专利这事儿,对很多工程师来说,是个让人头疼的存在。尤其是当老板要求每个人都必须提交一篇发明专利技术交底书的时候——光是看一眼那格式要求,什么关键术语、发明构思、背景技术、现有技术缺点、发明内容(产品侧、技术侧、有益效果)、参考文献……光是理清楚这些名词,就足够让人打退堂鼓了。
核心问题其实一直很清晰:技术方案你手里肯定有,但怎么把它“翻译”成专利语言,才是真正的坎。耗时耗力不说,写出来的东西还大概率被一遍遍打回重写,谁受得了?
之前:专利两字等于头疼
从今年开始,不少团队都面临类似的局面——老板要求每人一篇发明专利交底书。为了交作业,查了一下格式要求,光是看懂那些术语就花了半天,最后还是一头雾水。更扎心的是,你明明有技术方案,却卡在了“怎么写”这一步上,这种挫败感,大概只有经历过的人才懂。
现在:一个 Skill 解决全流程,2个小时帮我完成初稿
好在,工具进化了。有人用 codebuddy 安装了 patent-writing 这个 Skill,直接把项目代码和设计文档扔进去——大约 2 小时后,一份完整的 .docx 文件就出来了。里面包含了:
✅ 头部信息表格(发明名称、涉及产品、保护目的)
✅ 关键术语定义(7个核心概念)
✅ 发明构思(3段,语言风格已符合规范)
✅ 背景技术 + 现有技术缺点
✅ 发明内容:产品侧 + 技术侧(含 S1-S8 完整步骤) + 有益效果
✅ Mermaid 流程图(渲染为 PNG 自动插入)
✅ 参考文献
交到专利袋里人手里,得到的反馈是:「框架完整,语言基本合格,改一遍就能提交。」要知道,以前自己写的初稿,至少要改三遍。

当然,为了让交底书的细节更贴合实际项目,让生成的架构图格式更美观,花些时间做几个版本的微调是免不了的。但放在以前,一个专利小白要写出这么一份专业的交底书,花费的时间和精力,想都不敢想。
Skill 做了什么:三层分工
这个 Skill 背后有一套设计逻辑,不是让 AI 对着空白文档瞎编。核心思路是三层分工:
| 第一层:理解输入 | AI 读代码/文档/图片/描述,找技术方案和创新点 |
|---|---|
| 第二层:写专利语言 | AI 按专利规范撰写各章节,不用技术术语,用专利能看懂的表达 |
| 第三层:生成文件 | 代码引擎把内容写入 Word 模板,输出标准 .docx |
AI 负责“看懂”和“写清楚”,代码引擎负责“输出规范文件”——两者分工明确,互不越界。这种设计思路,其实本身就值得借鉴。
四种输入模式,一个出口
不管你手头有什么素材,这个 Skill 都能接住:
| 模式 | 你给什么 | AI 怎么用 |
|---|---|---|
| A1 代码 | 代码文件或文件夹 | 读代码 → 分析架构、算法、创新点 |
| A2 文档 | PDF / DOCX / PPTX | 提取文本 → 梳理技术方案 |
| A3 图片 | 架构图 / 流程图 | 视觉识别 → 转化为文字描述 |
| B 描述 | 你打字描述的方案 | 直接理解 → 补全技术细节 |
四种模式还可以混合使用——比如同时扔代码、架构图、一份设计说明 PPT,最终汇聚为一份标准专利交底书。

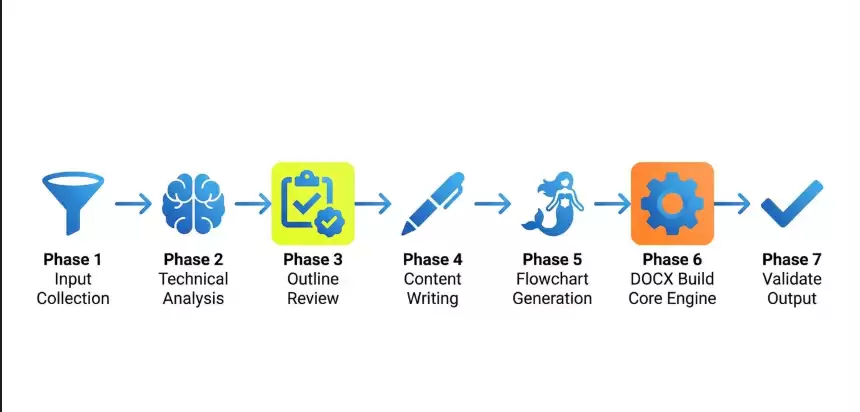
七个阶段,一个关键卡点
整个流程分七个阶段,但你真正需要参与的只有一个——第三阶段:大纲确认。
| ① 信息收集 | 判断输入模式,确认发明名称和保护目的 |
|---|---|
| ② 技术分析 | AI 深度分析:架构、算法、创新点、技术细节 |
| ③ 大纲确认 ⬅ 你参与 | AI 展示各章节要点,你确认后才开始写——这是唯一卡点 |
| ④ 内容撰写 | 按专利语言规范逐章撰写,标记所有数学公式 |
| ⑤ 流程图绘制 | Mermaid 语法 → mmdc 渲染 → 高清 PNG |
| ⑥ 写入 DOCX | 声明式构建引擎自动完成 Word 文件组装 |
| ⑦ 验证输出 | 校验文件可正常打开,告知输出路径 |
第③阶段的价值在于:在文字层面改逻辑,5 分钟搞定;等到 Word 文件生成之后再改结构,至少 30 分钟。卡点设在最前面,代价最小——这个思路,非常实用。
JSON 里怎么描述内容:6 种段落类型
JSON 文件支持 6 种段落类型,覆盖专利文档需要的所有内容形式:
| 类型 | 作用 | 对应内容 |
|---|---|---|
| text | 正文段落 | 步骤描述、说明文字(楷体 10pt) |
| heading | 小标题 | 章节标题(微软雅黑加粗 10pt) |
| formula | 独立公式 | 居中单独成行,右侧带编号(N) |
| inline | 行内公式 | 文字与公式混排(如「其中 x_i 为…」) |
| image | 插图 | 居中图片,支持宽度设置和图题 |
| empty | 空行 | 段落之间的间距控制 |
值得留意的是,数学公式用的是 Office 原生的 OMML 格式,不是 LaTeX——这样输出的 .docx 里,专利袋里人打开 Word 可以直接编辑公式,不需要装任何插件。细节决定体验。

改一个章节,不用重头来
专利袋里人给反馈了,要改第 4.2 节的步骤描述。以前这意味着重新打开 Word,在那一堆格式里找到正确位置,手动改,再检查格式有没有乱。现在?直接打开 patent_content.json,找到对应章节,改那几行文字,重新跑一次构建脚本——3 分钟,输出新的 .docx。
所有临时文件都保留:JSON 内容文件、Mermaid 源文件、解压的模板目录——下次修改直接增量处理,不需要重新分析和撰写。这种“可维护性”,才是工具真正的价值所在。
So What
说到底,专利的门槛可能不在你的技术是不是真创新,而在于那套格式。大多数工程师不是没有值得保护的技术,是被“交底书怎么写”这个问题挡住了。这个 Skill 做的事,就是把格式门槛从“需要学”变成“直接用”。
AI 是翻译,不是发明人。它把你的工程思维翻译成专利语言,但创新点是你的,AI 只是帮你说清楚。
声明式设计让结果可靠。AI 不直接操作 Word 的 XML,而是写一份“要什么”的 JSON,再交给代码引擎执行——这个分工让文件不容易坏,也让每一步可以独立调试和修改。这种思路本身,就值得借鉴。




