近期,清华大学新闻与传播学院新媒体研究中心携手人工智能学院,正式发布了一份由张家铖博士后撰写的深度报告——《DeepSeek与AI幻觉》。该文档系统剖析了大模型领域一个既引人入胜又令人困扰的现象:AI幻觉。究竟什么原因触发了这类幻觉?我们应当如何评估并有效应对?更为关键的是,这种看似“缺陷”的能力,是否也潜藏着出人意料的实用价值?本文将围绕这份报告的核心发现,展开详细解读。


AI幻觉的基本定义
通俗而言,AI幻觉是指模型生成了与事实不符、逻辑断裂或完全脱离上下文语境的内容。其根源在于模型基于统计概率做出的“最合理推测”出现了偏差。报告将AI幻觉明确划分为两大类别:
- 事实性幻觉:生成内容与客观现实存在矛盾。举例来说,模型错误地建议“糖尿病患者可用蜂蜜替代糖”。
- 忠实性幻觉:生成内容未能遵循用户指令或给定上下文,擅自“发挥”,导致答非所问。
这两种幻觉形式,构成了我们在与AI交互时可能遭遇的“信息陷阱”。

DeepSeek产生幻觉的深层原因
幻觉并非某一模型的专属缺陷,而是当前大语言模型架构下的普遍挑战。报告深入揭示了四大核心成因:
- 数据偏差:模型从海量训练数据中学习,若数据本身含有错误、片面或过时信息,模型便会放大并输出这些偏差。
- 泛化困境:当遭遇训练数据中未曾覆盖的复杂、新颖或边缘化场景时,模型的推理能力容易失效,从而诱发幻觉。
- 知识固化:模型的知识被“冻结”在训练完成的参数中,缺乏像人类那样持续、动态更新知识的能力,面对新信息时易出错。
- 意图误解:当用户提问模糊、存在歧义或隐含假设时,模型可能误判核心意图,进而生成看似合理却偏离本质的答案。

AI幻觉的评测方法
如何量化模型“信口开河”的倾向?报告介绍了当前主流的评测方案:
- 通用性测试:通过随机生成大量通用提示语,由人工判断回答中是否存在幻觉,从而计算模型的“幻觉率”。
- 事实性测试:从多个领域抽取具有明确答案的测试题,通过比对模型回答与标准答案,标注幻觉的具体类型和比例。
基于这些方法,报告对比了DeepSeek V3、DeepSeek R1、Qianwen 2.5-Max、豆包等主流模型的幻觉表现,为模型选型提供了重要参考依据。
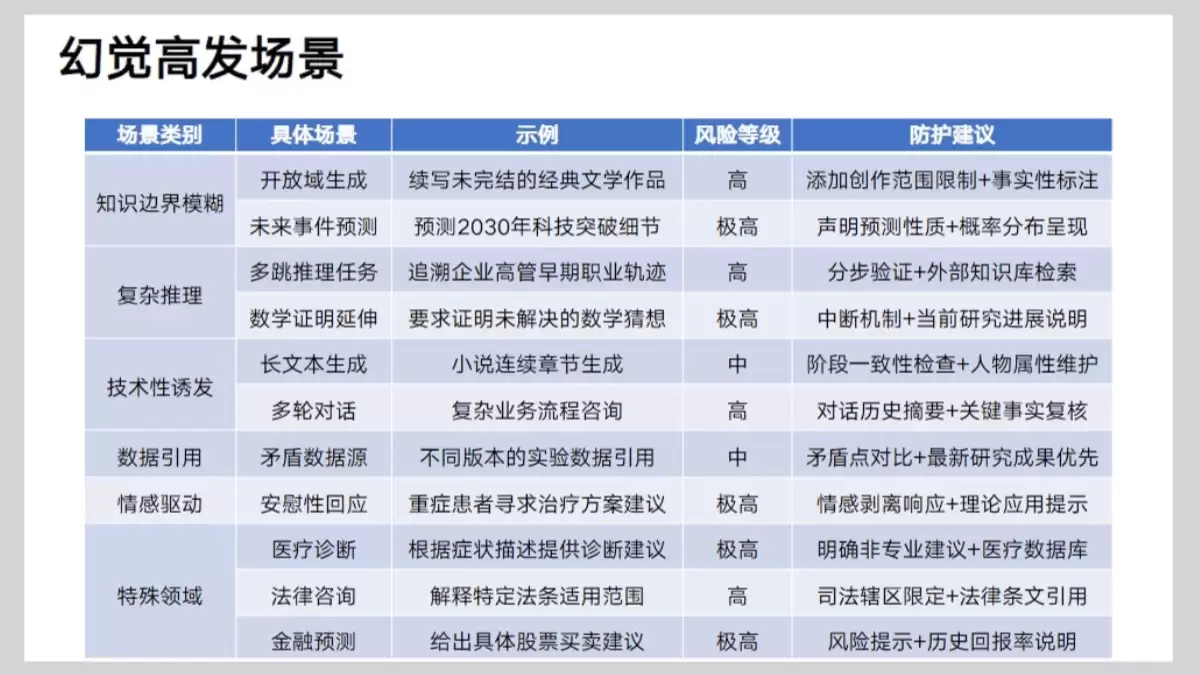
如何有效减缓AI幻觉
面对幻觉,我们并非束手无策。报告从技术方案和用户应对两个维度给出了切实可行的策略。
技术方案层面:
- 利用联网搜索:让模型实时检索最新、最权威的外部信息,是降低事实性幻觉最直接有效的手段之一。
- 双AI验证或大模型协作:让不同模型对同一问题进行回答并交叉验证,可有效发现并过滤单一模型的输出偏差。
- 提示词工程:通过精心设计提示词,例如明确限定知识边界(如“请仅基于以下资料回答”)、采用对抗性提示(如“请逐步推理并检查每一步的事实准确性”)等,能显著引导模型生成更可靠的回答。
用户应对方式:
- 三角验证法:对于关键信息,不要依赖单一AI回答。建议交叉比对多个AI模型的输出,或进一步查询权威信源(如学术论文、官方数据)。
- 警惕“过度合理”的回答:那些听起来极其流畅、完美无缺但缺乏具体引用或可验证细节的回答,尤其需要审慎对待。
- 理解并善用幻觉:在创意生成、头脑风暴等场景,AI的“幻觉”反而可能打破思维定式,激发出人意料的灵感。
AI幻觉的创造力价值
这或许是报告中最具启发性的观点:AI幻觉并非全是糟粕,在特定领域,它可以从“缺陷”转化为“特性”,甚至成为创新的催化剂。
- 科学发现:在蛋白质结构预测、新材料设计等领域,AI“天马行空”的猜想有时能启发研究人员发现传统方法未曾想到的全新结构或路径。
- 文艺与设计:AI可作为“超现实引擎”,生成突破人类常规审美和叙事逻辑的艺术作品、故事框架或设计概念,提供全新的创意火花。
- 娱乐与游戏:在构建虚拟世界、生成角色背景、创作分支对话和诗歌时,一定的“幻觉”能极大增强内容的丰富性和沉浸感。
- 技术创新:对幻觉机理的深入研究,反而推动了相关检测和纠偏技术的发展。例如,通过分析自动驾驶系统在极端场景下的“感知幻觉”,可提升其识别精度和鲁棒性。
归根结底,AI幻觉如同一面双棱镜。一方面,它折射出当前大模型在追求确定性知识上的技术局限性;另一方面,它也意外地照亮了机器智能在创造性思维上的潜在可能性。如何在可靠性与创造性之间找到平衡点,将是未来AI发展与应用的核心课题之一。





