过去,当你对机器人说“帮我把毛巾放进洗手池”,它只会机械地执行一串预设动作,完全不理解自己在做什么。如今,G0.5实现了全新的突破:它首先进行思考——毛巾在哪里?洗手池在哪里?应该先拿起毛巾,再移动到目标位置,最后放下。整个过程边思考,边行动。
这一核心能力基于最新的 VLA(视觉-语言-行动)模型架构设计:同一套模型、同一组权重,同时完成推理与动作执行,使机器人具备了“行动中的思考能力”。
言出法随:零样本泛化至新物体、新环境、新指令
G0.5 在 R1 Lite 机器人平台上,实现了零样本操作能力——换言之,模型从未见过当前的场景、物体和指令组合,你只需一句话,它就能实时理解你的意图、拆解动作步骤,并流畅地控制双臂完成任务。
这种“言出法随”的开箱即用能力意味着:一个模型,一句话,直接执行。
从“记住任务”到“学会操作”
过去,机器人学习一项新任务的标准流程是:重新采集数据、重新微调模型、重新适配场景。它能够出色完成训练过的任务,但一旦面对新的物体、新的环境或新的指令,就无能为力了。
通过大规模、多任务预训练,G0.5 形成了可迁移、可组合的操作智能。抓取、放置、推拉、开合、移动这些原子动作,不再是单个任务中的固定片段,而是沉淀为模型可以复用的能力单元。因此,面对新场景、陌生的空间布局和从未见过的物体时,仅凭一句自然语言指令,它就能直接执行操作——机器人真正实现了“边思考边行动”(Think While Acting)。

三大核心能力:让具身基础模型学会“边想边干”
1. 统一异构动作编解码器:用一种“动作语言”覆盖所有机器人
不同机器人的形态、自由度、控制频率千差万别——双臂人形、移动底盘、单臂工业机器人,各有不同的动作维度。以往的做法,要么为每种机器人单独设计一套方案(比如 FAST 使用固定的 DCT 流水线为每种 embodiment 分别离散化),要么将所有自由度拼合成一个大向量再做量化。前者无法跨本体共享知识,后者则导致 token 数量随总自由度线性膨胀——即便当前这一步只是手指微动,模型也得为所有关节生成 token,造成浪费,且语义高度纠缠、迁移性差。
动作 token 本应像语言一样既结构化又稀疏。为此,团队设计了一套统一的异构动作编解码器,让 G0.5 用一套动作词表即可覆盖从桌面双臂到全身移动操作的各种本体。自回归解码带来的额外开销被控制在可接受范围内——这正是将 VLM 重新置于“动作生成者”位置、而非退化为条件编码器的关键前提。

G0.5 Action tokenizer

2. 原生动作思维链:让机器人不仅“边思考边行动”,还能听懂“怎么做”
统一动作词表使 VLM 能够重新回到“动作生成者”的位置。这带来的真正回报是,VLM 在预训练中习得的生成式能力——链式思维、上下文学习、prompt 调制——可以原生作用于动作生成,而无需穿过 VLM-as-Encoder 架构里那个“条件编码”的压缩瓶颈。
在多数现有工作中,链式思维(CoT)仅是训练时的辅助任务,推理模块和动作模块被割裂在两套参数、两个目标中——推理结果要影响动作,必须先被压缩成一段隐状态再传递给下游 expert,中间既有语义损失,延迟也难以控制。G0.5 回归本源,将 CoT 与动作生成融合在同一个自回归流中:模型会先输出子任务分解、目标物体框、2D 轨迹提示等推理结果,然后再输出动作 token。
这套设计带来了两个可分别验证的收益:
▪ 长程任务的零样本分解能力:在 BEHAVIOR-1K 这类需要将自然语言指令拆解成数十个子步骤的家居任务上,单个 G0.5 checkpoint 仅训练一个 epoch 就超过了训练四个 epoch 的 π0.5,也超越了由四个 checkpoint 组成的 Challenge 冠军方案。在预训练分布之外的家居任务上,模型同样能零样本完成子任务分解。
▪ 语言对行为的实时塑造:由于 prompt 直接进入与动作 token 同一条 AR 流,自然语言可以在推理时连续调制动作分布,无需重新训练。一个典型的定性示例是“打开烤面包机开关”任务:由于开关行程较长,仅给“打开开关”指令时,模型的按压力度不足;一旦在指令中追加“push harder”,模型会明显加大下压力度并最终触发开关。

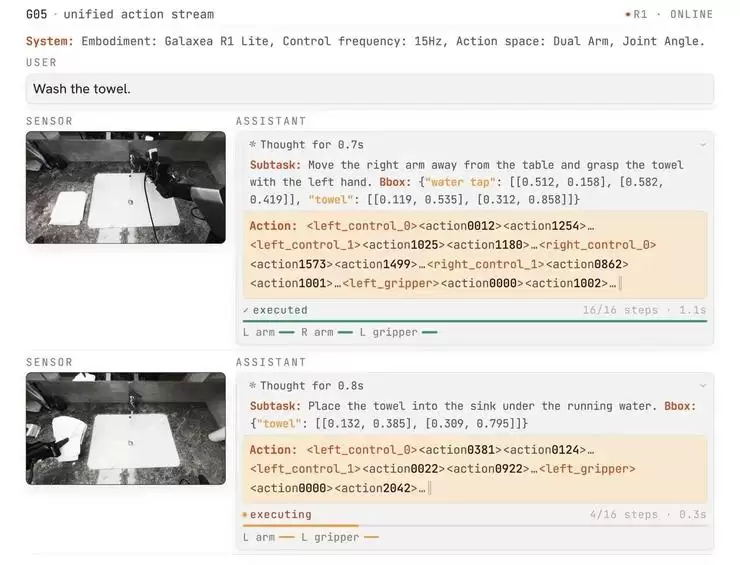 G0.5 在 R1 Lite 上零样本执行“把毛巾放进洗手池”:在同一自回归流中,模型先生成思考(子任务、目标物体框),再输出动作 token,并从每一帧观测闭环重规划。
G0.5 在 R1 Lite 上零样本执行“把毛巾放进洗手池”:在同一自回归流中,模型先生成思考(子任务、目标物体框),再输出动作 token,并从每一帧观测闭环重规划。
3. 时空注意力模块:为机器人注入上下文感知先验
真实的复杂家居任务不能仅依赖单帧画面的“本能反应”。当视线被机械臂短暂遮挡,或任务意外失败时,机器人必须依靠历史上下文才能维持稳定的空间感知。G0.5 配备了轻量级时空注意力模块,融合数秒的历史视觉信息,使模型在局部视野丢失时依然能稳健执行。
实验表明,得益于预训练阶段习得的感知先验,G0.5 在 BEHAVIOR-1K 中“移动箱子到储物间”“装车”“搬木柴”“整理卧室”等长程任务上稳定优于 π0.5。

领跑七大评测场景,全面超越 SOTA
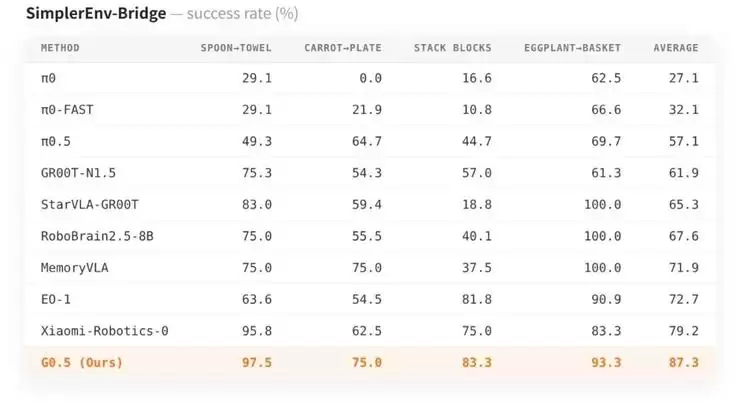
G0.5 在 7 个独立评测场景中全面领先,核心数据如下:



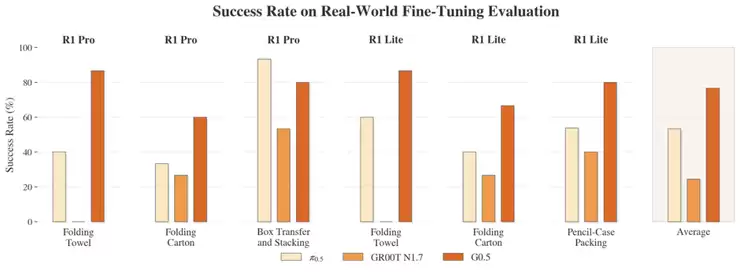

真实世界微调评测:在 R1 Pro / R1 Lite 的六个任务-本体设置上,G0.5(深橙)在成功率与过程分上整体大幅领先 π0.5 与 GR00T-N1.7。

DROID 零样本评测:未经过该机器人微调,G0.5 在 10 个桌面操作任务上平均成功率 82.5%,逐任务均优于 π0.5-DROID 与 MolmoAct2-DROID。
 Pick-and-Place 基准:从零样本到 50 小时训练,G0.5(深色)在“语言跟随率”与“任务成功率”两项指标上,各数据规模均优于 π0.5
Pick-and-Place 基准:从零样本到 50 小时训练,G0.5(深色)在“语言跟随率”与“任务成功率”两项指标上,各数据规模均优于 π0.5
从这些结果中,可以清晰看到几个关键结论:
▪ 大规模预训练使 G0.5 获得了具身基础模型的关键能力。在此基础上,仅需轻量后训练,即可在 7 个基准上超越 π0.5 并取得 SOTA 效果,验证了这一预训练范式的有效性。
▪ 零样本开箱即用。DROID(Franka)和 PP Bench(R1 Lite)两项零样本泛化实验表明,G0.5 的预训练智能可以直接迁移到任何同型号机器人平台和一个全新的环境。
▪ 单模型泛化与性能优势。在 BEHAVIOR-1K 挑战赛的 50 个长程移动操作家居任务评测中,仅凭单一模型权重,G0.5 只需后训练 1 个 epoch(0.29)就显著超越了多模型集成的冠军方案与 π0.5,并在 4 个 epoch 下进一步提升至 0.31,展现出更高的性能上限,超过半数任务表现更优。
▪ 预训练表征克服长程任务瓶颈。这直接验证了:基于结构化动作空间与视觉记忆的预训练先验,才是模型跨越长程移动操作鸿沟、实现高效泛化的核心所在。
结语:从执行动作,到理解世界
G0.5 是具身基础模型的一次重要升级:
▪ 不再把 VLM 当编码器,而是让它重新成为行动者;
▪ 不再割裂推理与动作,而是让模型边思考边行动;
▪ 不再只执行预设程序,而是让模型听得懂“怎么做”、记得住“发生了什么”。
可以确信的是,通用具身智能需要一条可扩展的模型和数据路径。接下来,团队将在更多机器人数据、更复杂的环境、更长的任务时序中继续推进。后续模型开源后,G0.5 也将支持在多种本体上的“开箱即用”部署,助力开发者开展落地实践。




