一、前言
大型语言模型在企业办公、业务分析、知识管理等场景中正越来越普及,不少公司开始尝试借助通用大模型来辅助日常办公。但在实际落地过程中,大家都会遇到一个共同的挑战:通用大模型根本不了解企业内部的专属数据。公司营收数据、内部规章制度、行业资料、项目文档、最新产品政策——这些信息大模型自身无法获取,自然也就给不出精准的回答。
更棘手的是,直接调用公有大模型还存在三个硬伤。首先是数据隐私安全,核心经营数据、内部机密文档绝不能随意上传到第三方公有平台,一旦泄露后果严重。其次是领域专业度不足,通用大模型对垂直行业的知识积累有限,回答要么过于宽泛要么空洞无力,根本无法贴合企业实际的业务场景。最后是信息实时性差,大模型的训练数据有截止日期,最新的政策、新品动态、业务变化它完全不知情。
而RAG检索增强生成技术,正是应对这些问题的利器。通过RAG架构,可以将企业本地文档私有化地接入大模型——把PDF、TXT、DOCX等文件解析、分块、向量化并持久存储。用户提问时,系统先检索出相关的知识片段,再交给大模型结合私有数据生成答案。这样既能保障数据不外泄,又能让大模型真正理解企业专属业务,实现精准的智能问答。
本文将从零开始,全面讲解RAG核心原理、整体技术架构、环境准备、完整代码实现、多数据源接入、国产模型替换、效果优化技巧以及部署上线方法,全程注重实操落地,助力企业快速搭建自己的私有知识库系统。
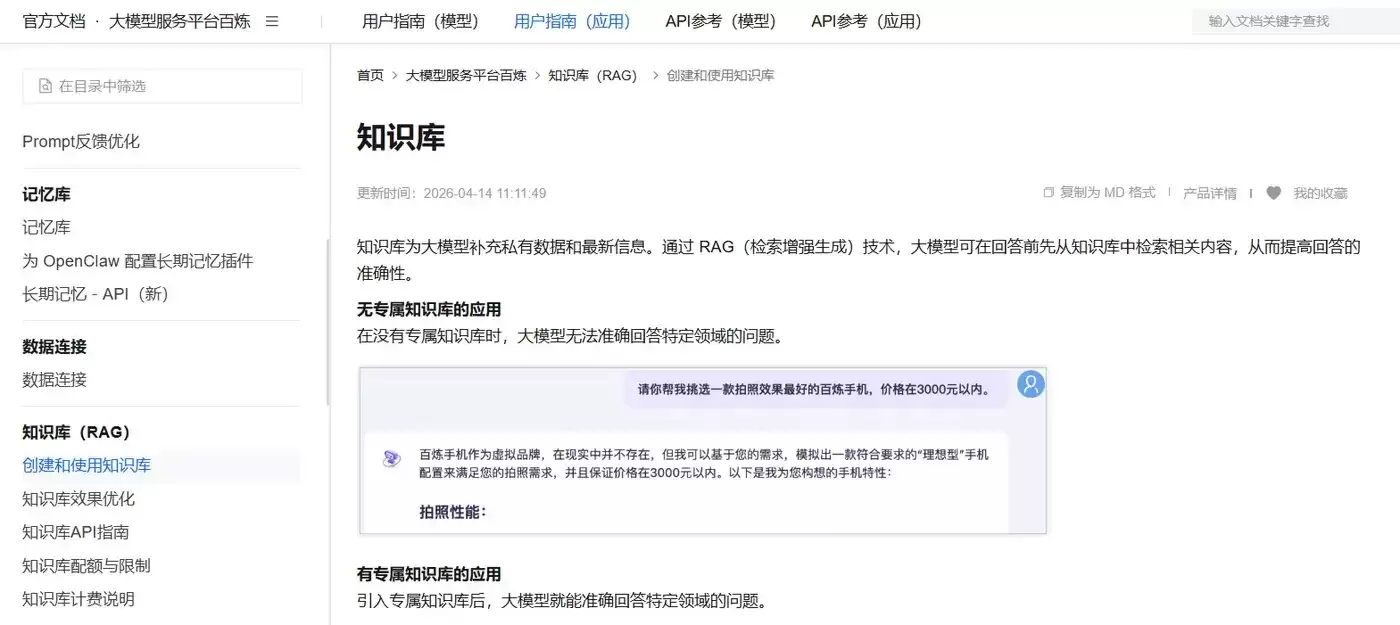
二、企业为什么必须搭建私有RAG知识库
传统模式下,企业直接调用公有大模型接口,只能依赖模型固有的训练知识,根本无法适配内部业务需求。而搭建私有RAG知识库,能从根源上解决三个核心痛点。
第一,保障数据隐私可控。所有企业文档、业务资料全部存放在企业本地或私有服务器中,无需上传第三方公有平台,全程私有化处理,从源头规避数据泄露和合规风险。这对于金融、政务、制造业、互联网等对数据安全要求较高的行业而言,几乎是刚需。
第二,补足领域专业知识。将企业内部制度、行业白皮书、技术文档、项目资料导入系统,让大模型学习专属领域知识,回答就不再是泛泛而谈,内容能够贴合企业业务逻辑与行业规范。
第三,支持实时动态更新。企业最新政策、新产品资料、临时通知等文档可以随时新增入库,知识库同步刷新。大模型能及时掌握最新信息,不受训练时间限制。
除此之外,私有知识库还能实现员工智能问答、新人培训答疑、制度快速检索、项目资料查阅等实用功能,大幅降低内部知识查找成本,提升办公效率。
三、RAG技术核心原理
RAG全称检索增强生成,由检索和增强生成两大核心部分组成。整套运行逻辑清晰明了,是一个标准化的闭环流程:用户提问后,系统不会直接让大模型凭空作答,而是先在私有向量知识库中检索与问题高度相关的文档片段,然后将检索到的内容作为上下文输入大模型,大模型依托私有知识结合自身能力生成专业准确的答案。
简单来说:先把企业所有文档处理成向量存入专属数据库,用户提问时先查找相关资料,再基于这些资料来回答。这就彻底摆脱了大模型凭空编造、不懂业务的问题。整个流程将私有数据与大模型能力完美融合,兼顾了安全性、专业性与准确性。
四、私有知识库整体技术架构
整套企业私有知识库采用标准化流水线架构,分为文档处理、向量存储、检索匹配、大模型生成四个核心环节。
首先是文档接入环节,支持PDF、TXT、DOCX等主流办公文档,也可以拓展接入网页内容、知识库平台资料。接着进行文本分块,将长篇文档拆分成合适大小的文本片段,避免上下文超限。然后通过嵌入模型将文本转化为向量数据,存入向量数据库持久化保存。
用户发起提问后,问题同样先做向量化处理,然后在向量数据库中进行相似度检索,匹配最相关的文档片段。最后将检索结果作为参考上下文送入大模型,由大模型整合信息生成完整回答,形成完整的问答闭环。这套架构逻辑清晰,模块化设计便于后期扩展和功能升级。
五、环境依赖准备
搭建私有RAG知识库需要基于Python环境开发,推荐使用Python 3.10及以上版本。安装相关依赖库即可快速搭建好运行环境。核心依赖包括文档加载解析工具、向量数据库、大模型调用框架、网页部署框架等。依赖安装完成后即可进入代码开发阶段,无需额外复杂配置。
六、完整私有知识库代码实现
基于LangChain框架配合向量数据库,可以快速开发一套支持多文档加载、自动分块、向量存储、智能检索问答的私有知识库系统。代码封装成独立类,包含文档加载、文本拆分、向量库构建、向量库加载、问答链初始化、智能提问等完整方法。
系统支持遍历指定文件夹自动识别PDF、TXT、DOCX格式文件,自动加载解析,异常文件自动跳过并给出提示。可以自定义文本分块大小和重叠长度,适配不同类型文档。向量数据库支持持久化保存,首次构建后下次可以直接加载,无需重复处理文档。同时可以设置检索数量、模型随机性参数,平衡回答的准确性与灵活性。运行后进入交互式问答模式,输入问题即可获取答案与参考文档来源,输入指定指令即可退出程序。
七、拓展多数据源接入
基础版本支持本地办公文档,还可以灵活拓展更多数据源,满足企业多元化的知识接入需求。
可以接入企业官网、行业资讯网页内容,通过网页加载器抓取页面文本,经过分块向量化后纳入知识库,实现官网业务信息的智能问答。同时支持接入Notion等在线协作知识库平台,直接导入平台文档内容,打通云端协作资料与本地私有知识库,实现知识统一管理。多种数据源无缝接入,让企业知识汇聚到同一套RAG系统中。
八、替换国产大模型降低使用成本
默认框架可以接入海外大模型,但调用成本偏高,且存在网络访问问题。可以直接替换为阿里通义千问等国产大模型,适配国内网络环境,大幅降低调用费用,同时更贴合中文语境理解。也可以选择本地开源模型部署,完全脱离第三方接口,实现百分百离线私有化运行,特别适合高度涉密的企业场景。
替换方式非常简单,只需修改模型调用配置,不必改动知识库整体逻辑,兼容性很强,可以按需灵活切换公有接口模型与本地开源模型。
九、知识库效果高级优化技巧
想进一步提升RAG问答的准确率和使用体验,可以从分块策略、检索方式、重排序三个维度进行优化。
首先是定制文档分块策略。不同类型文档采用不同分块规格:技术文档拆分粒度要小一些,保证代码与逻辑片段的完整性;政策制度类文档使用较大分块尺寸,保持段落语义完整,避免拆分破坏上下文逻辑。
其次采用混合检索模式。将向量语义检索与关键词检索结合起来,设置权重配比,这样既能兼顾语义匹配,又能实现关键词精准命中,大幅提升检索相关度。
最后引入重排序机制。初次检索出多条内容后,通过重排模型按照相关性重新打分排序,筛选出最优片段送入大模型,剔除低相关的冗余内容,让回答更加精准凝练。
十、界面搭建与部署上线
开发完成后,可以通过Streamlit快速搭建轻量化网页交互界面,无需前端开发,几行代码即可实现网页版知识库问答。界面包含问题输入框、答案展示区、参考来源折叠面板,布局简洁直观,企业员工直接在浏览器中就能使用。
配置好服务端口后,一条启动命令即可运行项目。本地局域网内均可访问,也可以部署在服务器上供全员共用,开箱即用,部署极其简单。
十一、常见问题排查与解决
搭建和使用过程中,常会遇到检索不到内容、回答不准确、响应速度慢等问题。
检索不到相关内容时,需要检查文档是否正常加载,合理调整文本分块大小,适当增加检索条目数量以提升匹配概率。回答空洞不准确时,可以在提示词中加入角色定位,调低模型随机温度参数,严格依赖检索内容生成答案。响应速度偏慢可以启用流式输出,替换本地嵌入模型,开启缓存机制减少重复计算,从而有效提升响应效率。
十二、总结
RAG检索增强生成技术,是企业搭建私有知识库、落地大模型业务应用的必经之路。通过本文完整的实操流程,可以从零完成环境搭建、代码开发、多数据源接入、国产模型替换、效果优化与网页部署,轻松搭建一套安全、私密、专业的企业智能问答知识库。
整套方案架构轻量化、开发成本低、部署简单。既适合小型团队内部使用,也可以规模化部署供全公司员工共用。既能保护企业核心数据不外泄,又能让大模型深度理解内部业务与行业知识,彻底解决通用模型不懂业务、数据不安全、信息不实时的三大难题。
掌握这套RAG私有知识库搭建方法后,企业可以按需持续新增文档、拓展数据源、优化检索策略,不断沉淀内部知识资产,借助AI能力实现知识快速检索、智能答疑、新人培训、业务辅助,全面提升企业数字化办公与知识管理效率。




