事件相机作为一种仿生视觉传感器,在时间延迟、功耗和动态范围方面显著优于传统相机。这些突出的技术优势,使得基于事件的学习成为计算机视觉领域一个极具潜力的研究方向。然而,大规模事件数据集的采集成本高昂,严重制约了该领域的探索进程。为此,事件模拟技术应运而生,被视为破解数据瓶颈的关键路径。
熟悉事件模拟领域的读者可能注意到,现有方案大多围绕一个核心思路展开——利用视频数据合成新的事件数据。这种思路看似合理,因为连续视频帧能够清晰捕捉像素亮度的细微变化,而亮度变化正是触发事件的前提条件。但在实际应用中,其短板同样明显:视频采集成本居高不下,且在不同视角、运动模式及光照条件下扩展难度极大。为突破这一局限,文本到事件模拟(T2E)的思路被提出——只需输入一句简单的文本提示,即可直接生成事件数据。
不过,当前的T2E方法大多依赖构建庞大的文本-事件对语料库来训练模型,通用性仍然受限。更为理想的方案是无需训练、开箱即用,既能省去昂贵的数据采集成本,又能快速迁移至新领域。这正是香港浸会大学、北京大学与NVIDIA AI Technology Center联合团队的研究动机——他们提出的Texvent框架,正是瞄准这一目标而设计。
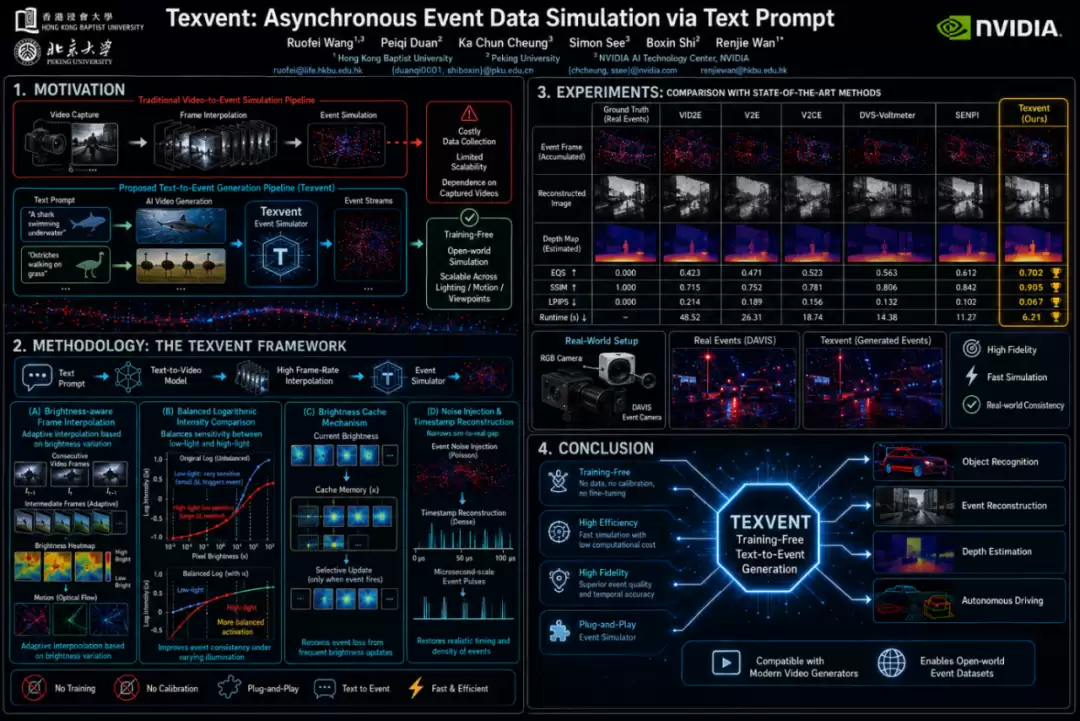
从文本到事件的“翻译官”
你可能好奇:既然已有视频生成器,再级联一个现成的V2E模拟器是否可行?理论上可行,但实际效果并不理想——存在两个痛点:一是效率低下,帧插值过程中冗余的双向光流估计拖慢运行速度;二是保真度不足,真实事件数据与模拟数据之间的差异建模不对齐,导致下游模型训练时泛化能力大打折扣。
正是为了解决这两大难题,Texvent应运而生。该框架无需任何训练,仅凭文本提示即可完成通用事件模拟,堪称“零样本事件生成”的代表性方案。其架构主要分为两大部分:高帧率视频生成与高效事件模拟。
在高帧率视频生成部分,Texvent采用一种亮度感知插值方法,大幅减少冗余的帧插值操作,显著提升效率。而模拟器部分则通过两个精心设计的机制来增强保真度:平衡对数强度比较策略与基于缓存的电压刷新机制。前者旨在解决低光照与高光照条件下事件激活灵敏度不均衡的问题,后者则致力于减少因频繁参考亮度更新而导致的事件丢失。这样一来,Texvent能够在模拟过程中生成高保真的事件数据,为下游任务提供更可靠的支持。
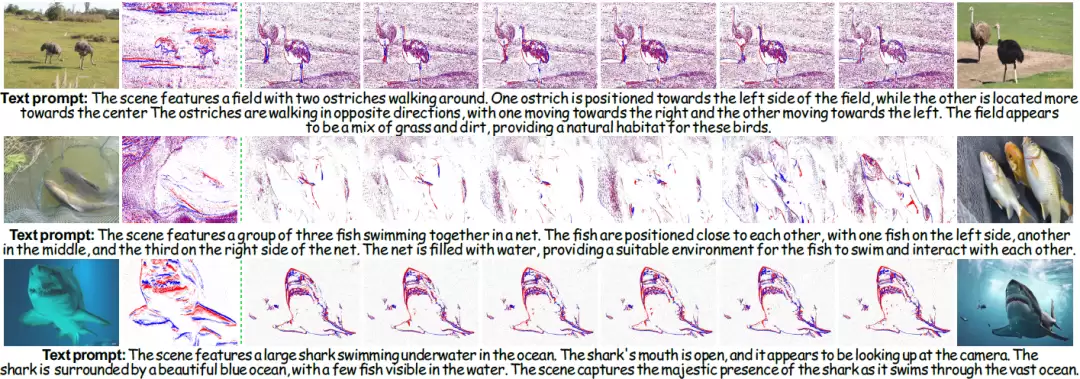
图 1 可视化结果。从左到右依次为:取自 NT-ImageNet 数据集的真实图像-事件对、序列事件流以及Texvent 生成的单帧图像。
方法设计的精妙之处
从细节来看,Texvent的运行流程可拆解为几个关键步骤。首先,多模态大语言模型(MLLM)根据文本提示生成高时间分辨率的视频。随后,亮度感知帧插值进一步提升视频帧率,为后续事件模拟奠定基础。
在事件模拟阶段,团队提出了一种新型事件模拟器。其中,平衡对数强度比较策略巧妙地从对数亮度空间切入,通过对称比较当前亮度与参考亮度,有效校正不同光照条件下的激活灵敏度偏差。而基于缓存的电压刷新机制,则在计算事件帧过程中,专门存储尚未激活事件数据坐标处的亮度值,避免因频繁参考亮度更新而产生不必要的虚假事件。该机制还会定期将缓存重置为初始值,从而防止长期模拟带来的累积误差。
注入背景活动噪声之后,再通过密集时间戳重建优化事件时间分布的稀疏性,最终生成的事件流不仅异步、稀疏,而且具备更平滑的过渡与更丰富的背景细节。
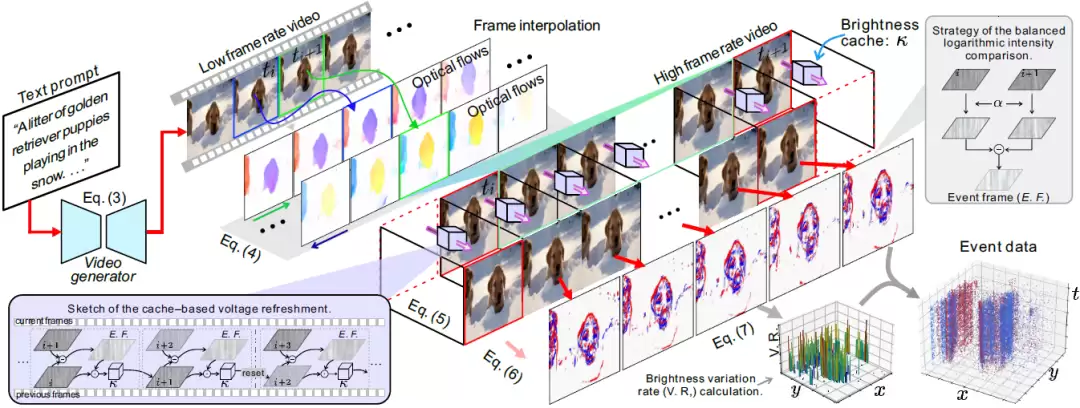
图 2 Texvent框架图, 包括高帧率视频生成和事件模拟。
实验数据:全面碾压还是各有千秋?
为验证Texvent的效果,研究团队设计了一系列严格的实验。他们采用经典的视频到事件数据集(ECD与DSEC),并专门构建了一个文本-事件对数据集NT-ImageNet,用于测试T2E场景下的性能。从NT-ImageNet验证集中采样事件流,再使用LLaVA-v1.5-13B生成对应的文本描述,从而实现真实世界事件与文本描述的对齐。
对比方法包括VID2E、V2E、V2CE、DVS-Voltmeter与SENPI等主流方案,视频生成器则选用了Cosmos、Wan、Open-Sora与CogVideoX等多种MLLM。评价策略分为三个层面:帧级评估(利用E2VID、HyperE2VID与ETNet将事件重建为图像,再对比PSNR、SSIM、LPIPS、MSE等指标)、事件级评估(事件质量评分EQS)以及应用级评估(下游任务如目标识别、图像重建、深度估计)。
表1的定量结果充分说明了问题。在事件帧评估中,Texvent在MSE(0.045)与LPIPS(0.339)上表现最佳,SSIM(0.488)也颇具竞争力。在重建图像方面,Texvent同样取得了最高的SSIM(0.472)与最佳的LPIPS(0.296)。唯一温和的挑战来自DVS-Voltmeter,其MSE(0.096)略优于Texvent0.02。总体而言,Texvent不仅事件生成准确,重建图像的质量也保持在高水准。

表1定量评估了不同模拟器的事件帧和重建图像。
再看可视化结果,差异更为直观。VID2E与V2E生成的事件稀疏到出现肉眼可见的“空洞”,V2CE与SENPI的问题在于时间分辨率不足,运动过程中事件丢失严重。DVS-Voltmeter的事件分布如同洒落的白噪声,破坏了原有的自然结构。而Texvent生成的事件模式清晰,物体边界完整,事件密度均衡,与真实值(GT)的匹配度相当高。

图3:事件帧及其对应的重建图像的可视化结果。
值得一提的是,团队还搭建了一套真实数据采集系统,用于检验Texvent在实际场景中的表现。DAVIS346传感器与RGB摄像头的组合,使得模拟事件与真实事件能够进行直接对比。结果显示,Texvent生成的模拟事件在时间动态与空间分布上与真实数据高度吻合,充分证明了方法的实用性与可靠性。
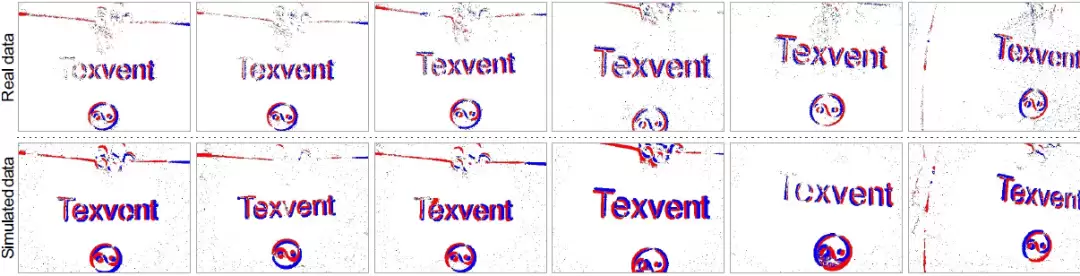
图 4 真实数据和模拟数据的对比。
深度估计的测试结果也进一步验证了Texvent的领先性。与VID2E、V2CE、DVS-Voltmeter等基线方法相比,Texvent生成的校正事件最为锐利、重影最少,深度图平滑流畅且场景结构清晰,远近分离明显。V2CE表现不错但边缘稀疏性稍差;DVS-Voltmeter的深度图则显得粗糙且带有噪声。

图5校正的事件和模拟事件数据的深度图。
总结:一个真正的“即插即用”解决方案
Texvent的核心价值体现在两点:一是无需训练,二是即插即用。它巧妙利用多模态大语言模型打通了从文本到事件的通道,所提出的事件模拟器也能无缝兼容不同的视频生成模型与标准摄像机。此外,团队还贡献了一个新的文本-事件对数据集,为今后的T2E研究提供了标准化的测试基准。从视频到事件的模拟到文本到事件的映射,Texvent在效率、准确性与通用性上均交出了一份亮眼的答卷,这无疑是事件相机生态走向成熟的重要里程碑。




