近期,北京大学多个学院联合发布的《DeepSeek内部研讨系列》资料,在技术社区引发了广泛关注。这套资料系统梳理了DeepSeek模型的核心原理、实际应用与部署策略,对于希望深入理解并有效运用这一国产大模型的从业者而言,是一份极具价值的参考资源。
该系列共包含两本手册:《DeepSeek原理与落地应用》与《DeepSeek私有化部署和一体机》。前者重点讲解技术原理与场景赋能,后者聚焦于模型的实际部署与硬件解决方案,两者共同构建了一套从理论到实践的完整指南。

《DeepSeek原理与落地应用》
这本手册由北京大学青鸟人工智能研究院、计算机学院元宇宙技术研究所和教育学院学习科学实验室联合编写。其核心价值在于不仅解析了DeepSeek的技术内核,还大幅篇幅展示了它在教育、学术等垂直领域的深度应用,并提供了大量可直接参考的提示词范例。

人工智能概念辨析
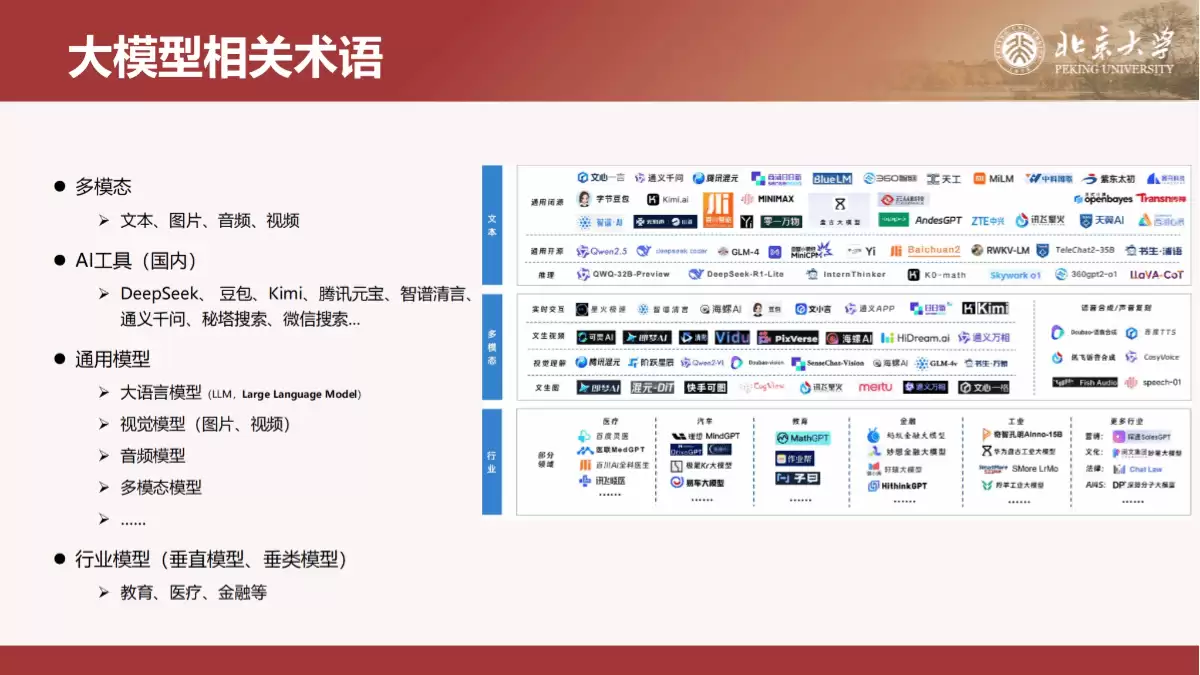
手册开篇先帮助读者厘清相关概念。它系统梳理了大模型的关键术语,涵盖多模态、AI工具分类,以及通用模型与行业模型的差异,为后续理解DeepSeek的定位奠定了坚实基础。
回顾人工智能的“前世今生”是理解当前技术突破的关键。资料从早期的运算推理、知识工程,一直讲到机器学习和深度神经网络的兴起,并重点剖析了Transformer架构这一基石,以及由此催生的生成式人工智能(GenAI)浪潮。
当前,大模型的发展呈现出清晰的分化路径。生成模型(如GPT-4o)擅长通用任务与多模态内容创作,交互体验流畅;而推理模型(如OpenAI o1)在解决复杂逻辑、数学和专业任务上展现出更强的能力,尽管其交互节奏相对较慢,多模态支持也仍在发展之中。这种对比,恰恰凸显了DeepSeek R1作为顶尖推理模型的独特价值。

DeepSeek R1
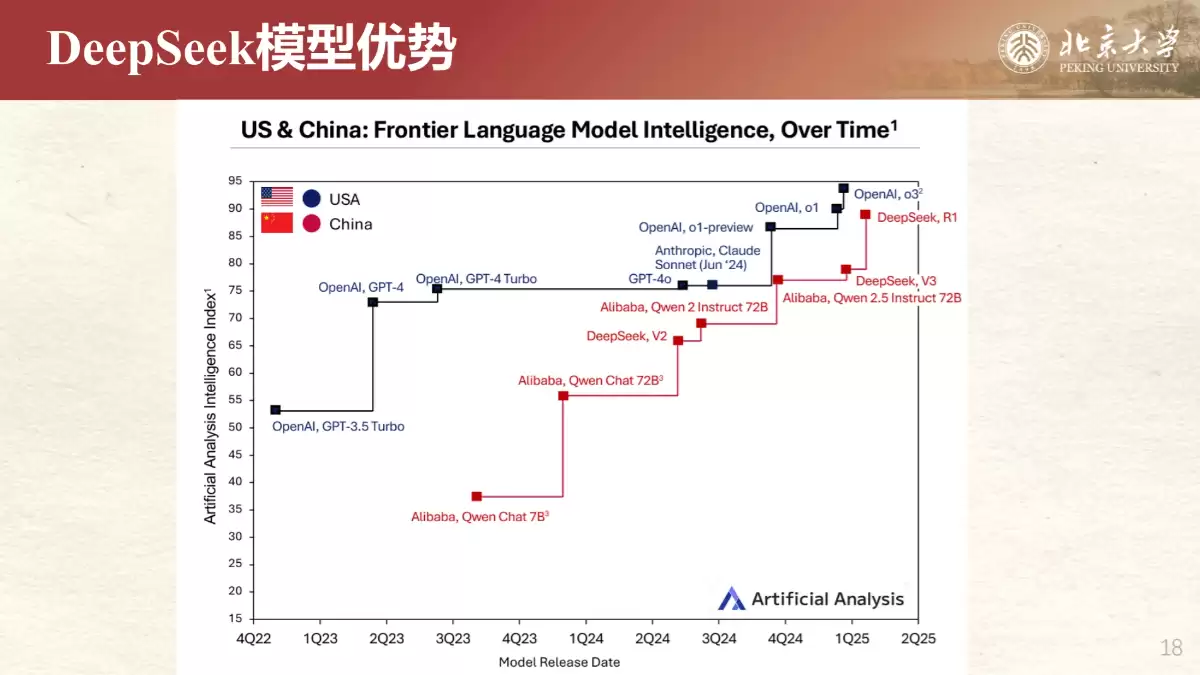
谈及DeepSeek,其背景颇具特色。它脱胎于幻方量化,是一家专注AI基础研究的科技企业。其模型系列主要分为生成模型(V3)和推理模型(R1)。R1的设计初衷便是攻克复杂推理任务,其在DROP任务上F1分数达到92.2%,AIME 2024通过率高达79.8%,这些数据足以证明其强大实力。
DeepSeek R1能迅速“出圈”,离不开三大优势:开源、低成本、国产化。这不仅是技术上的突破,更在生态层面打破了原有垄断,直接推动了整个行业的技术普惠与价格下调。

在技术实现上,R1融合了混合专家(MOE)、多头潜在注意力(MLA)和强化学习(GRPO)等前沿训练技术。对于使用者而言,获取其能力的方式非常灵活:既可以直接调用官方API,也能进行模型微调,还支持通过Ollama、vLLM等工具进行私有化部署,适应从个人开发者到大型企业的不同需求。
模型原理
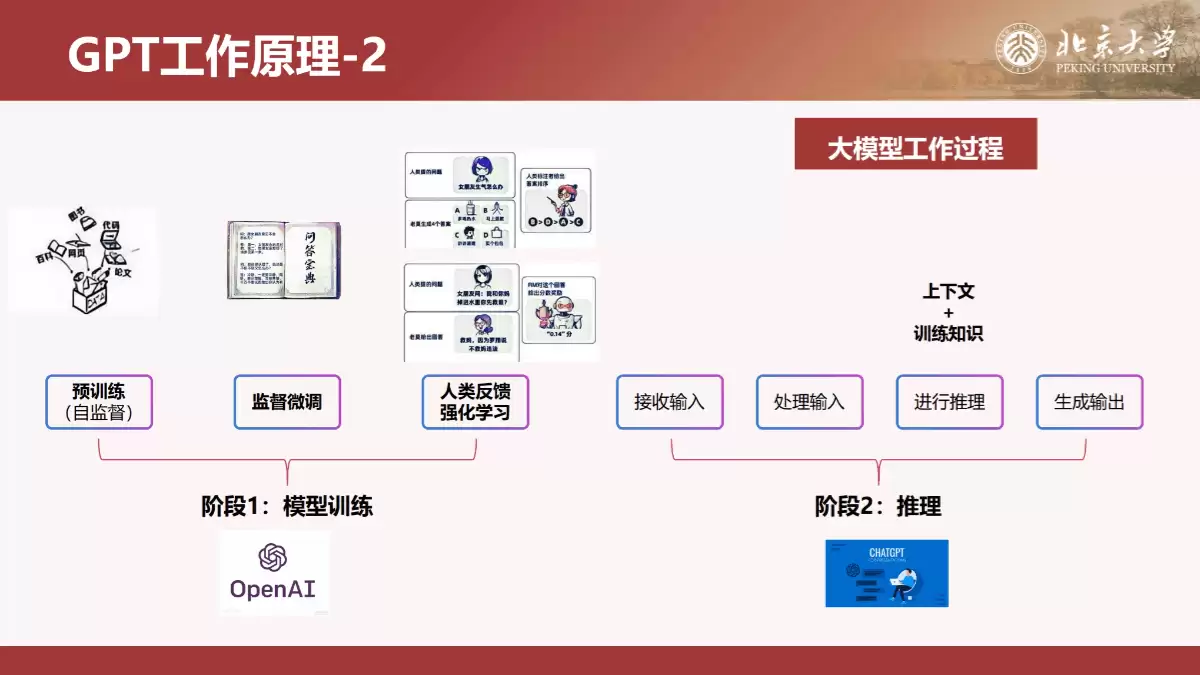
要真正用好一个模型,理解其工作原理很有必要。手册详细解释了GPT类模型基于概率预测的“文字接龙”机制,以及预训练、微调、人类反馈强化学习(RLHF)等关键环节。
生成模型虽强,但也存在局限,比如“幻觉”问题、知识库时效性和上下文窗口限制。而DeepSeek R1作为推理模型,其核心在于引入了思维链(Chain of Thought)、蒸馏(Distillation)和强化学习等技术,模拟人类逐步推理的过程,从而在复杂问题上表现更稳定、更可靠。

落地应用
技术最终要服务于实际场景。DeepSeek降低了人与AI对话的门槛,但其效能上限很大程度上取决于提示词(Prompt)的质量。手册总结了一系列极具实操性的提示词技巧:
真诚直接:明确任务目标,避免模糊表述。
通用公式:按“我要做什么,给谁用,希望达到什么效果,但担心什么问题”的结构组织,帮助模型全面理解意图。
说人话:要求用通俗语言回答,避免过于官方的表述。
反向PUA:主动要求模型列出反对理由或批评角度,以激发其深度思考。
善于模仿:指定模仿对象或文风,生成风格契合的内容。
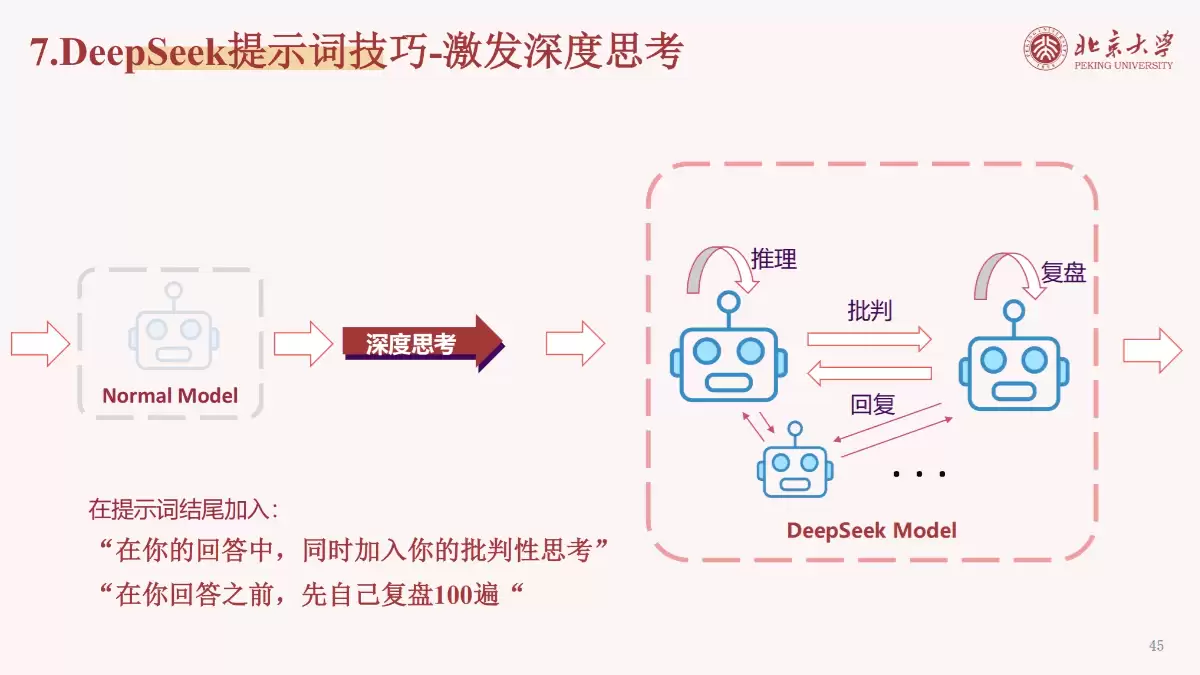
激发深度思考:在提示词中加入“复盘”、“批判性分析”等指令,提升回答深度。



基于这些技巧,DeepSeek R1的应用场景得以极大拓展。尤其在教育与学术赋能领域,其潜力令人印象深刻:
- 教学设计:快速生成课程大纲与设计思路。
- 教学活动:设计变式题、问题支架与课后作业。
- 作业批改:为客观题添加解析,为编程题提供解题思路。
- 个性化教案:设计标注了难度系数的分层习题组。
- 医学病理诊断辅助:生成可能的疾病列表,并提出检查建议。
- 论文全流程辅助:从选题、生成大纲、文献综述到内容扩写与润色查重。
- 学术研究:辅助文献速读、参考文献整理、研究方法设计等。
- 知识付费:设计课程大纲、直播脚本与社群运营话术。




《DeepSeek 私有化部署和一体机》
如果说第一本手册解决了“怎么用”的问题,那么这第二本手册则专注于解决“怎么装”的难题。它由北大青鸟人工智能研究院和元宇宙技术研究所推出,详细指导如何将DeepSeek模型部署到从个人电脑到企业服务器的各种环境中,并重点介绍了开箱即用的DeepSeek一体机解决方案。

人工智能与DeepSeek
手册同样从基础概念回顾开始,并特别梳理了DeepSeek模型自身的演进历史:从V2(MoE架构)、V3(MTP)到R1(推理模型),以及知识蒸馏技术在其中发挥的关键作用。DeepSeek模型的核心优势可以总结为:开源生态友好、支持模型蒸馏、训练成本相对较低。其提供的“R1全家桶”包含了多个经过蒸馏的不同参数量版本,为用户根据自身资源选择合适模型提供了极大便利。


个人部署DeepSeek
对于个人开发者或研究者,私有化部署的首要问题是硬件门槛。手册给出了明确的配置指南,从推荐配置到最低要求,并提供了硬件选择的平衡建议。
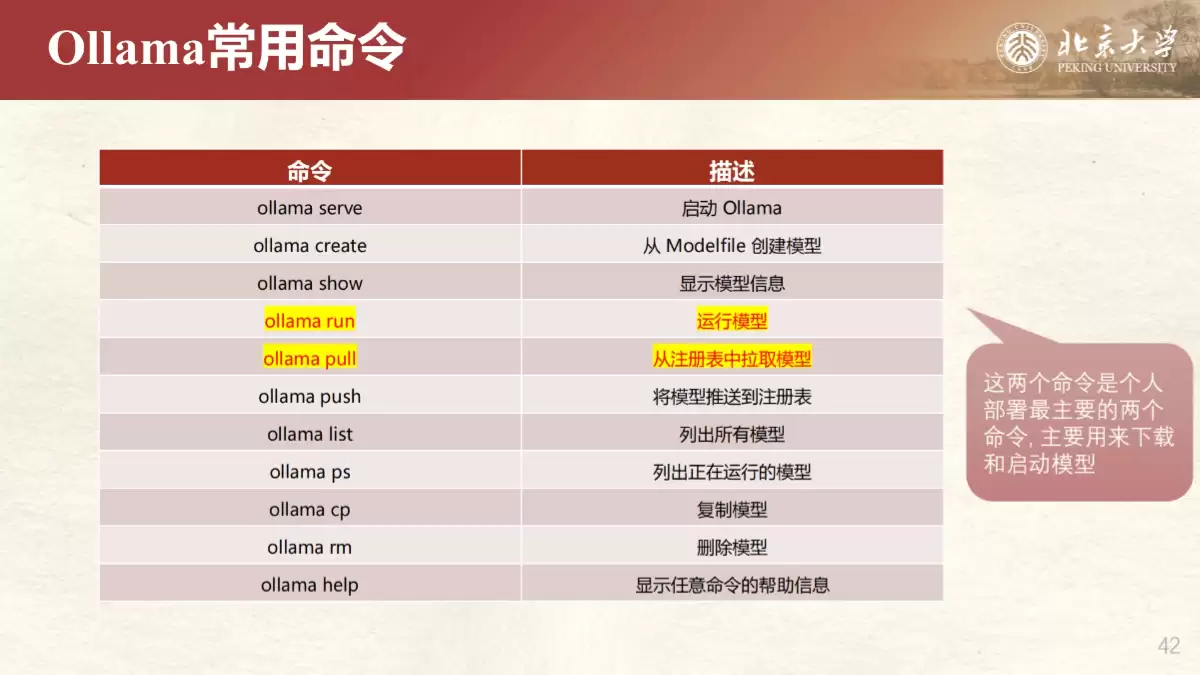
在软件层面,Ollama 因其开源、易用和模型丰富的特点,成为个人部署的首选工具。手册详细说明了Ollama的安装、环境配置、常用命令(如下载、运行模型),并讨论了常见问题如安全漏洞和模型升级后的性能处理。
部署好后,一个友好的前端界面能极大提升使用体验。手册对比了PageAssist、Chatbox、OpenWebUI三款主流前端工具的特点和适用场景,方便用户按需选择。




企业部署DeepSeek
企业级部署对性能、并发和稳定性要求更高。手册介绍了两种主流方案:
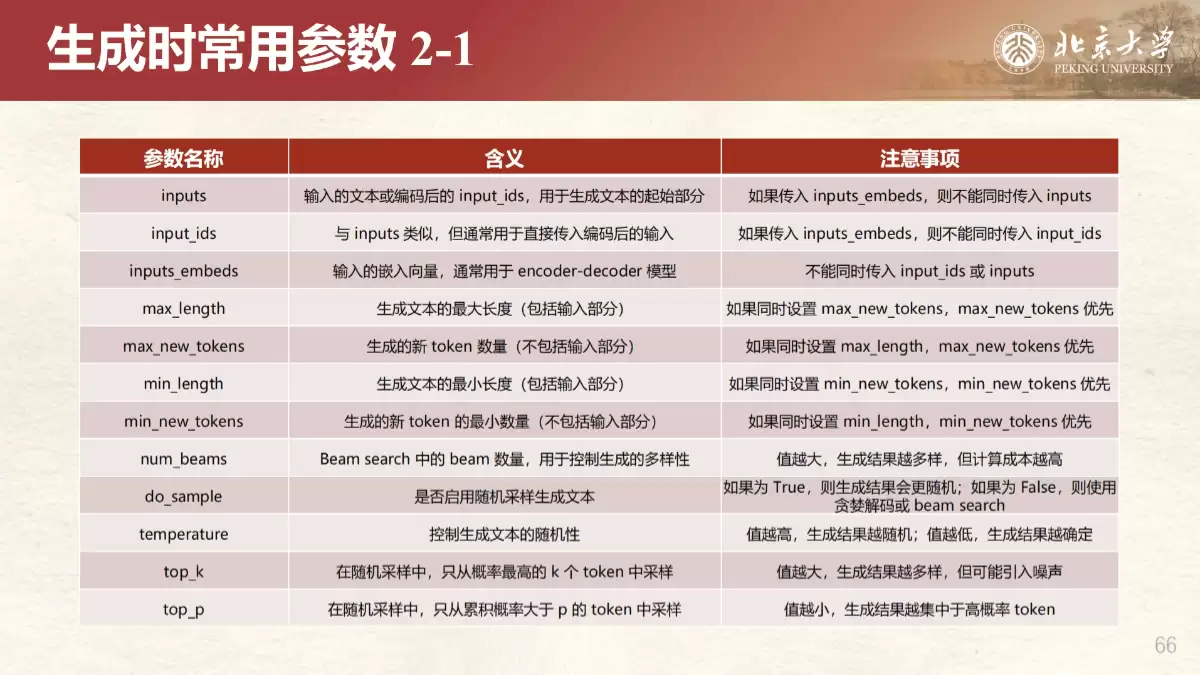
1. Transformers部署:利用Hugging Face的Transformers库,这是最灵活、最通用的方式,适合集成到现有AI管道中。手册详解了安装、加载模型和生成参数调优的步骤。
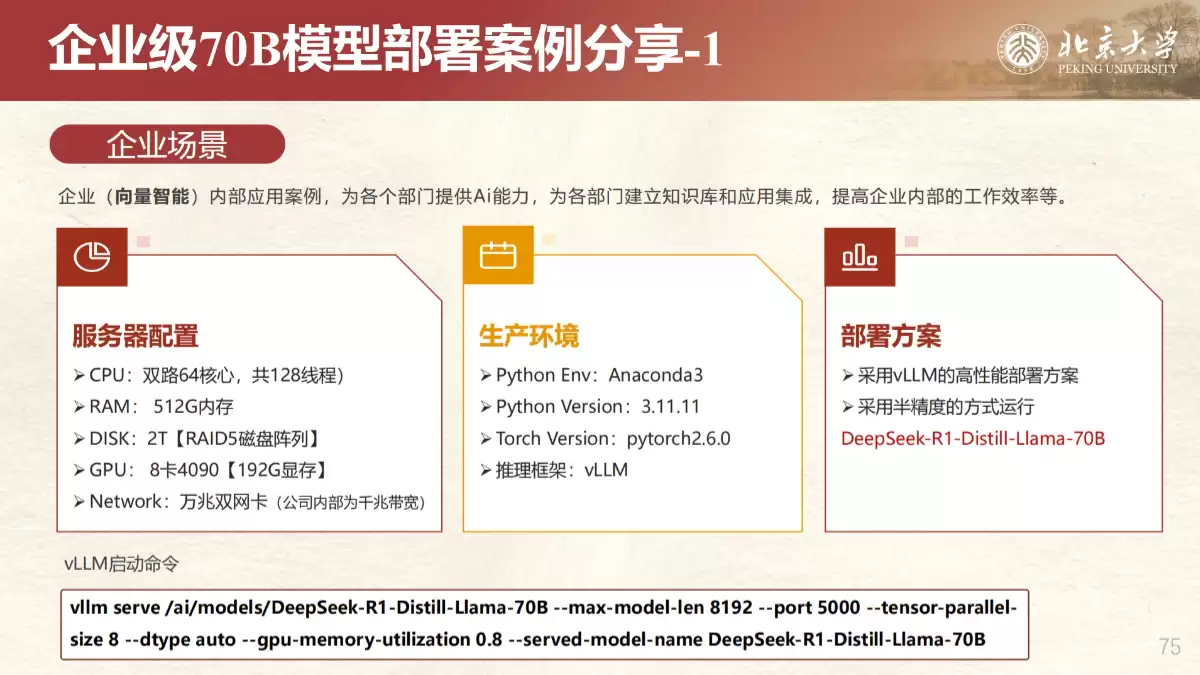
2. vLLM部署:对于追求高吞吐量和并发性能的生产环境,vLLM框架是更优选择。它凭借PagedAttention等技术,能显著提升推理效率。手册提供了详细的部署步骤、参数说明,并分享了实际的并发性能测试数据和企业级70B模型的部署案例。

针对计算资源受限的场景,手册还重点探讨了低成本部署方案,并对比了三种主流方案:
- llama.cpp:通过量化技术大幅降低模型对显存的需求,使其能在消费级显卡甚至CPU上运行。
- KTransformers:另一个高效的推理框架,在特定配置下能实现不错的单并发性能。
- Unsloth动态量化 + Ollama:结合了动态量化技术和Ollama的易用性,在有限资源下实现部署。
手册对这三种方案在不同硬件下的性能进行了测评总结,为预算有限的团队提供了清晰的选型参考。



DeepSeek一体机
对于许多企业和教育机构而言,从零开始部署和调优模型依然存在技术门槛。此时,DeepSeek一体机提供了开箱即用的解决方案。它将高性能硬件、预装优化的DeepSeek模型及管理软件集成于一体,省去了复杂的部署流程。
手册汇总了截至2025年2月的国产一体机厂商信息,并提供了不同配置(如针对671B模型)的推荐规格。更重要的是,它分享了实际性能数据,例如在不同配置下的并发支持能力和用户数,为采购决策提供了关键依据。
最后,手册以北大青鸟AI实验室的建设方案作为案例,详细展示了如何基于DeepSeek一体机,为院校构建涵盖系统层、容器层、业务层、监控层和应用层的完整AI实验环境,并介绍了从基础版到旗舰版的不同配置与报价方案。


总体来看,北京大学的这份系列资料,其价值在于将前沿的DeepSeek技术从原理到落地进行了系统化、场景化的梳理。它不仅仅是一份技术文档,更像是一份面向教育、研究和产业应用的“操作手册”,为AI技术的普惠化与国产化生态发展提供了扎实的参考依据。




