618选购AI电脑前必看的五大避坑指南

618大促又来了,一年一度的设备升级窗口期也随之开启。
这不,端午节刚过,就有好几位朋友来打听我的电脑配置。我通常就甩两张图过去。

结果呢,对方往往回我一个“地铁老人看手机”的表情包,然后直奔主题:想买台学AI的笔记本,有没有推荐?

每到这时,我总会先反问一句:学AI?具体想学什么?
得到的答案五花八门:搞个知识库、画画图、做点AI编程、学学AI视频生成……
接着我会追问:你是有大量不能上云的隐私数据要处理,还是打算在本地折腾一些自定义的、特殊的工作流?
这个问题常常把朋友问住。不少人会一脸懵:啊?这些是啥?玩AI难道不是配置越高越好吗?
得,这下轮到我懵了。
所以,我觉得有必要写篇文章,好好聊聊这个话题:到底什么样的AI应用适合在本地跑,什么样的交给云端更划算,又有哪些直接打开网页就能用。权当一次科普。
如果你看完之后,确信自己确实需要一台新电脑,文末我也整理了几款个人觉得不错、且618期间价格确实有吸引力的笔记本,供你参考。
什么样的AI适合在本地跑?
判断一个AI任务是否适合本地部署,主要看两个核心维度:
- 对算力的实际需求有多大。
- 是否存在安全、保密的隐私需求。
算力需求:从参数到显存的小学数学
模型的参数量级繁多,1.5B、8B、14B、32B……比如Qwen家族,就提供了从微小到庞大的各种选择。
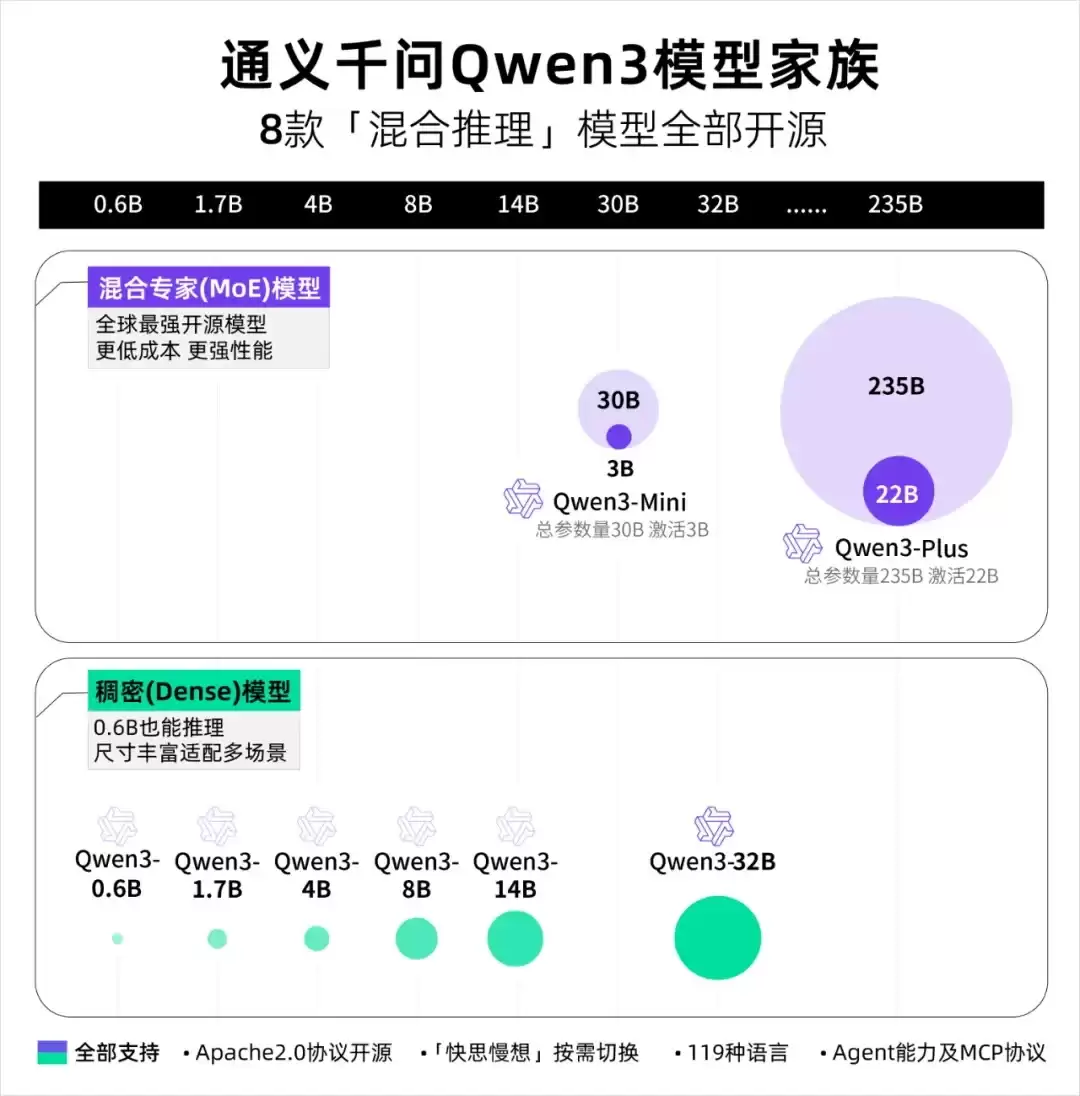
要搞清楚哪些能在本地跑,得先做点简单的计算。这里的“B”代表Billion(十亿)。一个1B的模型意味着有10亿个参数。
在传统全精度(FP32)下,一个参数占4字节,那么1B模型就需要约4GB显存。但全精度推理太奢侈,实践中我们多用半精度(FP16)或INT8量化。这样一来,一个参数分别只占2字节或1字节。
换算一下就很直观了:跑一个1B的INT8模型,只需要1GB显存;跑一个8B的INT8模型,大约需要8GB显存。虽然推理时还需要额外的显存用于上下文(KV)缓存,但结合量化、优化等手段,本地用16GB显存流畅运行一个8B量级模型,是完全可行的。
举个例子,前段时间DeepSeek基于Qwen3-8B蒸馏出的DeepSeek-R1-0528-Qwen3-8B模型,就能轻松部署在本地运行。
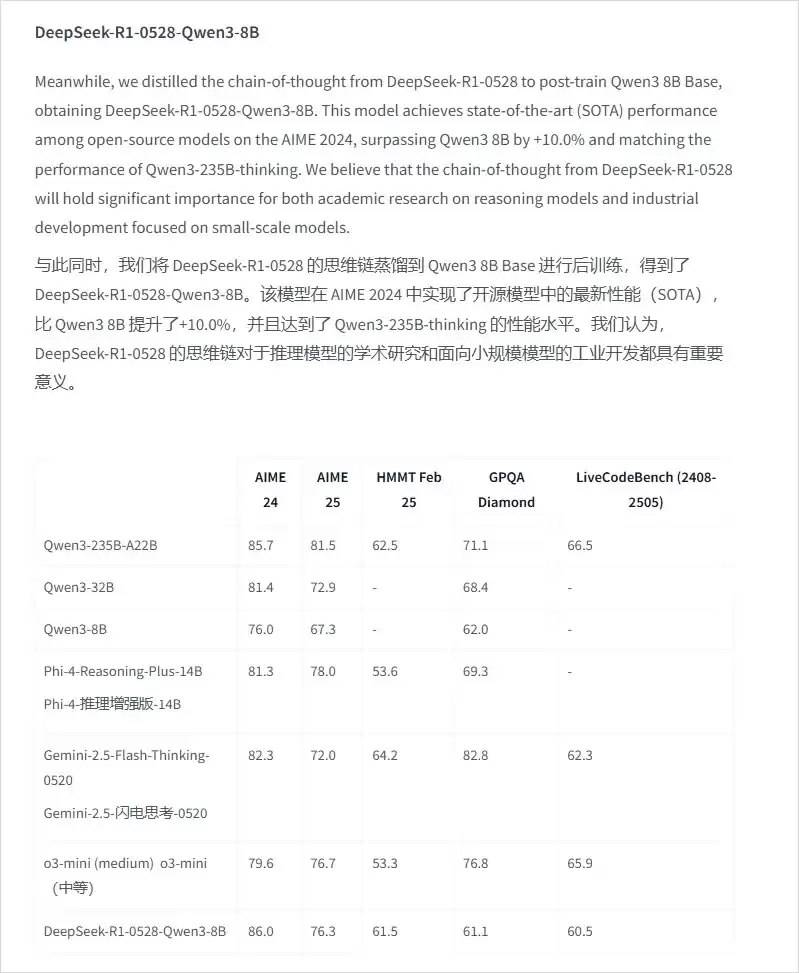
所以,无论你用的是Ollama、LM Studio还是vLLM,本地部署大模型时,只需紧盯三个指标:
- 模型的参数量。
- 模型是否经过量化(以及量化到哪种精度)。
- 你的显卡有多少显存。
一般来说,14B及以上的模型在本地运行就比较吃力了。比如一个INT8的14B模型,即使用上RTX 5080,速度也快不起来,而且KV缓存空间所剩无几。真要本地跑这个量级,RTX 4090或未来的RTX 5090会是更合适的选择。
对于14B以下的模型,就需要你根据上述公式,结合自己的显存情况做个评估了。
不止语言模型:图像、视频、3D同理
上面谈的主要是大语言模型(LLM)。那图像生成、视频生成、3D建模这些呢?道理是相通的。
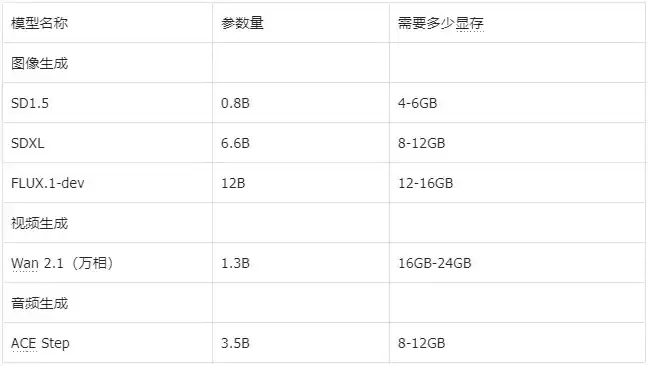
以强大的生产力工具ComfyUI为例,它能处理图像、视频、音频、3D等多种生成任务,但前提是你的显卡能“扛”得住对应的模型。
ComfyUI官方推荐了一些常用模型,它们的参数量与显存需求大致如下,可以作为参考:
为什么非得跑本地?隐私与合规是刚需
算力搞清楚后,你可能会问:本地跑到底有啥不可替代的好处?用网页版不香吗?
这就引出了第二个核心维度:隐私安全与合规性。
如果你的数据涉及商业机密、患者医疗记录、未公开的研发资料等绝对敏感信息,那么本地部署几乎是唯一的选择。所有计算都在你自己的设备上完成,数据不出本地,从根本上杜绝了泄露风险。而且,本地模型断网也能用。
知识库应用就是个典型例子。市面上有很多搭建个人知识库的教程和平台(如Dify、扣子、imaGPT等)。你可以轻松把各种文档扔进去,但如果是你公司的核心资料或个人隐私数据呢?你还敢上传吗?
隐私保护,是这类场景下最核心、没有之一的考量。一旦你有AI辅助需求,又涉及敏感数据,本地部署就是必选项。
举个极端的例子:《流浪地球3》的剧本。电影上映前,剧本泄露堪称灾难。但制作团队同样有利用AI进行视觉化预演、流程辅助的需求。这种级别的保密资料,谁敢扔到ChatGPT、Claude、DeepSeek网页版或者豆包、元宝这些云端服务里去?那简直是疯了。
因此,现实方案往往是部分高度敏感的工作流在本地用高性能卡(如RTX 5090 D)推理,部分非敏感任务与云服务厂商合作。对于个人用户,其实不需要5090 D这么顶级的配置,RTX 5060 Ti或5070级别的显卡已经能胜任很多本地任务。
市场也看到了这个需求。比如豆包PC版就和英伟达合作,推出了“本地知识问答”功能,专门解决隐私敏感的本地知识库需求。
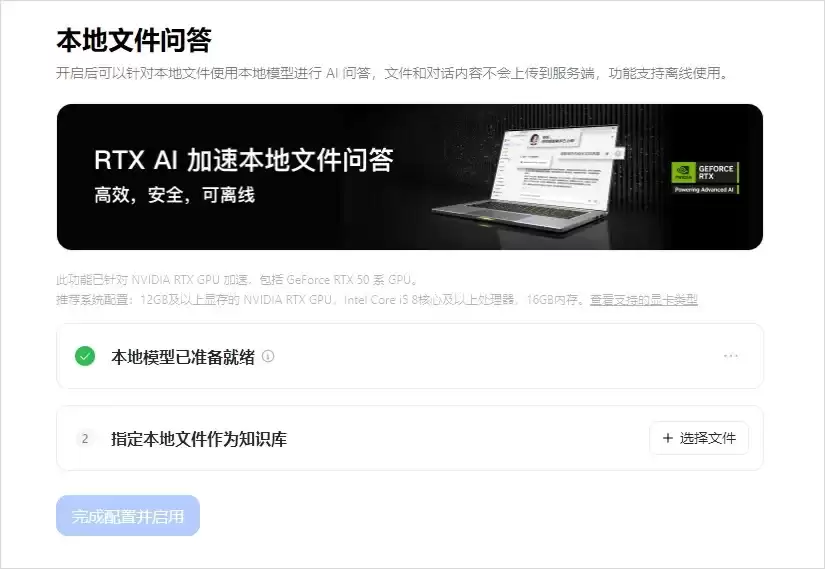
它本地部署的是一个7B模型,推荐使用12GB以上显存的显卡(也就是RTX 5060 Ti及以上级别)。有趣的是,这个7B模型本质上是智谱的GLM-4。当然,你也可以用Ollama等工具自己部署其他模型,只是过程稍麻烦些。
本地部署的利与弊
除了隐私,本地部署还有一个显著优势:一次部署,无限免费使用。用ComfyUI随便生成、反复尝试,没有延迟,无需排队,更重要的是,彻底告别了各种云端服务的“积分焦虑”。
但话又说回来,本地部署受限于硬件算力,往往跑不动参数量过大的模型。而更大的参数通常意味着更强的性能、更广的知识面和更稳定的输出。这是本地部署无法回避的短板。
云端与网页:另外两条高效路径
如果你的需求不涉及核心隐私,那么云端和网页方案往往更高效、更强大。
对于企业:如果需要为团队配置大模型,又希望数据可控,那么在云端(如火山引擎、阿里云等)私有化部署大型模型是更主流和专业的选择。例如部署一个Qwen2.5-72B模型,可能需要4张48GB显存的显卡,这对绝大多数个人用户来说都是不现实的投入,但对云服务商则是标准配置。
对于个人及灵活需求:如果只是偶尔用用,且不涉及敏感数据,那么租赁云服务器是性价比极高的方案。像AutoDL这类平台,可以按需租用带高性能显卡的实例,用完后释放,灵活又经济。
总结与设备选择建议
看到这里,关于“是否需要为AI购置一台本地设备”,你应该已经有了清晰的判断框架:
- 优先考虑网页/云端服务:如果你的任务不涉密,且追求最强大的模型能力(如GPT-4、Claude 3.5等),网页版或API调用是最佳选择。
- 认真考虑本地部署:如果你的工作流涉及敏感数据,或需要定制化、离线的稳定环境,且模型规模在14B(需高性能卡)或7B/8B(主流消费级卡可应对)量级以下,那么投资本地硬件是值得的。
- 折中考虑云端租赁:对于需要大算力但频次不高、或不想一次性投入高额硬件成本的实验性、临时性任务,租赁云服务器是最灵活的方案。
如果你已经明确,自己确实需要一台能够本地运行AI的电脑,并且打算在618期间入手,这里有几款我个人关注过、觉得综合表现不错的笔记本(非商业推广),供你参考:
- 高性能创作本/游戏本:重点关注搭载RTX 4060及以上、且显存为12GB或16GB的型号。这类产品能较好地平衡7B-14B量级模型的推理需求与便携性。
- 旗舰级移动工作站:如果预算充足,且对移动端的极致性能有要求,可以关注搭载RTX 4080/4090移动版显卡的顶级型号。它们能应对更复杂的本地AI任务。
(注:具体型号因市场变化快,此处不列举,建议根据“显卡型号+显存大小”为核心筛选条件,并结合散热、屏幕、续航等自身需求进行选择。)
至于台式机,自由度就高多了。显卡方面,RTX 5060 Ti、5070、5070 Ti都是性价比不错的起点。如果预算充足,直接上RTX 5080或5090 D,自然能获得更畅快的体验。
希望这篇文章,能帮你理清思路,做出最适合自己的选择。
相关攻略

零一万物与四川内江高新区达成超1 5亿元合作,共建人工智能产业基地。项目聚焦垂直领域大模型应用,构建区域性AI服务平台,推动产业智能化。依托当地芯片设计、智能终端等产业链基础,双方将协同打造城市级AI基础设施,促进人工智能与实体经济深度融合。

如何利用AI高效制作专业PPT:三大实用方法详解 在当今职场环境中,演示文稿的制作水平与工作效率已成为衡量专业能力的重要指标。然而,从内容构思、素材收集到视觉设计,传统PPT制作流程往往耗时费力。随着人工智能技术的成熟,AI工具为演示文稿创作带来了革命性改变——不仅能大幅节省制作时间,更能显著提升内

AI分镜脚本创作:碘伏传统的叙事方式 数字化浪潮席卷之下,影视制作的工具箱正在被人工智能(AI)重新定义。其中,AI分镜脚本创作正从一个前沿概念,迅速演变为一股不可忽视的行业趋势。它带来的不仅是效率的飞跃,更在悄然重塑着叙事本身的可能性。 要理解这场变革,得先从分镜脚本本身说起。这个环节,本质上是将

如何利用WPS AI提升PPT制作效率,轻松创建专业课程内容 在当今快节奏的内容创作环境中,高效产出高质量的演示文稿和课程材料,已成为教育工作者、培训师及职场人士的普遍需求。你是否也曾为制作一份PPT而投入大量精力,反复修改结构、搜寻素材,但最终成果仍不尽如人意?这种费时费力的传统方式,正随着智能化

AI排版工具如何提升工作效率?智能排版解决方案全解析 在当今内容驱动的数字时代,视觉呈现的质量直接影响信息传播效果。一份结构清晰、版式专业的文档或设计作品,能够迅速吸引读者注意,显著提升信息传递效率。本文将全面解析AI智能排版工具的核心优势与应用技巧,帮助您掌握如何借助人工智能技术,让排版工作变得高
热门专题







热门推荐

Mango Network (MGO):重塑Web3未来的高性能多虚拟机公链 在区块链技术飞速演进的今天,可扩展性、互操作性和开发者体验已成为下一代基础设施的核心战场。面对以太坊生态的拥堵与高昂费用,以及众多新兴链带来的流动性割裂,市场亟需一个能够无缝连接不同生态、兼具高性能与安全性的解决方案。正是

在远程办公与在线协作日益普及的今天,视频会议和语音通话中的背景噪音已成为影响沟通效率的常见难题。无论是居家办公时的家庭杂音、咖啡厅的环境嘈杂,还是突如其来的施工声响,这些干扰都会降低通话质量,分散与会者注意力。自2017年成立以来,有一家公司始终专注于利用人工智能技术解决这一痛点——它就是Krisp

产品介绍 在信息过载的时代,高效处理音频与视频内容已成为职场人士和内容创作者的普遍需求。听脑AI精准洞察这一痛点,它不仅是一款高精度的语音转文字工具,更是一个深度融合了大型语言模型(LLM)的智能分析平台。其核心价值在于:将冗长的会议录音、访谈视频、课程讲座等音视频资料,快速转化为结构化文本、专业会

在当今数字音乐创作领域,技术门槛正变得越来越低。即使你没有任何乐理基础,或者缺乏专业的录音设备,现在也能通过在线工具轻松实现音乐创作梦想。Boomy 正是这样一个专注于简化音乐制作流程的在线平台,它让普通人也能快速将灵感转化为完整的音乐作品。 Boomy 的核心设计理念非常清晰:它提供了一个丰富的预

在MEXC(抹茶)交易所进行USDT充值的完整指南 对于数字资产交易者而言,快速、安全地将资金划转至交易平台是第一步。本指南将详细介绍在MEXC平台进行USDT充值的具体流程与核心技巧,帮助您高效完成操作,规避常见风险。 一、充值前的准备工作 在开始操作前,有两项准备工作必不可少: 1 确保您已经