大模型需要睡眠休息 短暂休眠后AI表现更出色
7×24小时不间断运行,别说人类会疲劳,连AI模型也撑不住。
近期,卡内基梅隆大学与马里兰大学的科研团队发表了一篇引人深思的论文,标题直接点明核心——《语言模型需要睡眠》。研究指出一个关键发现:大语言模型在处理长上下文任务时,如果持续运行而不“休息”,其性能确实会出现显著下降,这与人脑在过度劳累后思维迟钝的现象颇为相似。

这项研究的灵感,正是来源于我们最了解的生物系统——人类大脑。
众所周知,人类在睡眠期间,海马体会对日间的短期记忆进行多次“重播”,最终将这些记忆巩固到大脑皮层的神经连接中,转化为长期知识。研究团队认为,这一机制完全可以借鉴到人工智能模型的优化中。他们设计了一套“AI睡眠机制”,让大模型在上下文窗口即将满载时,不是强行继续,而是主动“休眠片刻”,将最近的上下文信息进行多轮深度处理与压缩,将其整合进模型的长期权重参数中,随后清空临时缓存,以更轻盈的状态“苏醒”并继续工作。

实验数据有力地支持了这一构想。适度增加模型的“睡眠”迭代轮次,能够明显提升其在深度推理类任务上的表现。尤其是对于那些需要层层递进、多步逻辑推导的复杂问题,任务难度越高,模型似乎就越需要通过更长的“睡眠”来进行内部信息整合。
那么,这背后的技术原理究竟是什么?
大语言模型为何需要“睡眠”?
要深入理解这个问题,需要从Transformer架构的核心——注意力机制(Attention Mechanism)谈起。注意力机制存在一个固有局限:随着上下文长度的增加,其计算复杂度呈平方级增长,用于存储历史信息的键值(KV)缓存也会线性膨胀。
这意味着,执行相同的推理任务,一个拥有8K上下文窗口的模型与一个128K上下文窗口的模型,其计算资源消耗存在巨大差异。额外消耗的算力,主要用在了对海量历史信息的关联与计算上。
目前行业主要存在两种应对长上下文的思路:
第一种是“强制遗忘”。当缓存满时,直接丢弃最早的信息。但被丢弃的信息对模型而言等同于从未输入,这会严重破坏任务处理的连贯性与逻辑完整性。
第二种是近年来兴起的状态空间模型(SSM)与注意力机制的混合架构,例如Samba、Qwen3.5等模型就采用了此类设计。

混合架构提供了一种折中方案:将相对不紧急的历史信息压缩进“快速权重”(Fast Weight)中,不占用宝贵的KV缓存空间,同时保留随时调用的能力。这确实缓解了内存压力,但研究团队发现,即便快速权重容量充足,当推理步骤变得极其冗长、逻辑链条异常复杂时,模型的性能依然会出现衰退。
这表明,当前面临的瓶颈可能已不再是信息存储能力不足,而是模型在深度推理与信息内化能力上存在局限。
关键在于,历史信息在被移出KV缓存之前,模型通常只有一次前向传播的机会来完成对信息的“理解”与“吸收”。对于简单的信息提取任务,单次处理或许足够;但对于需要拆解、重组、进行多步逻辑推导的复杂问题,单次处理就显得力不从心。
这一现象与人脑的工作机制高度相似。人类在白天经历一系列复杂事件后,并非当场就能完全理解消化。大脑的策略是,在夜间睡眠、外部刺激暂停时,再集中资源进行深度信息处理。
睡眠期间,海马体会对白天的关键记忆片段进行多轮“重播”,通过这种反复的神经活动,将短期记忆巩固为大脑皮层中的结构化长期知识。这个过程必须是离线的——你需要先“入睡”,暂时关闭对外部信息的接收,大脑才能集中算力进行深度“消化”。而且,一遍往往不够,需要多轮重复才能达到理想的巩固效果。
AI模型的“睡眠”机制是如何实现的?
研究团队正是将人脑这套完整的“睡眠-记忆巩固”逻辑,迁移应用到了大语言模型的优化设计中。
他们的设计方案非常直观:当模型的上下文窗口即将被填满时,不令其强行继续,而是主动触发“睡眠”状态。
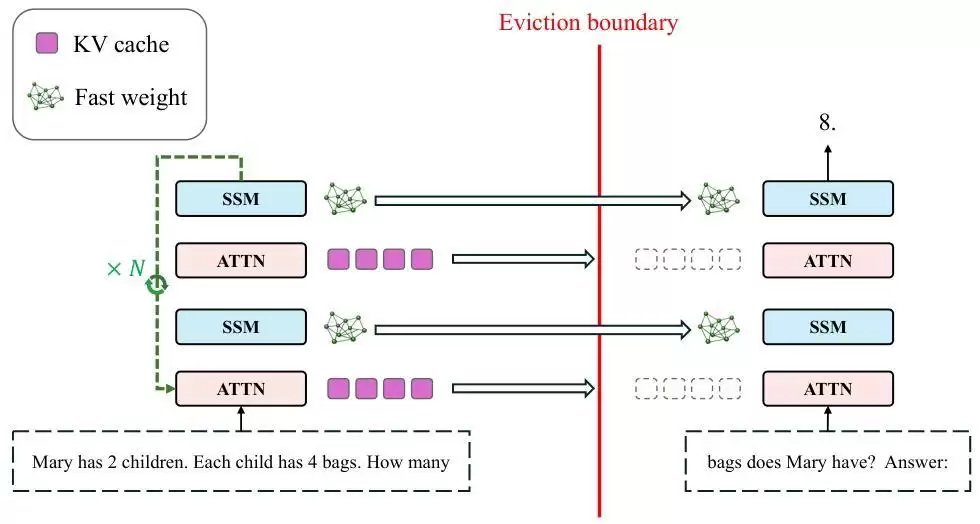
这里的“睡眠”,特指模型暂停接收新的输入token,进入纯离线处理模式,然后对已积累的全部上下文信息,执行多轮递归式的前向传播计算。
在此过程中,模型依据其内部可学习的规则,反复对已有信息进行提炼、整合与关联,逐步更新SSM模块内的快速权重,从而完成信息的深度压缩与知识内化。待“消化”过程达到一定阶段后,模型便清空KV缓存,携带更新后、蕴含更丰富结构化知识的权重“苏醒”,继续处理后续的任务序列。

从计算资源分配的角度看,所有因深度处理而产生的额外计算开销,都被集中约束在“睡眠”阶段。模型在苏醒后的正常推理流程,与常规模型完全一致,仅需一次前向传播,因此不会增加线上实时响应的延迟。
所谓的“睡眠时长”,本质上就是信息迭代处理的轮次。轮次越多,意味着模型对上下文内容的梳理、打磨与整合越充分、越深入。
为验证该机制的效果,团队选取了元胞自动机演化、多跳图关系推理以及GSM-Infinite无限长度数学推理这三类基准任务进行测试。这几类任务的共同特点是,能够精确控制推理深度和记忆负载这两个关键变量。
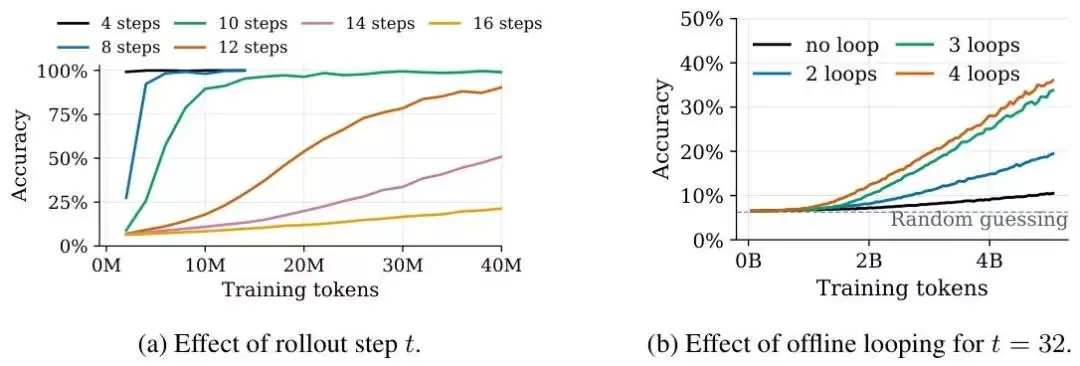
测试结果清晰地验证了假设:随着睡眠迭代轮次的增加,模型的整体性能呈现稳步提升。更重要的是,这种性能增益主要体现在高难度的深度推理任务上。对于简单问题,模型“保持清醒”即可快速解决;而对于复杂难题,它确实需要“睡一觉”,经过多轮内部深度梳理与知识巩固,才能理清复杂逻辑,找到正确答案。
由此可见,适度的“间歇性休息”是提升AI模型长上下文处理效率的有效策略。有时候,暂停接收新信息,反而能更高效地进行深度思考与知识整合。这一发现不仅充满启发性,也为优化大语言模型的长序列处理与复杂推理能力,开辟了一条受生物智能启发的新技术路径。
论文地址:https://arxiv.org/abs/2605.26099
相关攻略

2026年API聚合市场进入分层服务阶段。非线智能API凭借99 99%SLA、三协议原生兼容及全链路计费透明成为企业生产首选;硅基流动深度优化国产开源模型;APIYI适合个人轻量测试;灵犀聚合面向学术数据采集;DMXAPI擅长多模态调度;OpenRouter覆盖全球但国内延迟高。

基于容联七陌多Agent大模型架构,新一代智能客服实现原生大模型在意图理解、情绪感知与复杂任务处理上的跃升。相比传统方案,冷启动无需标注,准确率与体验显著提升,在售前、外呼、客服等场景落地后解决率最高达97%,同时降低企业成本与人工压力。

金蝶与阶跃星辰战略合作,共同研发企业服务智能体,旨在破解AI融入核心业务的集成难题。双方推动企业级AI从工具向“数字员工”跨越,聚焦业务流程,使智能体自主理解并执行任务。企业服务正成为大模型竞争的核心战场,行业趋势指向具备自主执行能力的智能体基础设施。预计2026年将成为从辅。

有时候,真不是咱们不想用国外的那些模型。就说 Anthropic 的 Dario 吧,对华那点成见摆在那儿,那还用说?不过话说回来,看看国内大模型现在的局面,其实也真挺有意思的。 单一指标看行业格局,很容易掉坑里。有些模型,C 端用户数看着挺唬人,但开发者调用的少;另一些呢,普通用户听着没那么响,可

2026年5月27日,深演智能(股票代码:2723 HK)正式在港交所主板挂牌上市,成为“企业决策AI智能体第一股”。这不仅是一次里程碑式的IPO,更标志着整个企业决策AI赛道进入成熟发展的新阶段。 当天,创始人兼CEO黄晓南带领核心团队、长期陪伴的投资人以及多位重要嘉宾,共同出席了上市仪式,共同见
热门专题







热门推荐

《Paralives》开发商承诺所有后续更新永久免费,拒绝付费DLC模式。15人小团队依靠首发销售额即可支撑多年运营,无需依赖额外内容包维持开发,展现了与《模拟人生》系列不同的差异化竞争思路。

2025年5月28日,比亚迪王朝网全新力作——宋Ultra DM-i正式推向市场,共推出5款配置车型,官方售价区间为12 99万至15 99万元。此次定价策略极具突破性:一款拥有310公里纯电续航能力的中型插电混动SUV,直接下探至13万元级别市场。作为王朝网络的新旗舰,该车明确瞄准高频出行需求场景

先来关注一个有趣的细节:苹果首款折叠屏手机,传闻将于今年秋季正式亮相。产品命名可能为iPhone Ultra,也有媒体称之为iPhone Fold——无论最终叫什么,这都将标志着苹果在折叠形态领域首次“出手”。 近日,配件厂商iFunSmart已率先上架iPhone Ultra的首批保护壳——这绝非

山寨币ETF迎来批量上市潮,首批项目市场表现如何?一文分析 Binance币安 欧易OKX ️ Huobi火币️ 最近,市场出现了一个不容忽视的新动向:XRP、DOGE、LTC、HBAR等现货ETF已经悄然登陆美国市场。与此同时,A VAX、LINK等资产的同类产品也正在审批流程中。进入11月以来,

近日,公司对SteamDeck1TBOLED版涨价300美元至949美元,上架短短不到24小时便再度售罄。据外界分析,该公司从中国大量补货并分批投放库存,高溢价未影响众多玩家的抢购热情与速度,其人气极其旺盛无比足以支撑快速清空。