谷歌多模态向量模型上线文字搜图片与图片搜视频功能
谷歌最近扔下了一颗重磅技术冲击波:首个原生多模态向量模型 Gemini Embedding 2 正式亮相。这可不是一次简单的升级,它真正实现了将文字、图片、视频、音频乃至文档,全部塞进同一个“理解空间”里。这意味着什么?意味着机器对世界的感知方式,正在从割裂走向统一。
Gemini Embedding 2上线,统一图文音视频向量空间
基于强大的Gemini架构,这个新模型已经通过Gemini API和Vertex AI开放了预览。它最核心的突破,就在于打破了模态之间的壁垒。过去,处理不同格式的数据往往需要不同的模型和流程,而现在,无论是文本、图像、视频、音频还是PDF文档,Gemini Embedding 2都能将它们映射到同一个高维向量空间中,并且能跨越上百种语言捕捉背后的语义意图。
这种“大一统”的设计,带来的直接好处就是简化。以往需要多套系统拼接的复杂流程,现在可以一站式搞定。无论是构建更精准的检索增强生成(RAG)系统,还是进行跨媒体的语义搜索、情感分析,甚至是海量多模态数据的聚类管理,效率和效果都得到了显著提升。
五大模态全面打通,支持交错输入
得益于Gemini与生俱来的多模态理解基因,新模型在各项输入规格上都相当能打:
- 文本:一口气处理8192个Token的长上下文不在话下。
- 图像:单次请求最多能“吃下”6张图片,支持常见的PNG和JPEG格式。
- 视频:能理解长达2分钟的视频片段,MP4和MOV格式都兼容。
- 音频:这一点尤其值得关注——它支持原生音频数据直接输入,完全绕过了先转成文字再处理的中间步骤,保留了声音中文字无法承载的丰富信息。
- 文档:可以直接“阅读”并嵌入最多6页的PDF文件内容。
更厉害的是,它原生支持“混搭”输入。开发者可以在一次请求中,同时传入一张产品图片、一段用户评价音频和几行说明文字。模型能够精准捕捉这些不同类型数据之间复杂而微妙的关联,从而对现实世界中混杂的信息实现更贴近人类的理解。
引入套娃表示学习,灵活调整输出维度
技术层面,Gemini Embedding 2用上了一个聪明的“套娃”技术——套娃表示学习(MRL)。简单来说,它就像一套可以伸缩的俄罗斯套娃,信息被嵌套存储在不同维度里。
这种设计给了开发者极大的灵活性。模型的默认输出维度是3072维,但你可以根据实际需求,像调节音量一样向下缩放维度,比如降到1536维或768维。这样一来,就能在模型的表现力和存储、计算成本之间,找到一个最适合自己业务场景的甜蜜点。当然,为了追求最高质量,官方还是首推3072、1536或768这三个维度。
设立多模态性能新基准
性能上,Gemini Embedding 2来势汹汹。在文本、图像和视频相关的标准测试任务中,它已经超越了现有的领先模型。而它新引入的原生音频处理能力,更是直接为“多模态”这个词设立了新的深度标准。这等于为开发者提供了一个更强大、更通用的基础工具,去应对日益多样化的嵌入需求。
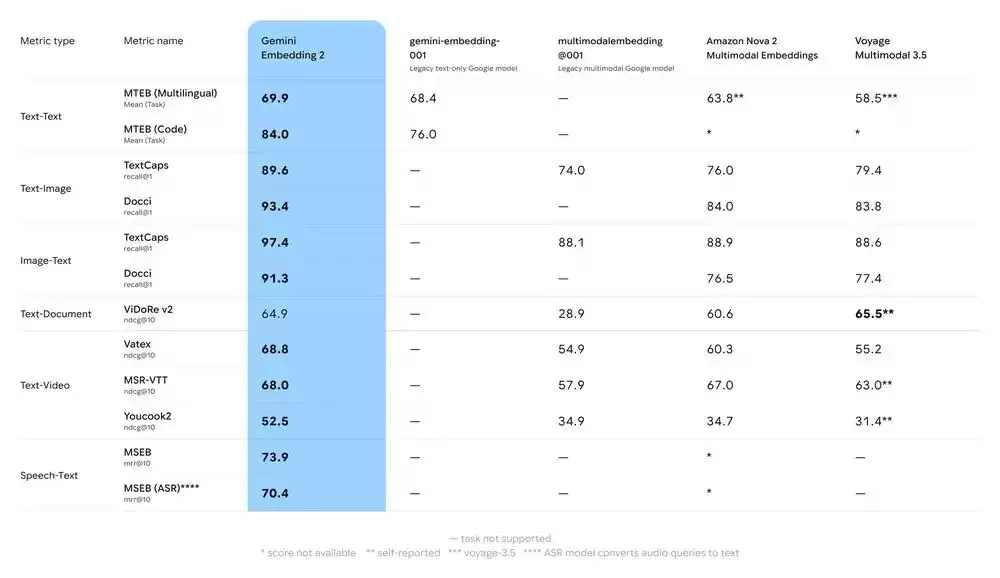
如今,嵌入技术早已是谷歌众多产品体验的隐形引擎,同时在RAG的上下文工程、大规模数据治理以及经典搜索分析等场景中也扮演着核心角色。据悉,一些早期合作伙伴已经开始利用Gemini Embedding 2,开发更具想象力的高价值多模态应用了。
开发与生态支持
对于开发者而言,接入门槛相当友好。通过Gemini API或Vertex AI就能快速用上。谷歌提供了Python SDK(google.genai),几行代码就能在单次调用中完成文本、图片和音频的联合嵌入处理:
from google import genai
from google.genai import types
client = genai.Client()
with open("example.png", "rb") as f:
image_bytes = f.read()
with open("sample.mp3", "rb") as f:
audio_bytes = f.read()
# 同时嵌入文本、图片和音频
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
"What is the meaning of life?",
types.Part.from_bytes(
data=image_bytes,
mime_type="image/png",
),
types.Part.from_bytes(
data=audio_bytes,
mime_type="audio/mpeg",
),
],
)
print(result.embeddings)
上面的代码逻辑很清晰:初始化客户端,指定预览版模型,然后在内容列表里依次传入文本字符串、以及转为字节流的图片和音频文件,模型就会直接吐出一个融合了多模态信息的向量结果。
生态兼容性方面也无需担心。除了官方提供的交互式Colab笔记本,主流的开发框架和向量数据库,像LangChain、LlamaIndex、Haystack,以及Wea viate、QDrant、ChromaDB和Vector Search等,都已经做好了支持。这意味着你可以很平滑地将它集成到现有的技术栈中,快速启动项目。
相关攻略

昨天,Google 正式发布了 Gemini 3 1 Pro。表面上看是一次常规迭代,但数据公布后,业内许多人感到惊讶——推理能力几乎翻倍,专业领域表现直逼顶级竞品,价格却保持不变。简单来说,这是一次“加量不加价”的精准打法。 先看几个核心指标:ARC-AGI-2 基准测试得分暴涨 146%,从 3

人工智能不仅是技术名词,更代表一个时代。其核心算法驱动技术发展,市场规模持续扩大,企业应用广泛提升效率。伴随应用深入,数据隐私与算法公平等伦理问题凸显。从图灵测试起,AI概念逐步演化,未来将更趋向多元融合与个性化发展,持续重塑工作与生活。

面向复杂系统的SpecMode正成为AI编程新范式。它强调先撰写结构化功能规范,明确目标、边界与约束,再驱动AI分阶段生成代码。该模式通过前置规划解决起点偏差,以书面文档避免上下文坍塌,并将决策固化以确保过程可控,尤其适用于新系统搭建、大规模重构等高稳定性工程场景。

掌握PPT生成器AI,轻松提升演示效果制作PPT早已不是简单地把文字和图片堆砌在一起。如今的演示文稿,更像是一把能清晰传达想法、生动展示内容的利器。而PPT生成器AI的出现,让专业级的演示文稿变得触手可及——无需苦学设计,无需熬夜排版。下面几个实用技巧,能帮你充分释放它的潜力。方法一:选择合适的模板

篇报告:AI在教育中的应用我记得之前分享过一个观点:AI的到来,正在碘伏我们对教育这件事的传统认知。最明显的改变是什么?个性化学习体验。简单来说,AI系统会像个聪明的观察者,分析每个学生的学习习惯和成绩数据,然后量身定制专属的学习计划。这样一来,学生不再是课堂上被动听讲的听众,而是真正参与到自己学习
热门专题







热门推荐

《Paralives》开发商承诺所有后续更新永久免费,拒绝付费DLC模式。15人小团队依靠首发销售额即可支撑多年运营,无需依赖额外内容包维持开发,展现了与《模拟人生》系列不同的差异化竞争思路。

2025年5月28日,比亚迪王朝网全新力作——宋Ultra DM-i正式推向市场,共推出5款配置车型,官方售价区间为12 99万至15 99万元。此次定价策略极具突破性:一款拥有310公里纯电续航能力的中型插电混动SUV,直接下探至13万元级别市场。作为王朝网络的新旗舰,该车明确瞄准高频出行需求场景

先来关注一个有趣的细节:苹果首款折叠屏手机,传闻将于今年秋季正式亮相。产品命名可能为iPhone Ultra,也有媒体称之为iPhone Fold——无论最终叫什么,这都将标志着苹果在折叠形态领域首次“出手”。 近日,配件厂商iFunSmart已率先上架iPhone Ultra的首批保护壳——这绝非

山寨币ETF迎来批量上市潮,首批项目市场表现如何?一文分析 Binance币安 欧易OKX ️ Huobi火币️ 最近,市场出现了一个不容忽视的新动向:XRP、DOGE、LTC、HBAR等现货ETF已经悄然登陆美国市场。与此同时,A VAX、LINK等资产的同类产品也正在审批流程中。进入11月以来,

近日,公司对SteamDeck1TBOLED版涨价300美元至949美元,上架短短不到24小时便再度售罄。据外界分析,该公司从中国大量补货并分批投放库存,高溢价未影响众多玩家的抢购热情与速度,其人气极其旺盛无比足以支撑快速清空。