蚂蚁灵波开源视频动作模型 LingBot-VA 技术解析与应用
lingbot-VA 是什么
在机器人控制领域,如何让机器像人类一样,既能“规划”未来,又能“执行”当下,是一个核心挑战。近期,蚂蚁灵波科技开源了名为LingBot-VA的模型,它被公认为全球首个面向通用机器人控制的因果视频-动作世界模型。该模型的关键创新,在于将视频世界建模与策略学习统一到了一个自回归框架内。本质上,它赋予了机器人“边预测、边行动”的闭环智能控制能力。
这带来了什么改变?意味着机器人不仅能准确预测未来数秒的环境变化,还能同步生成并执行最优动作序列。其学习效率尤为突出:根据官方数据,模型仅需30到50次真实演示,即可学会一项新技能。在长序列复杂任务、数据高效后训练以及跨场景泛化性能上,其表现均显著超越了当前的主流基准模型。
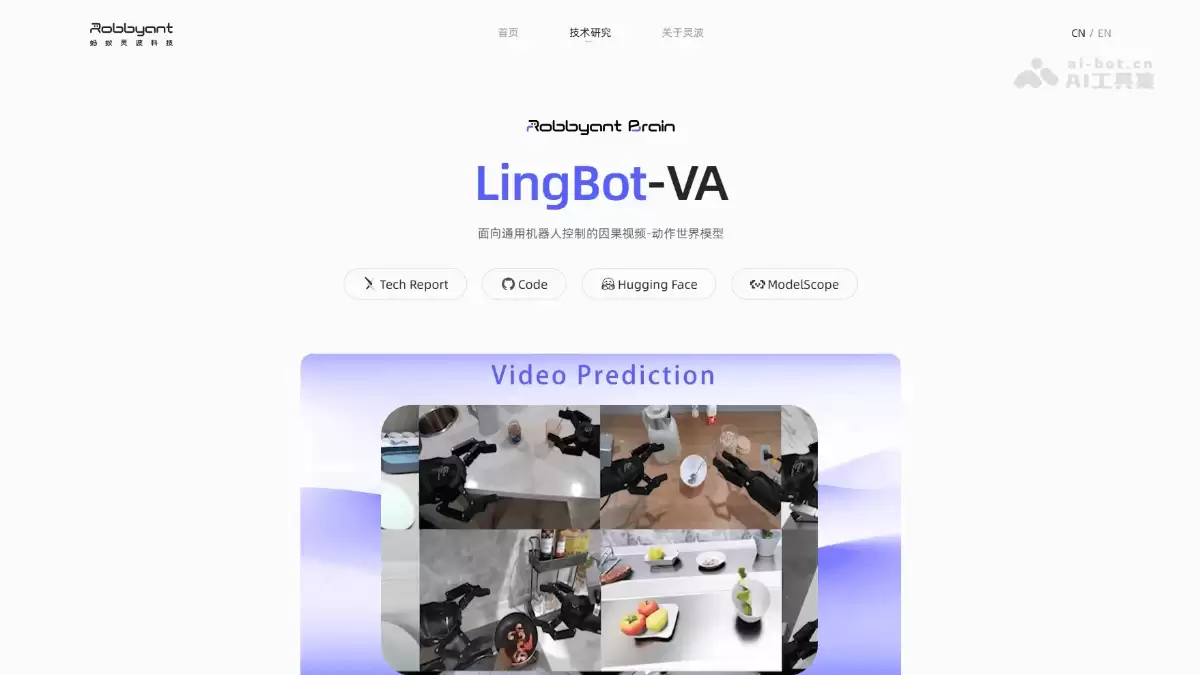
lingbot-VA 的主要功能
那么,LingBot-VA具体具备哪些核心能力?其功能优势主要体现在以下几个方面:
统一视频-动作建模:这是其技术基石。传统方案通常将环境预测与动作规划分离,而LingBot-VA创新性地将视觉动态预测与动作执行整合进单一模型。这种“所见即可控”的一体化设计,实现了感知与决策的深度闭环。
长程任务执行:机器人常因“遗忘”步骤而任务失败。LingBot-VA擅长处理如准备早餐、拆解包裹等需要多步骤协调与长期状态记忆的复杂任务。其强大的记忆与规划能力,能有效避免状态混淆,确保任务计划被连贯执行。
高效后训练:这是其商业化应用的关键优势。模型学习新技能的成本极低,仅需数十次真实演示。实验表明,在此少样本学习设定下,其任务成功率较部分基准模型(如π₀.₅)提升约20%,数据利用效率优势显著。
跨场景泛化:模型具备广泛的适应性。无论是插入试管、拾取螺丝等精密操作,还是折叠衣物等柔性物体处理,亦或是打开抽屉等铰接物体操控,它都能有效应对。这种强大的泛化能力,为其落地多样化的实际场景奠定了坚实基础。
lingbot-VA 的技术原理
支撑上述强大功能的,是一套精巧而创新的技术架构。理解其工作原理,便能洞悉其卓越性能的来源。
自回归扩散架构:模型采用了自回归扩散框架。它将视觉动态预测与动作推理统一编码至一个交错的序列中。您可以将其理解为一个持续滚动的思维链:在每一步,机器人同时推理未来的环境状态,并决策出当前的最优动作,从而实现视频生成与动作决策的深度融合。
三阶段处理框架:其工作流程清晰分为三个阶段。首先,自回归视频生成模块会基于当前观测(如摄像头画面)和语言指令,预测未来的画面序列。接着,逆向动力学模型充当“解码器”,从这些预测的未来视频中,反推出应执行的具体动作序列。最后,也是闭环形成的关键——执行动作后,系统会用真实的观测结果更新预测缓存,将模型的“想象”与现实世界锚定,从而构成一个完整的感知-决策-执行闭环。
逆向动力学模型:此模型是连接“预测”与“执行”的核心桥梁。其任务在于:给定一段预测的未来视频,精准解码出导致该状态变化所需的动作序列。实践证明,该模块在不同环境乃至不同机器人平台间,均展现出良好的泛化性能。
真实数据预训练:所有能力均建立在海量数据学习之上。模型在规模化的机器人视频-动作配对数据集上进行了预训练,从中学习了丰富的视觉动态模式与物理交互规律。这为其理解和预测物理世界的演变,提供了坚实的数据基础。
lingbot-VA 的项目地址
对于开发者与研究人员,项目的可及性至关重要。目前,LingBot-VA的所有核心资源均已开源:
- 项目官网:https://technology.robbyant.com/lingbot-va
- GitHub仓库:https://github.com/Robbyant/lingbot-va
- HuggingFace模型库:https://huggingface.co/collections/robbyant/lingbot-va
- 技术论文:https://github.com/Robbyant/lingbot-va/blob/main/LingBot_VA_paper.pdf
lingbot-VA 的应用场景
基于其技术特性,LingBot-VA拥有广阔的应用前景,覆盖从家庭服务到工业制造的多个高价值领域。
家庭长程任务:这是最直观的应用场景。让机器人执行准备早餐、整理房间、拆取快递包裹等多步骤复合型家务,这些任务耗时较长、逻辑复杂,正是LingBot-VA长程规划与记忆能力优势的体现。
高精度工业操作:在实验室或精密装配线上,诸如插入微型试管、拾取并放置细小螺丝等操作,要求亚毫米级的控制精度。模型对动作的精细预测与控制能力,使其能胜任此类高精度挑战。
柔性物体处理:处理衣物、线缆等可变形物体是机器人领域的传统难题。LingBot-VA在折叠衣物等任务上展现的性能,表明其能够理解材质特性并适应物体的动态形变。
铰接物体交互:日常生活中充满门、抽屉、橱柜等铰接物体。模型在打开抽屉等任务上的成功,证明了其能精准理解物体的机械约束与运动学关系,实现安全有效的物理交互。
少样本快速适应:在无法提供海量数据的特定场景下——例如定制化小批量生产线或特殊服务场景——模型仅需极少演示即可快速学习新技能的特点,将构成其独特的竞争优势。
总而言之,LingBot-VA的出现,不仅是一个先进模型的发布,更代表了一种将“世界模型”与“动作生成”深度融合的技术新范式。它让机器人在真正理解任务、并灵活适应复杂物理环境的道路上,迈出了关键一步。
相关攻略

RynnBrain是什么 在具身智能领域,如何让机器人真正理解并适应复杂的物理世界,始终是核心挑战。近期,阿里巴巴达摩院发布了一项重要成果——开源了名为RynnBrain的具身智能大脑基础模型。这一模型实现了关键突破,首次赋予机器人接近人类的时空记忆与物理空间推理能力。 具体而言,RynnBrain

SkyReels-V3是什么 视频创作的门槛,正在被一项新技术重新定义。最近,昆仑万维开源的SkyReels-V3,可以说在业内投下了一枚“重磅冲击波”。它不再是一个功能单一的玩具,而是一个用单一架构就能实现专业级视频创作的“多面手”。简单来说,它能让你手里的静态照片“活”起来,变成动态影像;还能智

ClawWork是什么 如果让AI去真实世界里“打工”,它能不能养活自己?香港大学数据科学实验室(HKUDS)开源的ClawWork项目,就是为了回答这个问题而生的。它本质上是一个AI Agent的“经济生存”基准测试框架,专门评估大模型在模拟真实商业环境中的“赚钱能力”。 这套系统的规则很现实:给

FireRed-Image-Edit是什么 在AI图像生成与编辑领域,开源模型正迅速崛起,其能力已能比肩甚至超越部分闭源方案。近期,由小红书Super Intelligence团队研发并开源的FireRed-Image-Edit模型,便是这一趋势下的杰出代表。这款基于先进扩散架构的通用图像编辑AI,

在人工智能模型普遍追求规模与通用性的当下,开发者们迫切需要一款能够真正“看懂”图像、“听懂”声音、“读懂”文字,并能自由进行跨模态内容创作的“全能型”AI工具。近期,蚂蚁集团重磅开源的全模态大语言模型Ming-flash-omni-2 0,正将这一愿景变为现实。它不仅彻底打通了图像、视频、音频与文本
热门专题







热门推荐

MiniCPM-o 4 5是什么 在探索更自然、更智能的人机交互道路上,我们始终在期待一个“全能型选手”的到来。如今,这个角色或许已经登场。面壁智能最新开源的MiniCPM-o 4 5,一个仅拥有90亿参数的全模态大模型,正致力于重新划定“智能对话”的边界。 它彻底颠覆了传统一问一答的“对讲机”式交

Binance币安 欧易OKX ️ Huobi火币️ 想在2025年安全获取欧易OKX的正版APP?其实秘诀就一个:认准官方网站,避开所有仿冒和可疑的下载渠道。要知道,欧易现已统一更名为欧易OKX,其核心业务始终围绕数字资产交易及相关服务展开。 确认官方网站地址 第一步,打开浏览器,手动输入欧易OK

SecondMe Book是什么 在AI社交这一前沿赛道,一款国产平台正带来独特的解决方案。SecondMe Book,本质上是一个能够让你构建个人AI数字分身的创新平台。它允许用户创建一个能够代表真实自我风格与思维的AI数字身份,并让这个“第二自我”在一个专属的AI社交网络中自主运行——包括主动发

在AI大模型技术快速发展的今天,如何在卓越性能与高效推理成本之间取得最佳平衡,已成为行业关注的核心焦点。近期,由阶跃星辰推出的开源模型Step 3 5 Flash引发了广泛热议。该模型专为智能体(AI Agent)应用场景深度优化,旨在顶尖能力与亲民部署成本之间,构建一个极具竞争力的技术支点。 简而

LongCat-Flash-Lite是什么 在探索大语言模型性能与效率的最佳平衡点时,美团近期推出的LongCat-Flash-Lite提供了一个极具创新性的解决方案。作为新一代高效大语言模型,它凭借其突破性的架构设计,在人工智能领域获得了广泛关注。 简而言之,该模型创新性地融合了“混合专家系统(M