AI 接口上线即翻车?这份实战指南帮你填平那些坑
你花了两周写完AI功能,本地测试流畅无比,满怀信心地部署上线。结果呢?用户一多,接口开始超时,前端白屏;高并发下疯狂报错 429 Too Many Requests;偶发性 503 Service Unavailable,日志一片飘红。老板发来消息:“你这什么破玩意儿?”
这个场景是不是很熟悉?说实话,AI 接口和普通 REST 接口完全是两回事——高延迟、多限制、不稳定是其三大先天缺陷。如果不做工程层面的防护,翻车几乎是必然的。下面这套方案涵盖 Java 和 Python 两种技术栈,拿走即用。
AI 接口的三大天敌
为什么 AI 接口如此难以伺候?先看看几个典型场景。
超时问题:普通 REST 接口通常在 100ms 内返回,但 AI 大模型接口的耗时完全是另一个量级:GPT-4 单次非流式问答需要 8~30 秒,Claude 长文生成 15~60 秒,本地 Llama 推理甚至可能达到 5~120 秒。而大多数 HTTP 客户端默认的超时时间只有 5~10 秒,远远不够用。
限流问题:各大 AI 服务商对调用频率都有严格限制。例如 OpenAI GPT-4 免费额度仅 3 RPM(每分钟请求数),即便付费也才 500 RPM;Anthropic Claude 免费 5 RPM;国内百度和阿里的免费额度更是只有 2 QPS 和 1 QPS。
429 错误:这正是限流的具体表现。收到 429 响应时,HTTP 头通常会携带一个 Retry-After 字段,告诉你需要等待多久才能重试。类似这样:
HTTP/1.1 429 Too Many Requests
Retry-After: 30
这三个问题,任何一个没处理好,线上都会崩溃。下面逐个击破。
超时问题:完整解决方案
合理配置超时时间是最直接的应对方法。关键是把读取超时(readTimeout)调大到 120 秒,而不是默认的 5~10 秒。
Java 使用 OkHttp 时,可以这样配置:
OkHttpClient client = new OkHttpClient.Builder()
.connectTimeout(10, TimeUnit.SECONDS)
.writeTimeout(30, TimeUnit.SECONDS)
.readTimeout(120, TimeUnit.SECONDS)
.build();
如果用的是 Spring WebClient,配置方式也类似,需要同时将连接超时和响应超时设置为 120 秒。
Python 这边,建议直接用 httpx 替代 requests,因为 httpx 支持异步和流式。配置方法:
client = httpx.Client(
timeout=httpx.Timeout(
connect=10.0,
read=120.0,
write=30.0,
pool=5.0
)
)
流式输出才是解决超时问题的根本方案。非流式调用需要等模型生成完整内容再返回,一次性等待 30 秒;流式调用则是边生成边返回,首字节延迟只需要 1~3 秒。用户体验的天壤之别就在这里。
Java 实现流式 SSE(Server-Sent Events)时,用 WebClient 的 bodyToFlux 方法即可;Python 用 OpenAI SDK 的 stream=True 参数,配合 yield 逐块推送。
别忘了前端也要兜底。前端设置 120 秒的超时,超时后中断请求并提示用户“AI 正在思考中,请稍等或重试”。这样即使后端出了意外,用户也不会卡在白屏上。
限流问题:令牌桶 + 重试的组合拳
限流的核心策略是“防守反击”:防守端,在客户端主动限速,避免触发服务端 429;反击端,万一触发了 429,用指数退避策略优雅重试。
客户端主动限速——令牌桶
以 OpenAI GPT-4 为例,付费限制是 500 RPM,换算下来大约是 8.3 次/秒。稳妥起见,留 20% 余量,限制在 6 次/秒。
Java 中可以直接用 Guava 的 RateLimiter:
private final RateLimiter rateLimiter = RateLimiter.create(6.0);
每次调用前先 tryAcquire,等不到令牌就抛异常,提示“系统繁忙”。
Python 可以自己实现一个线程安全的令牌桶,逻辑其实很简单:按固定速率补充令牌,桶有容量上限,调用时消耗一个令牌。同样 6 次/秒,桶容量 10 个。
指数退避重试
收到 429 时立刻重试是最大忌讳,95% 的情况会继续收到 429。正确做法是:等待一段时间再试,且等待时间指数增长,例如 1 秒→2 秒→4 秒→8 秒→16 秒→30 秒,并加入随机抖动,避免多个请求同时重试。
Java 用 Spring Retry 注解即可实现:设置 maxAttempts 为 4,backoff 的 multiplier 为 2.0,maxDelay 为 30 秒,random 为 true。Python 有现成的 tenacity 库,同样几行代码搞定。
429 错误完整处理流程
当 429 发生时,第一件事是解析 Retry-After 头,获取服务端建议的等待时间。然后,把这个 Key 标记为“冷却中”,切换到下一个可用 Key。
多 Key 轮询是应对限流的进阶玩法。当单个 API Key 的额度不够用时,维护一个 Key 池,轮询使用。同时记录每个 Key 的下次可用时间,如果某个 Key 刚被限流过,就自动跳过它。这样即使单个 Key 在冷却期,系统整体仍然可以提供服务。
全局异常处理也是必须的。在 Spring Boot 中,用 @RestControllerAdvice 统一捕获 RateLimitException 和 AiTimeoutException,返回统一的错误响应格式,并带上 Retry-After 头。前端根据这个头做展示和重试,体验会好很多。
生产级架构方案
如果说前面的策略是“战术级别”的应对,那生产级的架构就是“战略层面”的保障。
异步队列削峰:高并发场景下,不要让请求直接打到 AI 接口。用 MQ(消息队列)解耦,生产者接收请求后立即返回 taskId,消费者以受控的并发数(比如 2)处理队列中的 AI 请求。前端通过轮询 taskId 获取结果。这样既能削峰,又能保护 AI 接口不被突发流量冲垮。
熔断降级:AI 服务商偶尔会出现大规模故障或响应极慢的情况。用 Resilience4j 做熔断器,设置失败率超 50% 或慢调用率超 80% 时触发熔断,熔断持续 60 秒,期间直接返回降级结果(如“AI 服务暂时不可用”)。等熔断器半开后,再试探恢复。
语义缓存:用户问“今天天气怎么样”和“今天天气如何”,本质上是同一个问题。对重复或语义相似的问题,直接返回缓存结果,既节省费用又节省时间。精确匹配用 Redis 的 KV,语义匹配可以接向量数据库(如 Redis VectorSearch 或 Pinecone),相似度超过 0.95 即视为命中。
监控与告警
没有监控的生产环境等于盲人摸象。以下四个指标必须监控:
- AI 接口成功率:低于 95% 触发告警
- AI 接口 P99 延迟:超过 60 秒需检查模型或网络
- 429 错误率:超过 5% 说明限流策略需要调整
- 队列积压量:超过 100 说明消费者处理能力不足
- 熔断器状态:一旦变为 OPEN,立即告警
Spring Boot 中用 Micrometer 埋点非常方便,定义好 Counter 和 Timer,接上 Prometheus 和 Grafana 就能看到实时的仪表盘。
总结
AI 接口的延迟高、限制多、不稳定这三个特点,决定了你必须在工程层面做好防护。核心原则其实就三条:
超时问题:调大超时 + 改流式,用户体验从 0 到满分。
限流问题:客户端主动限速 + 指数退避,从被动挨打到主动掌控。
架构问题:队列 + 熔断 + 缓存,构建真正的生产级 AI 应用。
把上面的代码复制进你的项目,你的 AI 应用就能扛住真实的生产流量了。
附:配套技术图解
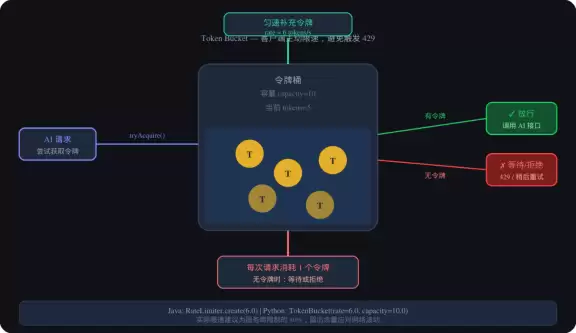 图2:令牌桶限流工作原理
图2:令牌桶限流工作原理
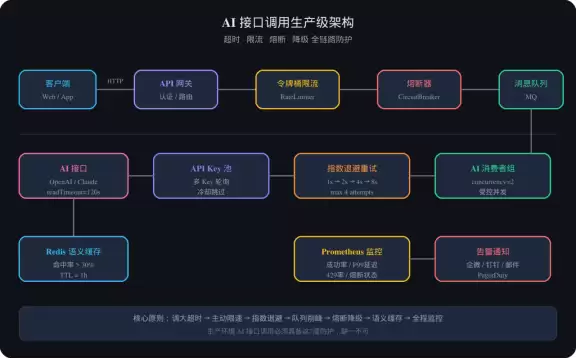 图1:AI接口调用生产级架构全景
图1:AI接口调用生产级架构全景
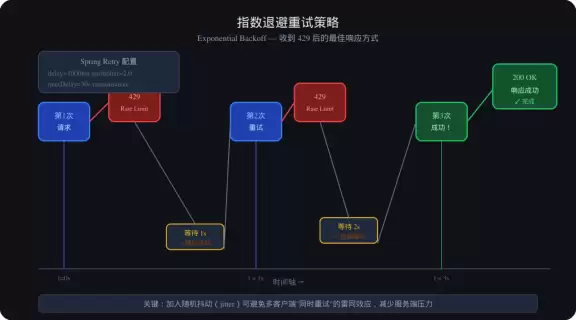 图4:Resilience4j 熔断器三态转换
图4:Resilience4j 熔断器三态转换




