以往,国产大模型发布时,外界习惯贴上“开源第一”或“性价比第一”的标签。但这次,智谱最新开源的 GLM-5.2 彻底扭转了这一局面。铺天盖地的消息都在强调一件事:开源模型已经具备与一流闭源模型正面竞争的实力。尤其在代码生成领域,目前公认的三大强者是 GPT、Claude 和智谱 GLM-5.2。
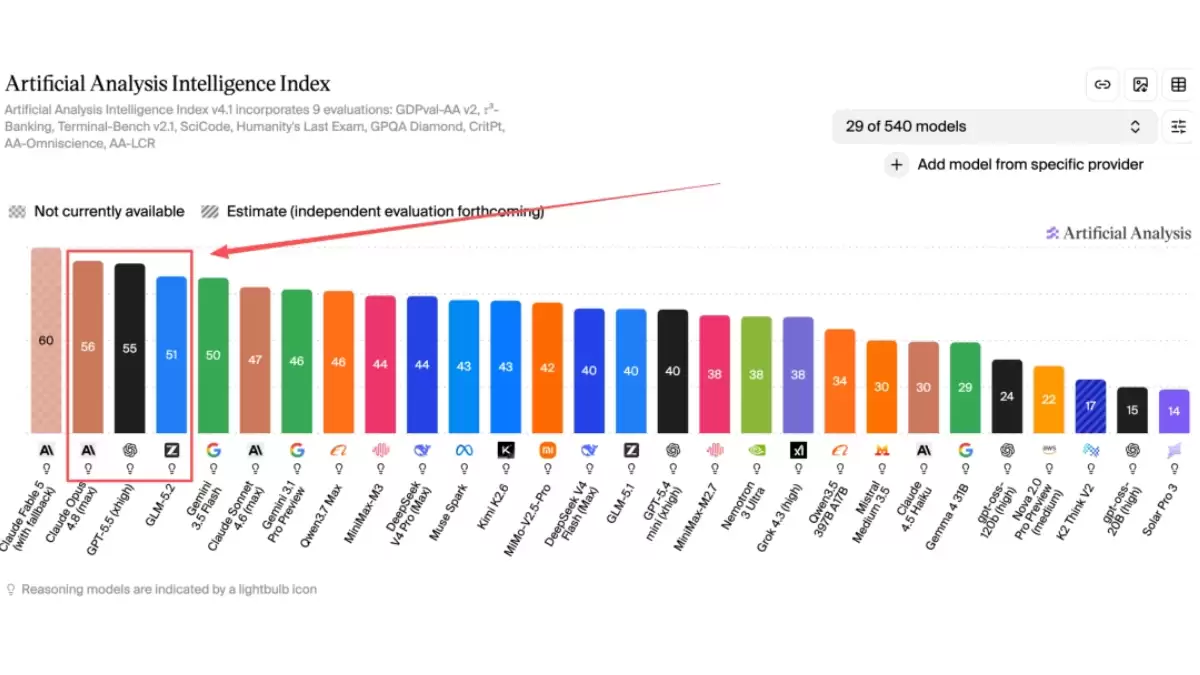
具体数据显示,GLM-5.2 在 Design Arena 权威评测中一举夺冠,Elo 评分高达 1360 分。
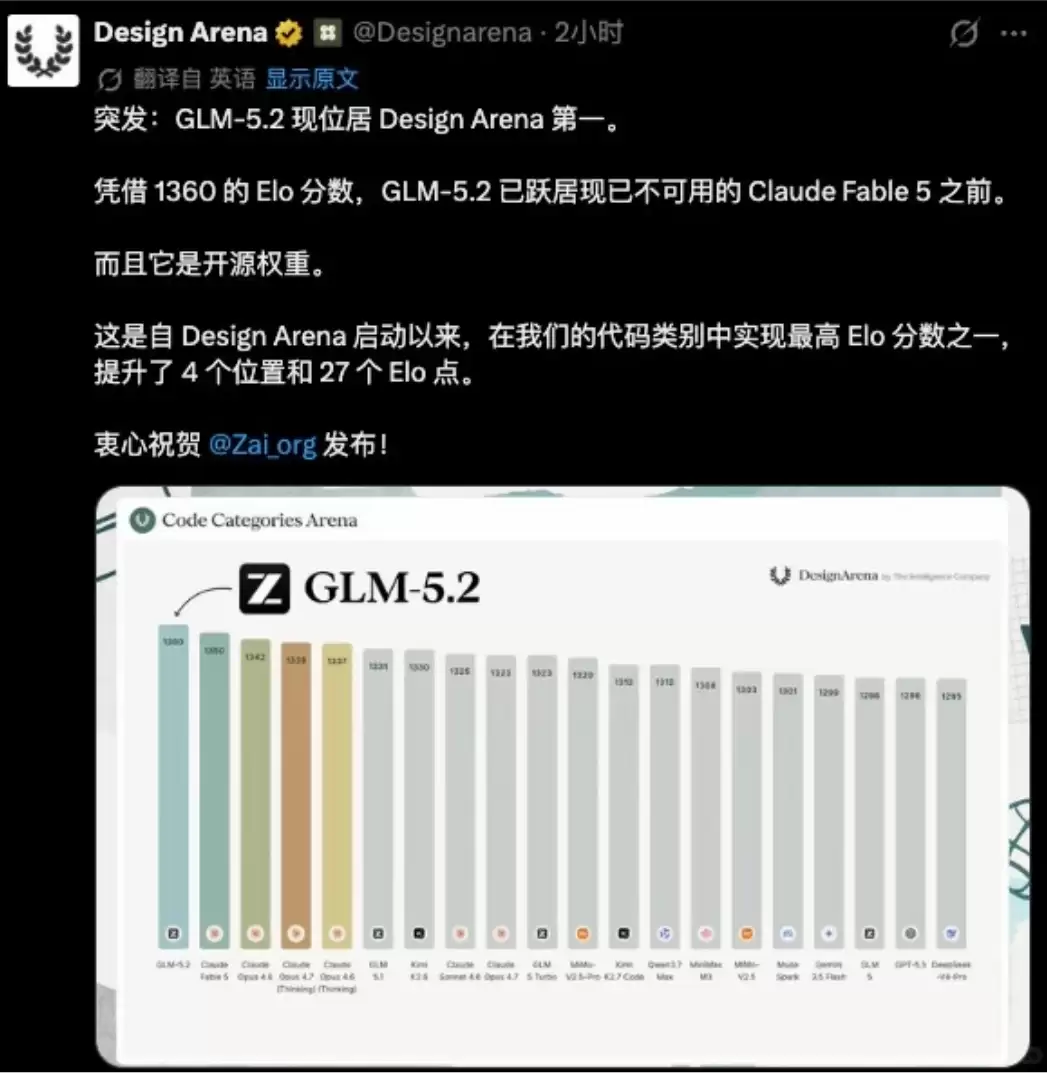
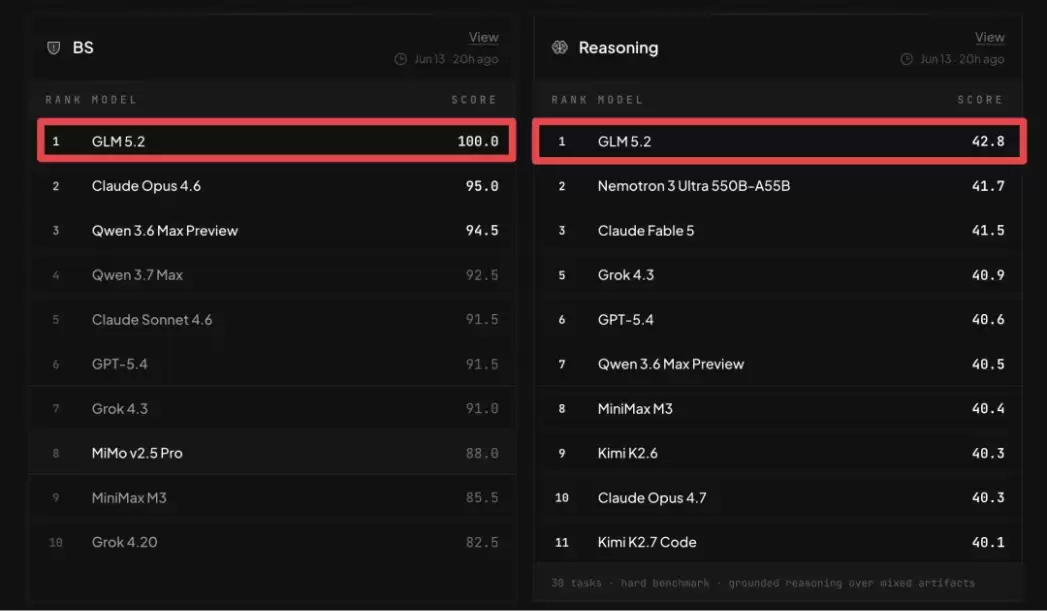
在 BridgeBench BS(抗幻觉测试)中同样位列第一,精准度达到 100.0 分;推理能力评分 42.8,同样位居榜首。
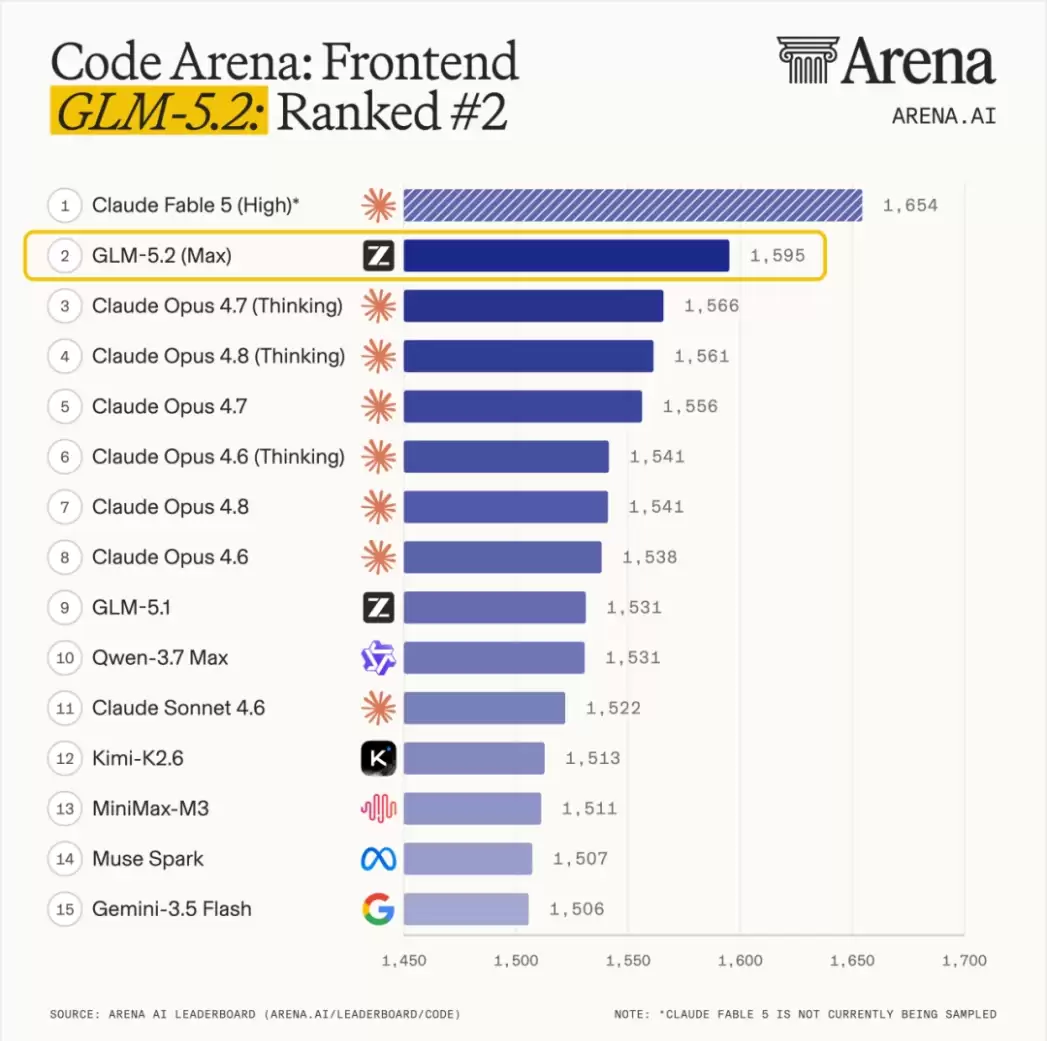
在前端代码评测平台 Code Arena: Frontend 中,它排名第二,以 29 分的优势领先 Claude Opus 4.7 (Thinking),仅稍逊于尚未公开的 Fable 5。
不过,让人好奇的是——传说中的 Claude Fable 5 究竟在哪里?至少我们暂时用不上。全球顶尖的编程模型因政策禁令无法使用,而 GLM-5.2 却将同等水平的代码能力免费开源,面向所有人开放。

当然,榜单成绩固然亮眼,但实践才是检验真理的标准。我们需要亲自测试,一方面验证模型的真实表现,另一方面评估它是否贴合自己的实际工作流程。毕竟每个人的开发习惯和使用场景各不相同。本次测试围绕代码生成和日常任务两大方向进行。话不多说,直接进入实测环节。
01. GLM-5.2 实测表现
Case 1: 百万级上下文测试
GLM-5.2 本次重大升级之一便是支持百万级上下文窗口,这无疑值得重点测试。我们提供了一份超长的产品需求文档,要求它据此生成“K姐食堂”APP 的完整设计稿。
提示词:根据文档需求,完成K姐食堂APP的设计。
...(此处省略超长 PRD 文档内容)...

测试结果令人惊喜:完成度极高,每个 UI 组件均可直接交互。覆盖面完整——共生成 19 个界面,囊括首页、店铺页、规格弹窗、订单确认、订单详情、售后、评价等核心页面。后台管理部分同样设计到位,包括数据看板、订单管理、售后管理。后续只需补充交互细节、状态流转、真实素材与响应式适配,几乎就是一款可交付的完整 APP。
Case 2: 3D 太阳系
接下来是经典的 3D 项目测试,也是每次模型评测的保留曲目。
提示词:做一个可交互的 3D 太阳系页面。要求使用 Three.js,行星围绕太阳公转,轨道可见,点击行星后侧边面板显示信息,支持播放/暂停、速度调节、视角拖拽、滚轮缩放,手机端适配。
实际效果令人惊艳。所有行星悉数呈现,交互功能一应俱全:点击、拖拽、缩放、暂停、速度调节、重置视角均支持。可以明显感受到模型对 Three.js 基础库的掌握、页面整合能力以及交互实现能力都非常扎实。
Case 3: 射击游戏
再来测试射击游戏开发能力,验证模型在游戏创作领域的表现。
提示词:请输出完整单文件 HTML,用 Canvas 做一个类似《雷电》的竖版射击游戏。包含玩家战机、敌机、子弹、碰撞检测、爆炸效果、分数、生命、关卡、暂停、Boss 战以及手机端操控按钮。
实际体验了十几分钟,沉浸感十足。战机、Boss、子弹、音效一应俱全,甚至加入了屏幕震动特效。游戏玩法结构完整,可见 GLM-5.2 深入理解了竖版射击游戏的核心架构,能够独立搭建主循环、实体系统、碰撞检测、移动端控制及视觉效果。
Case 4: Bug 修复
接下来考察 Bug 修复能力。本次修复对象是一个甘特图 HTML 文件,这类场景比普通表格更能检验模型的前端状态设计功底。
提示词:下面是一段有 bug 的单文件 HTML,目标是做一个销售趋势图,其中包含数据访问错误、Chart 实例重复创建、缺乏响应式、缺少 KPI 数据展示和图表类型切换等问题。请修复代码,并输出修复后的完整 HTML。
修复前的效果图显示数据切换异常;修复后的版本相当完善,补充了 KPI 区域、图表类型切换、响应式设计、空状态保护。说明模型不仅能精准定位原始 Bug,还能主动优化产品体验。总体来看,GLM-5.2 的前端 Bug 修复能力可圈可点,能定位核心问题并补全缺失的交互逻辑。
Case 5: 网页制作
审美本身也是模型能力的重要维度。要求 GLM-5.2 为名为“LumaNote”的 AI 笔记产品生成一个官网首页。
提示词:生成一个完整的单文件 HTML 官网,包含首屏产品展示、核心工作流、功能亮点、适用人群、价格方案和 FAQ 等区块。设计要求成熟 SaaS 风格,克制清爽,有高级感。
打开生成的官网页面,第一眼还以为是某款成熟 AI 工具的官网。暖纸色背景、深色主按钮、细边框、低饱和棕色强调色,搭配舒适。整体设计已跳出过去堆砌渐变卡片的阶段,审美在线。
Case 6: 中文写作
大模型的中文写作水平深受普通用户关注,毕竟文案工作是许多上班族的核心需求。
提示词:根据材料写一篇公众号文章,主题是“AI 工具进公司一年后,真正有用的地方和没用的地方”。要求开头直接进入场景,有个人判断,写清楚 AI 帮到了哪里、没帮到哪里,以及为什么新人和老手效果不同。
文章生成迅速,整体阅读流畅,开头立刻抓住读者。关于“新人 vs 老手”的对比部分尤其出彩,流露出真实的管理经验,比单纯罗列工具优缺点更有记忆点。如果满分 100 分,本次写作能力可给到 85 分。
Case 7: 指令遵循
不少模型在执行复杂指令时容易出错,来看看 GLM-5.2 的表现。
提示词:根据规则处理文本。规则包括:最终答案只能输出 4 条项目符号,每条少于 18 个中文字,必须保留原文里的数字,不要出现“提升”“优化”“打造”等词。

结果令人满意:输出了 4 条项目符号,每条均少于 18 个汉字,保留了原文数字,并成功绕开了禁用词汇,完全满足约束条件。
Case 8: 经典陷阱题
提示词:我要去洗车,我家离洗车店 50 米,我是开车去好,还是走路去好?

模型并未掉入逻辑陷阱,反而贴心地建议:先走路去洗车店,等车洗好再开回去。
Case 9: PPT 制作
提示词:根据材料制作一份 8 页以内的 PPTX,主题是“AI 工具在内容团队的落地方案”。要求包含封面、现状问题、目标、流程设计、岗位分工、风险控制、试点计划、结尾页,风格稳重商务。
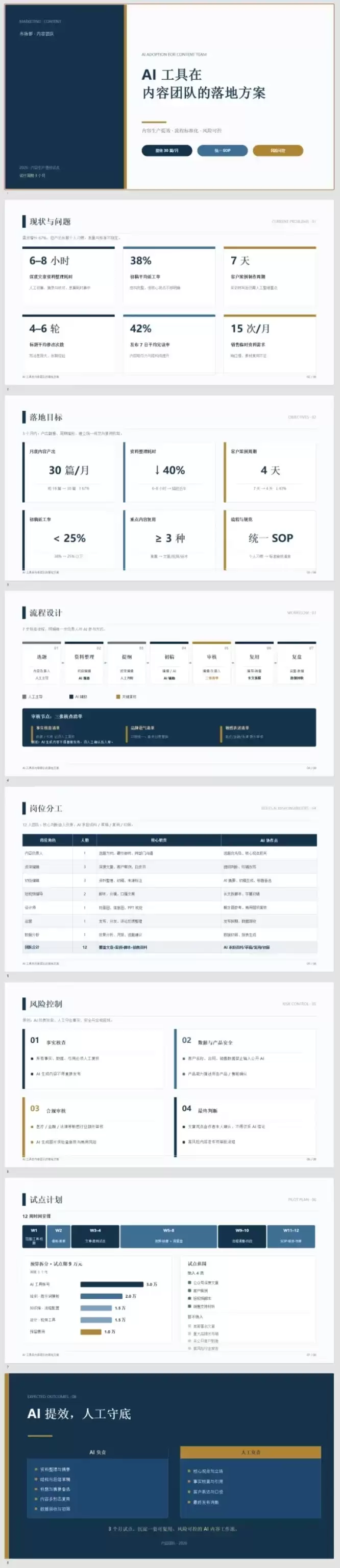
任务完成度达标。可以看出模型对项目内容理解透彻,审美也符合商务风格需求。生成的 PPT 可直接使用,人工稍作精细化调整即可交付汇报。
02. 实测小结
整个 GLM-5.2 测试下来,感觉前面的榜单排名或许并没有水分。测试结果相当强劲,已经达到国内模型领域的顶尖水准。它不仅能跑、能用,而且用得舒心。过去上班时那些资料整理、代码初稿、页面搭建、PPT 框架、测试样例,现在都可以交给模型先出一版,让人力聚焦于判断与取舍。对 GLM-5.2 的评价是:上限很高,完成度稳定,已经值得纳入日常工作流认真试用。至于能否长期扎根,还需观察后续高频使用时在细节、稳定性和成本方面的表现。或许未来接入 API 时,都分不清接的是 GLM-5.2 还是 Claude Opus 了。




