MCP 从入门到实战:让大模型真正「动手」
大模型是不是有时候让你感觉像个“纸上谈兵”的理论家?文本整理、代码生成都没问题,但一让它读你电脑上的文件、查个天气、或者发封邮件,它就立刻哑火了。
过去要解决这个问题,每个AI应用都得单独对接每种能力,接口千奇百怪,开发和维护起来那叫一个头疼。所以,Anthropic在2024年底搞出了个MCP(模型上下文协议),目标很纯粹:定一套通用标准,打通AI客户端和外部能力程序之间的对话通道。
你可以把它想象成一个“USB接口”——键盘、U盘,只要符合标准,插到电脑上就能直接用。同理,各种工具(查时间、读文件、调API)只要实现了MCP服务端,就能被不同的AI客户端调用。
对使用者来说,只需要在客户端里配置好MCP服务,用自然语言提问,模型就能在需要时自动调用合适的工具,再把结果组织成回答。听起来很方便,是吧?
目录
为什么要搞出MCP?
三个核心角色:Host、Server、Tool
一次典型对话,数据都是怎么流动的?
模型如何“听懂”你的问题并选对工具
MCP协议分两层,别弄混了
在Cherry Studio里上手配置MCP
动手:用Python写一个标准的MCP工具服务
1. 为什么需要 MCP
大语言模型在理解和生成文字方面是高手,但一出厂就被“圈定”在它的知识库里,默认情况下:不能直接读取你电脑上的文件;不能实时查询天气、股价、新闻;更不能替你去搜索、发邮件或操作数据库。
这就是为什么我们需要一个桥梁,让AI能够伸出“手”来,接触外部世界。
| 类比 | 含义 |
|---|---|
| USB 接口 | 不同设备(键盘、U盘)只要符合标准,就能插到电脑上 |
| MCP | 不同工具(查时间、读文件、调API)只要实现MCP服务端,就能被各种客户端调用 |
2. 三个核心角色:Host、Server、Tool
2.1 MCP Host(宿主 / 客户端)
Host就是你日常使用的AI应用,它负责:启动并管理MCP服务端进程;把你的问题连同“当前有哪些可用工具”一起交给大模型;根据模型的指令去调用服务端,再把结果返给模型。
常见的Host有Cherry Studio、Cursor、Claude Desktop等。本文我们就以Cherry Studio为例来演示配置和使用。
2.2 MCP Server(能力提供方)
Server是一个按照MCP规范运行的程序。虽然名字里带“Server”,但多数情况下它是在你本机通过子进程启动的(比如Python或Node脚本),而不是必须部署在远程机房。
它向Host声明自己拥有哪些:Tool(可执行函数);Resource(可读数据);Prompt(预设提示模板)。
2.3 Tool(工具)
Tool就是Server暴露给模型的一条“可调用能力”,在代码里通常对应一个带类型注解的函数。每个Tool都自带:name(工具名,如get_cpu_status);description(自然语言说明,通常取自函数文档字符串);inputSchema(参数的JSON Schema,用来约束模型填入什么字段)。
模型正是靠description和inputSchema来判断“该不该用这个工具、参数该怎么填”。
3. 一次完整对话里发生了什么
假设用户问:“我电脑现在卡不卡?内存占用多少?”而系统已经接入了性能监控MCP,这时数据的流动是这样的:
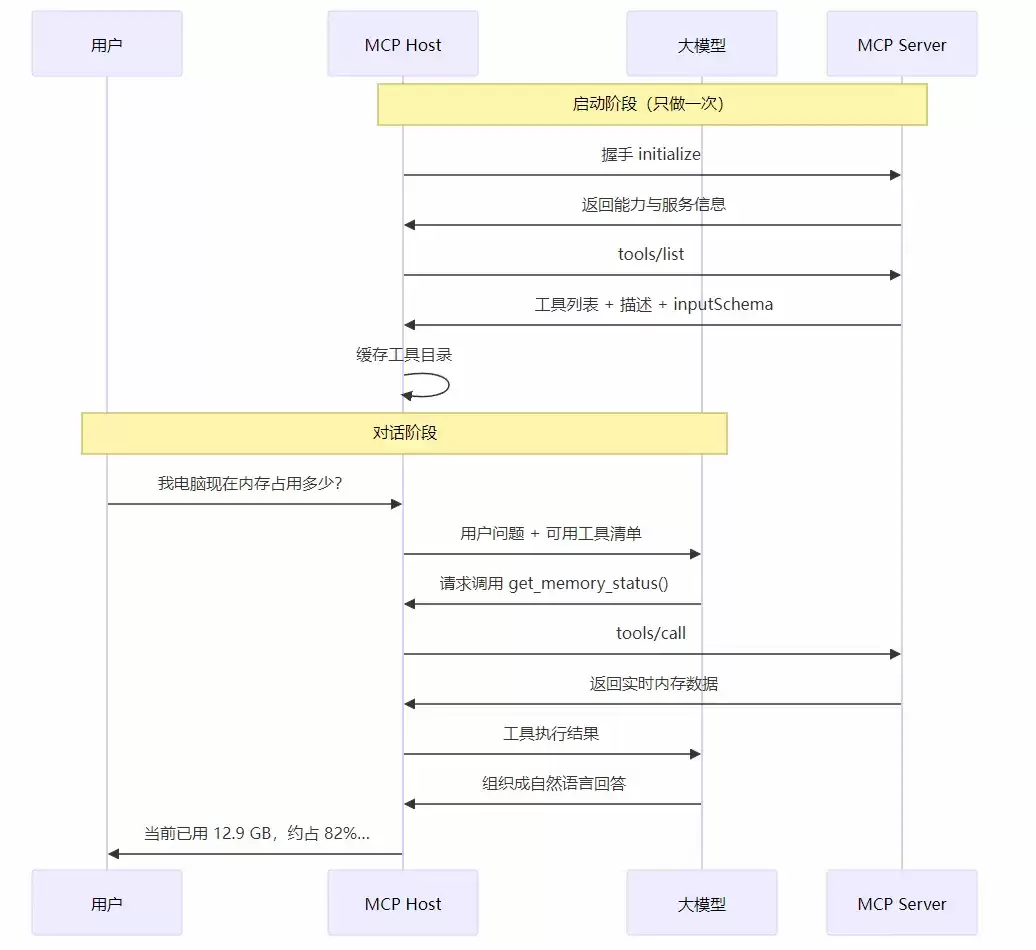
4. AI 如何「听懂」你的问题并选对工具
很多朋友搞错了,以为MCP规定了“模型怎么思考”。其实,MCP只规范Host和Server之间的通信;而模型与Host之间用什么格式(比如Function Calling、XML工具块),各家客户端自己决定。
但对于使用者,了解下面这条链路就够了。
4.1 Host 在每次请求里多塞了什么
当你开启MCP并选中某个Server后,Host大致会做这些事:把从tools/list拿到的信息,转成模型能识别的工具定义列表(名称、描述、参数schema);把你的用户消息和这段工具定义一起发给大模型API;如果模型返回“需要调用某工具及JSON参数”,Host就去执行tools/call,再把结果作为工具结果消息追加到对话中,再次请求模型生成最终回答。
所以模型并不是事先“安装”了MCP,而是在每一轮对话中都看到一份“当前会话可用工具说明书”,然后自己做选择。
4.2 模型靠什么做决策
模型主要依据三类信号:
| 信号 | 作用 |
|---|---|
| 用户意图 | “内存占用多少”指向内存类;“C盘还剩多少”指向磁盘类 |
| Tool的description | 说明这个函数解决什么问题,避免误用 |
| inputSchema | 规定参数名、类型、是否必填,模型从中抽取或推断参数值 |
例如,一个工具描述为“查询物理内存占用”,用户问“我电脑还剩多少内存”,模型就更有可能调用get_memory_status。
4.3 为什么有时不调用、有时乱调用
不调用常见的原因有:模型认为凭自身知识就能回答(比如历史常识类);未启用MCP或对话里没勾选对应Server;所用模型不支持工具调用(在Cherry Studio里要选带“工具”能力的模型)。
乱调用通常是因为:Tool描述太笼统,多个工具界限不清;参数schema太宽,缺少required或枚举约束;用户问题太模糊,模型只能猜测。
改进建议很实用:函数名要见名知意;文档字符串要写清“何时使用、返回什么”;参数用类型注解和枚举来缩小空间。
4.4 和「RAG / 联网搜索」的区别
RAG是先检索文档片段,再让模型阅读总结;而MCP Tool是模型主动发起一次结构化的函数调用,由Server执行逻辑(比如算数、查API、读本地文件)。
这两者其实可以并存——MCP解决的是标准化、可执行、可组合的外部能力接口。
5. MCP 协议分两层,别混在一起
| 层级 | 谁和谁 | 规范什么 |
|---|---|---|
| 层A | MCP Host ↔ MCP Server | 握手、列工具、调工具、传资源等(JSON-RPC风格消息,常见传输为stdio或SSE) |
| 层B | MCP Host ↔ 大模型API | 如何把工具清单编进prompt、如何解析模型的tool_call(各Host实现不同) |
MCP只负责层A。这也是为什么同一个Python MCP Server,可以无缝接到Cherry Studio、Cursor等不同Host——只要对方实现了MCP客户端逻辑。
Model Context Protocol里的Context,指的是让模型感知“外部环境里有哪些可调用能力”,从而获取实时、私有或结构化信息,而不仅仅是依赖训练数据。
6. 在 Cherry Studio 里接入 MCP
6.1 环境准备
Cherry Studio在运行STDIO类MCP时,通常需要本机有:Python 3.10+(自建Server用);uv(推荐用于运行Python项目);使用社区现成的uvx/npx工具时,按官方文档在Cherry Studio设置里安装内置运行环境。
官方文档有MCP环境安装和MCP配置说明,可以参考。
6.2 添加社区 Server(示例:网页抓取)
操作很简单:打开设置→MCP Server→添加服务器;名称自定,类型选STDIO;命令填uvx,参数填mcp-server-fetch(首次会下载依赖,可能较慢);保存后在对话界面启用该MCP,并选择支持工具调用的模型。
对应的JSON配置片段如下:
{ "mcpServers": { "fetch": { "command": "uvx","args": ["mcp-server-fetch"]}}}
6.3 添加本文自带的 Python Server(下文第 7 节)
假设工作区已附带项目mcp-sys-monitor/。先在该目录执行uv sync,然后在Cherry Studio新增STDIO服务器:
{ "mcpServers": { "sys-monitor": { "description": "查询本机 CPU、内存、磁盘、网络、GPU 性能","isActive": true,"command": "uv","args": ["--directory","C:/Users/25700/Desktop/test/mcp-sys-monitor","run","server.py"]}}}
注意:需要把--directory后的路径改成你本机mcp-sys-monitor的实际位置(Windows建议用正斜杠/)。
保存后连接成功,在对话里勾选sys-monitor,并选择支持工具调用的模型即可试用。
6.4 话术建议
可以试试这些问法:“帮我看一下电脑现在的整体性能状态”;“CPU占用多少?频率多少?”;“内存还剩多少?有没有快满了?”;“C盘和D盘各用了百分之几?”;“现在网速怎么样?”


7. 动手:用 Python 写一个标准 MCP 工具服务
Cherry Studio本身不会直接把“任务管理器里的实时性能数据”交给大模型。下面这个mcp-sys-monitor就是一个很有价值的例子:让AI能查询你这台电脑当前的CPU、内存、磁盘、网络和GPU状态——就像Windows任务管理器的“性能”页那样。
7.1 这个 Server 提供什么
| 工具 | 对应任务管理器 | 用途 |
|---|---|---|
| get_system_overview | 性能页总览 | 一次返回CPU/内存/磁盘/网络/GPU摘要 |
| get_cpu_status | CPU卡片 | 利用率、核心数、运行频率 |
| get_memory_status | 内存卡片 | 已用/总量/可用、页面文件 |
| get_disk_status | 磁盘卡片 | 各分区占用、短时读写速度 |
| get_network_status | 网络卡片 | 各网卡实时收发速率 |
| get_gpu_status | GPU卡片 | 显卡名称;NVIDIA独显可读利用率与显存 |
底层用psutil采集跨平台指标;Windows下额外通过WMI补充内存频率等信息,有nvidia-smi时读取独显占用。
7.2 设计上的三个「标准写法」
① 按指标拆工具,同时提供总览
用户问“内存多少”时,模型应调get_memory_status;问“电脑卡不卡”时,调get_system_overview。粒度清晰,避免一个巨型函数让人难以选择。
② 文档字符串写清触发场景
例如:@mcp.tool()
def get_memory_status() -> str:
"""查询物理内存与交换区占用情况。当用户问内存用了多少、还剩多少、内存占用率时使用。Windows下会尽量补充内存频率、插槽等信息。"""
③ 采样型指标要注明等待时间
CPU利用率、网速需要两次采样相减。在文档字符串里说明“约0.6秒采样”,用户和模型才知道结果有短暂延迟,这很正常。
7.3 项目结构
mcp-sys-monitor/
├── pyproject.toml
└── server.py
7.4 pyproject.toml
[project]
name = "mcp-sys-monitor"
version = "0.1.0"
description = "查询本机 CPU、内存、磁盘、网络、GPU 性能的 MCP 服务"
requires-python = ">=3.10"
dependencies = [
"mcp[cli]>=1.6.0",
"psutil>=6.0.0",
]
[project.scripts]
mcp-sys-monitor = "server:main"
7.5 核心代码摘录
总览工具(组合多个采集函数):
@mcp.tool()
def get_system_overview() -> str:
"""获取本机性能总览,类似任务管理器「性能」页。
当用户问「电脑现在什么状态」「性能怎么样」「卡不卡」时使用。
一次返回 CPU、内存、磁盘、网络、GPU 的摘要。
"""
sections = [
("【CPU】", _cpu_block()),
("【内存】", _memory_block()),
("【磁盘】", _disk_block()),
("【网络】", _network_block()),
("【GPU】", _collect_gpu_info()),
]
# 拼接为可读文本返回给模型...
CPU采样(psutil需短暂interval才准确):
def _cpu_block(interval: float = 0.6) -> list[str]:
usage = psutil.cpu_percent(interval=interval)
freq = psutil.cpu_freq()
lines = [
f"总利用率:{usage:.1f}%",
f"物理核心:{psutil.cpu_count(logical=False)} | "
f"逻辑核心:{psutil.cpu_count(logical=True)}",
]
if freq and freq.current:
lines.append(f"当前频率:{freq.current:.2f} GHz")
return lines
网速(两次采样求速率):
def _network_block() -> list[str]:
net1 = psutil.net_io_counters(pernic=True)
time.sleep(0.6)
net2 = psutil.net_io_counters(pernic=True)
for nic, c2 in net2.items():
down = (c2.bytes_recv - net1[nic].bytes_recv) / 0.6
up = (c2.bytes_sent - net1[nic].bytes_sent) / 0.6
# 格式化为 KB/s、MB/s 返回...
7.6 本地运行
cd mcp-sys-monitor
uv sync
uv run server.py
也可以在终端快速验证(不经过MCP协议):
uv run python -c "import server; print(server.get_system_overview())"
7.7 写好 MCP 工具的检查清单
- 一事一工具:总览+分项查询,方便模型精准调用;
- 返回人类可读文本:模型直接转述给用户,比裸JSON更自然;
- 注明采样耗时:实时指标有延迟,要在描述里说清楚;
- 平台差异做降级:GPU读不到利用率时仍返回显卡名称,不直接崩溃;
- stdio干净:
log_level="ERROR",不要用print污染协议通道。
小结
| 要点 | 一句话 |
|---|---|
| MCP是什么 | AI客户端与外部能力程序之间的统一对话协议 |
| 谁调用谁 | Host管模型和Server;模型决策,Host执行 |
| 模型怎么选对工具 | 靠工具描述+JSON Schema+用户问题,在支持tool calling的API里完成 |
| 怎么落地 | Cherry Studio配置mcp-sys-monitor,对话里问“电脑性能怎么样”即可 |
掌握Host/Server/Tool与“发现→决策→执行→总结”这四步,再做一个Cherry Studio本身做不到但MCP很擅长的扩展(比如本机性能监控),你就能真正理解MCP的实用价值了。




