AMD研究发现FP4训练不稳定根源并非随机性不足

在原生 FP4 硬件上实现端到端 9-10% 的训练加速
大模型训练的成本压力,一直是悬在行业头顶的达摩克利斯之剑。降低训练精度,是公认的破局关键。DeepSeek-V3 采用 FP8 训练,将成本压至 560 万美元,已经让业界看到了显著成效。
那么,一个很自然的问题随之而来:既然 FP8 可行,精度能否进一步下探到 FP4?理论上,FP4 的计算吞吐潜力是 FP8 的两倍。NVIDIA 的 Blackwell 和 AMD 的 MI350 系列,都已经在硬件层面原生支持了 FP4 运算。硬件似乎已准备就绪,但软件和算法侧却卡在了一个顽固的难题上:
用 FP4 从头训练大模型,过程极不稳定。
过去两年,LLM-FP4、NVFP4 预训练等研究陆续尝试,但鲜有方案能干净利落地在 4 比特精度下跑完全流程预训练,同时保持接近 FP8 的收敛质量。更棘手的是,崩溃的根源一直模糊不清,普遍分析认为,问题可能出在随机性不足上。
然而,最近由 AMD 联合宾夕法尼亚州立大学发布的一篇论文,碘伏了这一传统认知,为原生 FP4 训练提供了一个全新的、清晰的诊断。

- 论文标题:Pretraining large language models with MXFP4 on Native FP4 Hardware
- 论文链接:https://arxiv.org/abs/2605.09825
这项研究在 AMD Instinct MI355X GPU 上,使用 MXFP4 格式成功完成了 Llama 3.1-8B 模型的全流程预训练。最终,端到端的训练速度比 FP8 基线快了 9-10%,而 token 开销仅增加了 8-9%。这是目前首个在原生 FP4 硬件(非软件模拟)上完成大模型预训练的完整实验。
更重要的是,论文揭示了核心问题的本质:FP4 训练不稳定性的根源,并非随机性不足,而是结构性的微缩放误差沿着敏感的梯度路径被累积并放大了。
MXFP4 是什么
在深入拆解论文之前,有必要先理解 MXFP4 这一数据格式。
传统的整数量化通常为整个张量使用一个统一的缩放因子。MXFP4 的核心设计在于「微缩放」:它将一个张量切分成小块(例如每 32 个元素一组),为每个小块分配一个共享指数(采用 E8M0 格式),块内的每个元素则用 4 比特浮点数表示。其重建公式可以表述为:
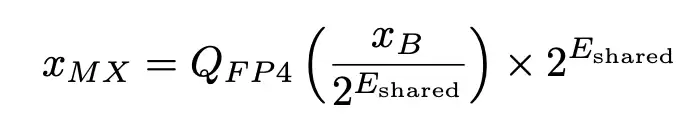
其中,E_shared 是块内的最大指数,Q_FP4 是经过最近舍入后得到的 4 比特浮点可表示值。
微缩放的优势在于,每个小块拥有独立的动态范围,从而避免了被全局异常值“绑架”。这使得 4 比特浮点数的表示质量,远优于朴素的全局量化方法。
但即便有了微缩放,FP4 训练依然不够稳定。
排查实验:不稳定的根源
研究团队设计了一套逐步排查的控制实验来定位问题。
一次完整的 Transformer 线性层计算,涉及三个通用矩阵乘法操作:
- Fprop(前向传播):计算 Y = XW^T,产出激活值。
- Dgrad(激活梯度):计算 ∇X = ∇Y · W,将梯度回传给输入。
- Wgrad(权重梯度):计算 ∇W = (∇Y)^T · X,产出用于更新权重的梯度。
研究团队保持其他所有因素不变,逐步将这三个操作从 FP8 替换为 MXFP4,观察每一步对模型收敛的影响。所有实验均在 AMD Instinct MI355X 上使用原生 FP4 Tensor Core 执行,不依赖任何软件模拟。
训练任务采用 MLPerf 标准设置,在 C4 数据集上预训练 Llama 3.1-8B,收敛目标为验证集困惑度达到 3.3。
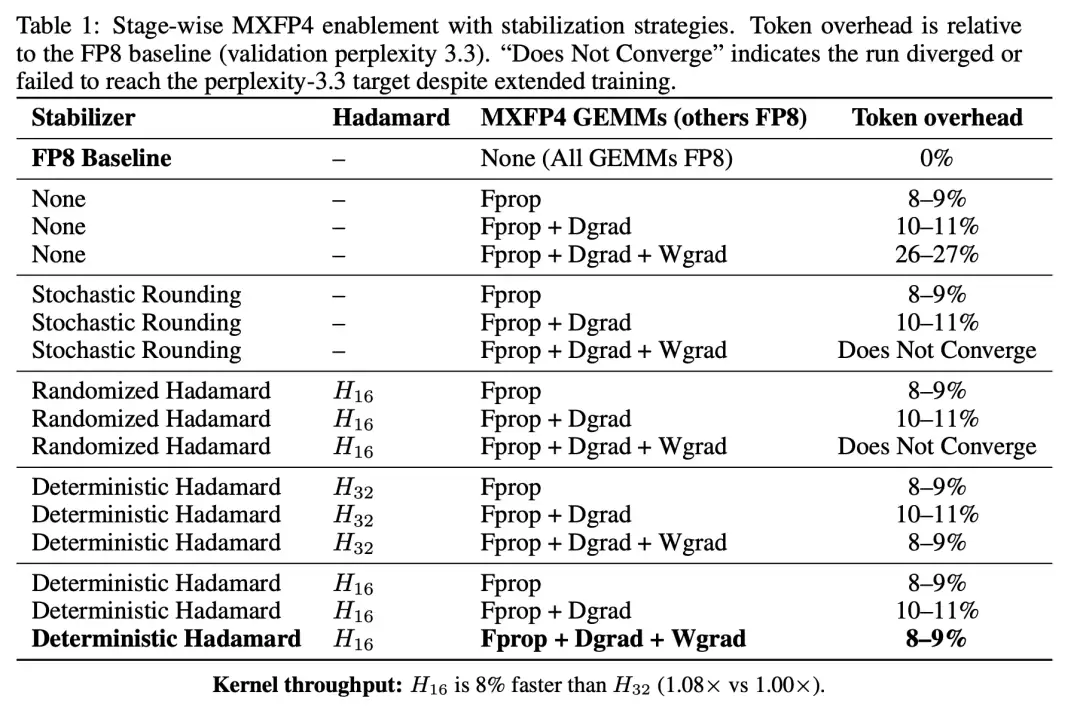
实验结果显示,前两步(Fprop 和 Dgrad)替换为 MXFP4 仅带来了温和的额外 token 开销。然而,一旦将 Wgrad 也替换为 MXFP4,开销便急剧跃升至 26-27%。
Wgrad 是 FP4 训练的瓶颈所在。前向传播和激活梯度对 FP4 量化表现出相当的容忍度,但权重梯度一旦被量化到 4 比特,收敛质量便出现显著退化。
业界此前的普遍直觉是,FP4 量化误差本质上是噪声问题,因此可以通过注入随机性来“平滑”误差分布。两种常见策略是:
- 随机舍入:在量化时引入随机性,使舍入误差的期望值为零。
- 随机 Hadamard 旋转:在量化前,使用带有随机符号翻转的 Hadamard 变换来打散数据分布。
然而,当 Wgrad 被量化后,这两种随机性策略不仅未能稳定训练,反而直接导致了训练不收敛。随机性非但没有起到帮助作用,反而在关键的梯度路径上引入了更多有效的量化误差。
相比之下,确定性的 Hadamard 旋转一举将全流程的 token 开销从 26-27% 压缩回 8-9%,训练轨迹紧密跟踪 FP8 基线。
这是一个极具诊断价值的结果。随机和确定性的 Hadamard 旋转都是正交变换,理论上都能打散异常值的能量分布,对量化误差的缓解效果应该类似。但它们在 Wgrad 场景下的表现却截然相反,这揭示了问题的本质:
FP4 训练的不稳定性,是由 MXFP4 微缩放在敏感梯度路径上产生的结构性误差所驱动的。随机性策略之所以失败,是因为它们在每一步引入了不同的误差模式,而这些变化的误差模式沿着梯度路径累积,反而放大了不稳定性。确定性旋转之所以有效,恰恰是因为它在每一步施加了相同的变换,使得误差模式保持一致,从而避免了误差的灾难性累积。
端到端效率:训练步吞吐 +20%,综合加速 9-10%
在应用确定性 Hadamard 旋转并启用全流程 MXFP4 之后,效率数据如下:

训练步吞吐提升了 20%,扣除多出的 8-9% token 开销后,端到端的综合加速仍能达到 9-10%。
考虑到这是将精度从 8 比特直接削减到 4 比特,这样的收敛质量和加速幅度都相当可观。
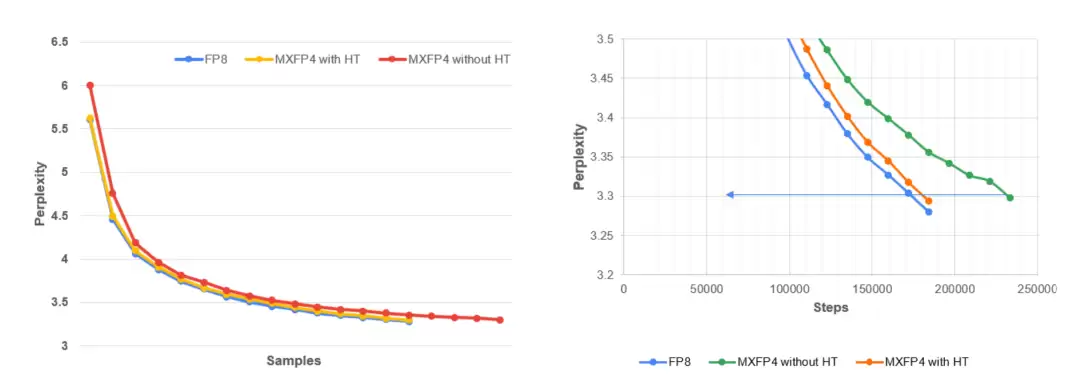
左图展示了在 C4 数据集上进行 MLPerf 预训练时,Llama 3.1–8B 的验证困惑度随训练 token 数变化的曲线。结果显示,MXFP4 + 确定性 Hadamard 与 FP8 基线的表现非常接近,而未进行稳定化处理的全流程 MXFP4 则收敛更慢,稳定性也更差。右图是训练后期的局部放大视图,MLPerf 的目标困惑度为 3.3。可以清晰看到,与未稳定化的 MXFP4 运行相比,采用确定性 Hadamard 旋转的方案能够与 FP8 基线保持更紧密的一致性。
需要特别指出的是,论文作者明确强调了一项重要限制:这套 FP4 训练方案(在 MLPerf C4 数据集 + Llama 3.1-8B 上)的效果已得到验证,但不能直接假设它能无缝迁移到所有模型、数据集和训练方法。FP4 训练的行为可能是高度依赖于具体设置的,针对不同场景的稳定策略需要重新验证。
结语
将这篇论文置于更广阔的产业脉络中审视,至少有三层意义。
第一层,它回答了一个根本性的“为什么”。过去的 FP4 训练研究大多聚焦于“如何让它不崩溃”,而这篇论文首次给出了清晰的因果诊断:崩溃源于 Wgrad 路径上的结构性微缩放误差,而非随机性不足。这个诊断本身具有方法论价值,它指引后续研究者在遇到低精度训练不稳定性时,应优先排查结构性误差源,而非盲目增加随机性。
第二层,它将 FP4 从“推理专属”推向了“训练可用”。此前的行业共识是 FP4 仅适合推理量化,训练至少需要 FP8。NVIDIA 在 Blackwell 架构上主推 FP4 推理而非训练,也反映了这一判断。这篇论文在原生 FP4 硬件上跑通了全流程预训练,意味着 MI355X 和 Blackwell 上那些为推理准备的 FP4 算力,理论上也可以用于训练。如果 FP4 训练在更大模型和更多场景中得到验证,现有硬件的可用训练算力将有望直接翻倍。
第三层,它基于 OCP 开放标准。MXFP4 是 OCP Microscaling 格式标准的一部分,其背后有 AMD、NVIDIA、Intel、Meta、Microsoft、Arm、Qualcomm 七家公司的联合支持。基于开放标准意味着这套方法在不同厂商的硬件上具备可移植性,不会被锁定在单一生态中。
从 FP16 到 FP8,DeepSeek-V3 已经证明精度减半可以大幅降低训练成本。从 FP8 到 FP4,这篇论文迈出了关键的第一步。精度每削减一次,整个大模型训练的经济性都在发生深刻转变。

相关攻略

这款硬朗像素风无衬线字体,带你体验未来感设计与9档字重自由 一、全文速览图 二、字体简介 本期免费商用字体:Sinkin Sans,由英国专业字体工作室K-Type出品。这是一款融合了inktrap凹槽工艺的现代无衬线体,兼具优雅气质与实用性能,视觉上现代而不失温度,清晰易读,辨识度极佳。全家族共提

基于Langchain-RAG实现网页摘要检索工具,通过WebBaseLoader加载网页并分割文档,构建向量存储和检索器。采用两种摘要方法:检索链结合文档链生成问答式摘要,或使用内置摘要链直接总结。需注意通过提示词模板显式控制输出语言,避免默认英文输出。

Roland是一款免费可商用的复古装饰字体,灵感源自中世纪哥特书写传统,融合历史厚重感与现代视觉张力。提供Regular、Contour、Shadow三种字重,适用于复古海报、文创包装、品牌标识等场景,无需署名,无隐藏条款。

QoderWake作为数字程序员需绑定身份与权限,通过监听仓库事件自动生成代码变更并创建PullRequest,随后在沙箱环境执行单元测试与集成验证,测试失败时输出分层诊断。最终生成交付包,经指定角色审批后方可合并部署,确保全流程可控可追溯。

QoderWake脚本执行错误可通过日志定位。调试核心五步:启用详细日志模式并重定向输出;按时间戳与进程ID筛选关键日志段;检查脚本内嵌变量与路径解析结果;复现失败步骤并注入临时调试语句;验证Python解释器与依赖模块兼容性。
热门专题







热门推荐

《Paralives》开发商承诺所有后续更新永久免费,拒绝付费DLC模式。15人小团队依靠首发销售额即可支撑多年运营,无需依赖额外内容包维持开发,展现了与《模拟人生》系列不同的差异化竞争思路。

2025年5月28日,比亚迪王朝网全新力作——宋Ultra DM-i正式推向市场,共推出5款配置车型,官方售价区间为12 99万至15 99万元。此次定价策略极具突破性:一款拥有310公里纯电续航能力的中型插电混动SUV,直接下探至13万元级别市场。作为王朝网络的新旗舰,该车明确瞄准高频出行需求场景

先来关注一个有趣的细节:苹果首款折叠屏手机,传闻将于今年秋季正式亮相。产品命名可能为iPhone Ultra,也有媒体称之为iPhone Fold——无论最终叫什么,这都将标志着苹果在折叠形态领域首次“出手”。 近日,配件厂商iFunSmart已率先上架iPhone Ultra的首批保护壳——这绝非

山寨币ETF迎来批量上市潮,首批项目市场表现如何?一文分析 Binance币安 欧易OKX ️ Huobi火币️ 最近,市场出现了一个不容忽视的新动向:XRP、DOGE、LTC、HBAR等现货ETF已经悄然登陆美国市场。与此同时,A VAX、LINK等资产的同类产品也正在审批流程中。进入11月以来,

近日,公司对SteamDeck1TBOLED版涨价300美元至949美元,上架短短不到24小时便再度售罄。据外界分析,该公司从中国大量补货并分批投放库存,高溢价未影响众多玩家的抢购热情与速度,其人气极其旺盛无比足以支撑快速清空。