最近我参加了一场聚焦“机器学习理论前沿”的专题讲座,徐宗本院士在现场分享了一段亲身经历,其中重点提到了他在误差建模领域的核心贡献——徐-罗奇定理。
说实话,这是我第一次系统性地了解这个定理的全貌。听完之后,内心不禁感慨:原来我们一直在使用它,却从未意识到背后竟隐藏着这样一套严谨的数学逻辑。
因此,我想借这篇文章与各位深入探讨一个常被忽视的关键问题——损失函数应该如何选择。
什么是最优损失函数
不妨先设想一个场景:你在玩“扔飞镖”。目标当然是瞄准红心。但风在吹、小狗跑过、还有人推了你一把,总之每次出手都带着一些偏差。

你投了很多次,教练在一旁默默观察,然后给出了判断:
- 有时候你总是偏左;
- 有时候你又突然扔得很远。
这其实对应了一个核心概念——误差分布,也就是你“出错的方式”。
教练想帮你练得更准,该怎么做?他会设计一套评分规则。也就是说,每次扔偏了,都要扣分。如果你经常偏左,那就加重“偏左”的扣分权重,迫使你纠正;如果你偶尔飞得太远,就对“超远偏差”罚得更狠,提醒你控制力度。
这套量身定制的评分方式,就是你个人意义上的“最优损失函数”。
机器学习中的最优损失
在实际执行机器学习任务时,很多人习惯性地指定某类损失函数:分类任务用交叉熵,回归任务用均方误差(L2),偶尔换成MAE或Huber,无非是为了增加一点鲁棒性。
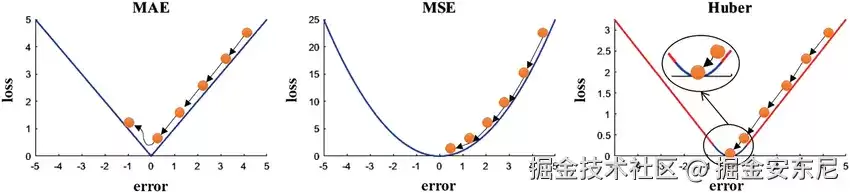
传统的机器学习理论通常会假设一个先决条件:误差服从某类标准分布,比如高斯分布。在这个假设下,均方误差确实是最优选择。
可现实中的问题要复杂得多。数据中可能充斥着噪声,错误来源五花八门:测量误差、标注偏差、系统漂移……在这种环境下仍死守某种固定的损失函数,无异于瞎子摸象。
一句话理解徐-罗奇定理
考虑一个经典的监督学习问题:给定输入 x,输出 y,目标是学习出一个函数 f(x) ≈ y。
假设我们已知误差 ε = y - f(x) 的概率密度函数为 p(ε),那么可以采用极大似然估计来推导损失函数。也就是说,我们要最大化所有样本的联合概率:maxf Π p(y_i - f(x_i)),这等价于最小化负对数似然:minf -Σ log p(y_i - f(x_i))。
这个负对数似然项,恰恰就是我们要最终使用的损失函数。
而这,正是徐-罗奇定理提供的数学基础:它将“误差的概率建模”和“损失函数的选择”统一在一个理论框架中。换句话说,我们可以根据数据实际的误差分布,去理性地设计出最优的损失函数。
小结
这个定理在日常生活中同样具有启发意义。如果你能摸清自己经常在哪些环节出错,那就能找到最适合自己的“评分规则”,学习效率自然会高得多。
举个例子,你练习投篮时,发现左手出手还算稳定,但右手一到关键时刻就偏。这时候一味加大训练量不是好办法,更重要的,是搞清楚右手出错的模式——是不是出手角度有问题?还是站姿不稳?然后针对性地去调整。换句话说,给你的扣分规则,应该对“右手犯错”这一项加重权重。这样练习起来,才能真正又快又准。




