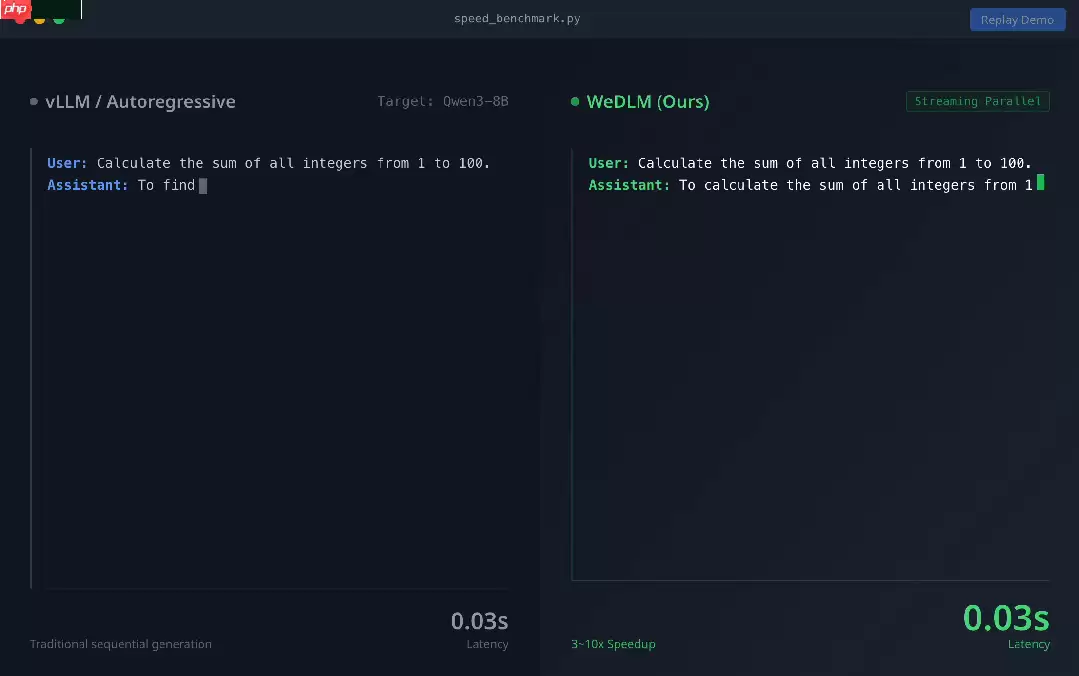
实测性能
- 推理提速明显:在数学推理基准GSM8K上,WeDLM-8B对比经过深度优化的自回归模型(如Qwen3-8B),加速比达到约3倍。而在低不确定性场景——比如数数字这类任务——加速比更是飙到了10倍以上。这已经不是“快一点”的问题,而是质变了。
- 生成质量稳健:在ARC、MMLU、Hellaswag这些权威榜单上,WeDLM的准确率与主流自回归模型基本持平,甚至小幅领先。说白了,就是“又快又不差”,这才是真正有工程价值的方向。
典型应用方向
WeDLM最适合那些对响应延迟敏感、需要高频批量生成文本的场景。比如智能客服对话系统、IDE内嵌的编程助手、即时问答引擎等。想象一下,同样的算力投入,能支撑的并发请求量大幅提升,服务端成本下降,终端用户感觉“秒回”,体验自然上了一个台阶。从实际部署角度看,这模型的竞争力不容小觑。




