数学界悬置数十年的群论经典难题——Kourovka Notebook 第21.10号问题,近期取得了实质性进展。推动这一突破的,是一种崭新的人机协作研究范式:牛津大学数学家 Marc Lackenby 在 Google DeepMind 最新发布的多智能体研究系统“AI Co-Mathematician”的协助下,成功定位了解决问题的核心思路与关键路径。
这标志着一个更深层次的趋势转变。以往,人工智能在数学研究中的应用多局限于“工具化”角色,例如执行特定推理步骤、辅助形式化证明或进行数值计算实验。但这些能力往往是割裂的,未能整合为一个能够理解完整研究流程、并能与人类进行长期深度协作的“伙伴”。AI Co-Mathematician 正是瞄准了这一空白。它不再局限于回答孤立问题,而是致力于构建一个能够持续跟进复杂研究项目的多智能体协作平台。在群论难题中,该系统并未直接给出最终证明,而是生成了一份存在缺口却极具启发性的证明草稿。正是这份草稿为 Lackenby 提供了关键的突破口,通过人机之间的多轮交互与迭代推进,最终引导研究走向成功解答。
性能数据有力地印证了这种协作模式的有效性。根据相关论文,AI Co-Mathematician 在当前公认难度最高的数学基准测试之一——FrontierMath 的 Tier 4 级别上,取得了 48% 的解题准确率,刷新了该基准的最高纪录(SOTA)。这表明,它的介入不仅革新了工作方式,更带来了可量化的能力提升。

AI Co-Mathematician:专为长期科研设计的智能工作台
那么,这一系统究竟如何运作?本质上,AI Co-Mathematician 是一个为数学研究量身定制的多智能体协同系统。
研究团队在论文中阐述,用户主要与顶层的“项目协调智能体”进行交互。该智能体的首要任务是澄清问题边界、明确研究目标,随后将宏观任务分解为多个子任务,分配给不同的专项工作流。这些工作流会进一步调用具备不同职能的子智能体,分别负责文献检索、代码实验、证明尝试、结果审查等环节。所有中间过程、思路与结果都会被记录并写入一个共享的文件系统。最终的交付物并非易于丢失上下文的长篇对话,而是一份持续更新、结构清晰的“动态研究文稿”,其中完整保留了边注、引用来源、内部链接以及全部的审查痕迹。
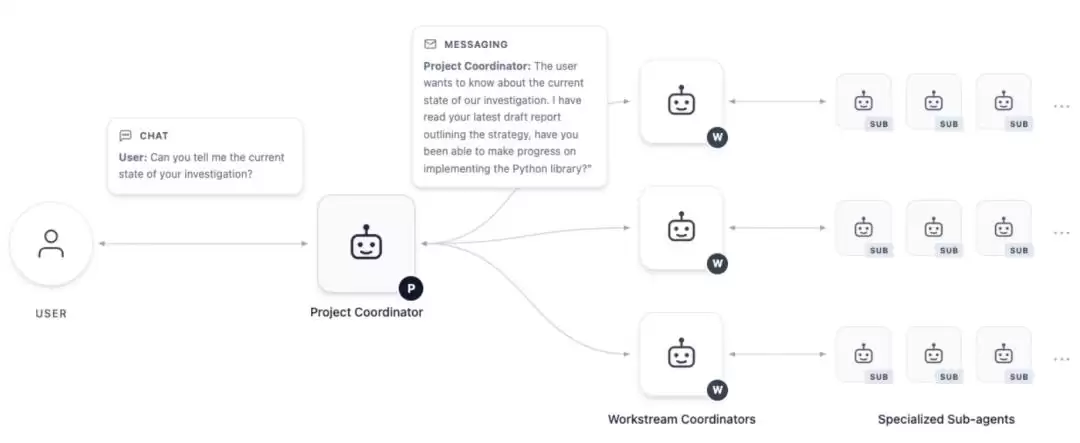
图|AI Co-Mathematician 工作空间中各类智能体组织结构的简化示意图。箭头表示标准的信息传递路径。
该机制的一个关键设计在于其对“失败”的处理方式。系统会持续记录所有被否定的假设、走不通的路径以及审查中暴露的漏洞,并将这些信息作为正式的“研究上下文”予以保存,而非简单丢弃。其背后的理念十分深刻:在数学探索中,明确“何种方法不可行”本身就是极具价值的知识。这些失败的尝试并非噪音,而是后续重新定位问题、调整策略乃至开辟新路径的重要依据。系统可以围绕同一目标并行推进多条研究路径,并根据进展动态调整资源分配;每条路径都会定期回传阶段报告。如果某条路径最终被判定为无法达成目标,系统会给出明确警示,而非用一份形式完整却逻辑断裂的文本来掩盖问题。

图|单个工作流由一系列动作构成,这些动作由工作流协调智能体执行。
此外,系统在“不确定性管理”上设置了严格的硬性约束:代码必须通过测试方可视为完成;报告必须通过审查才能最终定稿;如果某条研究路径长时间停滞不前,智能体必须主动将问题暴露给用户,而非持续生成形式完美但内容空洞的文本。
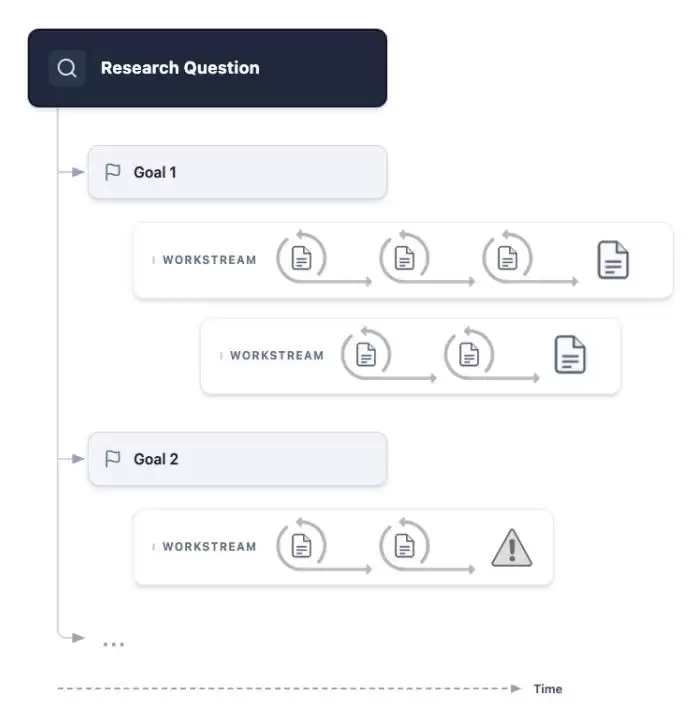
图|一旦研究问题和目标确定,项目协调者就会安排各个工作流以推动目标实现。
刷新高难度基准,投入真实数学研究
除了理念先进,AI Co-Mathematician 的实战能力同样经过了严格检验。在基准测试中,它在 FrontierMath Tier 4 层级的 50 道高难度题目中,成功解答了 23 道(去除2道公开样例题后),准确率达到 48%。
FrontierMath 基准由 Epoch AI 开发,其 Tier 4 层级收录的题目挑战性极高,部分问题甚至被预测在未来数十年内都难以被 AI 攻克,人类专家解答通常也需要数天时间。作为对比,其基座模型 Gemini 3.1 Pro 在同一测试中的准确率仅为 19%。更值得注意的是,在这 23 道被解答的题目中,有 3 道是此前所有已评测系统均未能成功解决的。
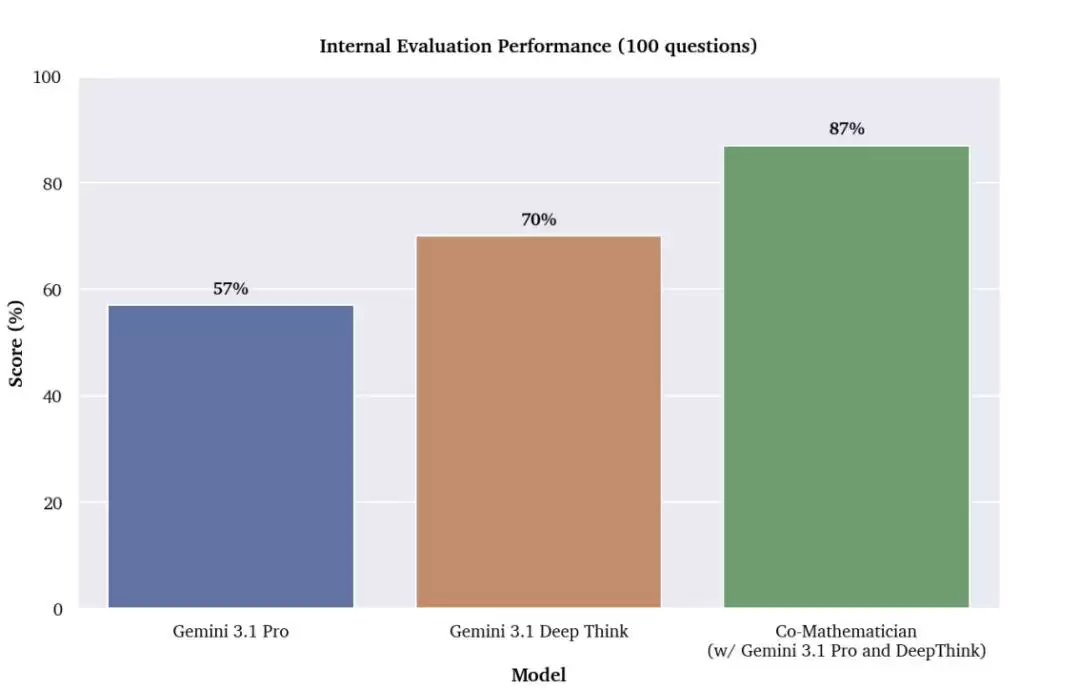
图|Gemini 3.1 Pro、Gemini 3.1 Deep Think 与 AI Co-Mathematician 在一项内部研究级数学基准测试上的准确率对比。
更令人信服的是其在真实研究场景中的应用成果。研究团队特别强调,以下案例均由数学家独立使用该系统完成,未经过 DeepMind 研究人员的中间干预:
除了开篇提及的 Marc Lackenby 在群论问题上的突破,数学家 Semon Rezchikov 在哈密顿系统相关子问题上,获得了一条包含关键引理的证明路线;数学家 Gergely Bérczi 则得到了关于 Stirling 系数问题的证明尝试与计算证据。当然,这些成果也清晰地揭示了当前系统的定位:在 Bérczi 的研究中,相关证明仍被标注为“处于详细人工审查中”;Rezchikov 的体验也更多是基于个案的成功。这清楚地表明,这种“人在回路中”的协作模式已展现出切实的科研价值,但尚不能直接推论出智能体已经能够稳定、独立地完成开放式的数学研究项目。
当前局限与未来发展方向
研究团队对当前系统的不足之处保持着清醒的认识。他们指出了几个关键挑战:
首先,多轮评审机制并不总能导向更可靠的结果。有时,一个存在根本缺陷的论证,可能在反复修改和包装后,看起来越来越“像”通过了审查,但其核心逻辑漏洞并未被真正消除。其次,不同智能体之间也可能陷入无法达成共识的僵局,导致系统在无休止的修改-驳回循环中空转,推理质量不升反降。
此外,该系统目前尚无法脱离人类的持续介入,独立完成长周期、高不确定性的前沿研究任务。长时间自治要求用户让渡一部分控制权,而当前模型在遇到意外困难时,关于“何时应该停止尝试、何时必须求助人类”的决策判断力,仍远不及人类研究者。另一个有趣的观察是,系统生成的排版精良的 LaTeX 文稿,很容易给人一种“内容必然严谨”的心理暗示,这反而可能掩盖逻辑上的细微疏漏。
面向未来,研究团队的展望显得务实而克制。他们认为,下一步的重点或许不应单纯追求生成更“正确”答案的能力,而是需要发展一套新的评估框架,用以科学衡量人机协作的实际效能、智能体在有状态探索中的综合能力,以及对研究不确定性的严格管理水平。与此同时,如何管理自动化输出可能带来的“语义噪声”、减轻而非加重同行评审的负担,并确保人类研究者始终保有对论文创新性与学术价值的最终判断权,将是所有相关领域研究者必须共同面对的核心议题。
归根结底,AI Co-Mathematician 或许并非正在成长为一位能独立攻克世界难题的“数学家”,而是清晰地预示了另一种可能:在那漫长、曲折且必然充满试错的科研道路上,人工智能可以成为一个人类能够持续对话、共同思考的深度协作对象。这不仅是研究工具的升级,更是科学研究范式的一次深刻演进。




