在分布式数据架构中,数据一致性是一个经典且棘手的问题。它往往不是由单一组件故障引起的,而是多个中间件在设计理念和协作边界上相互碰撞的结果。今天要探讨的这个案例,正是源于一个真实的线上场景:当Flink、StarRocks与Seata在毫秒级事务中相遇时,一个隐蔽的数据不一致问题是如何暴露、分析与解决的。

一、业务背景说明
事情源于一项新上线的业务。为了进行聚合报表分析,团队通过Flink将MySQL的数据实时同步至StarRocks。为了保证核心业务的可靠性,团队建立了一套“比数”监控体系,专门用来监听异构数据库间的数据量一致性,以此作为Flink处理是否准确的“晴雨表”。
这套体系平稳运行了一段时间,直到某天,监控平台开始频繁告警,同时业务侧也反馈报表中间出现了大量异常数据。
初步排查很快排除了数据链路本身的可靠性问题:Kafka中的消息完整,Flink消费也正常。那么,问题大概率就出在业务逻辑的处理环节了。
二、问题排查与修复方案
1. 问题定位与根因分析
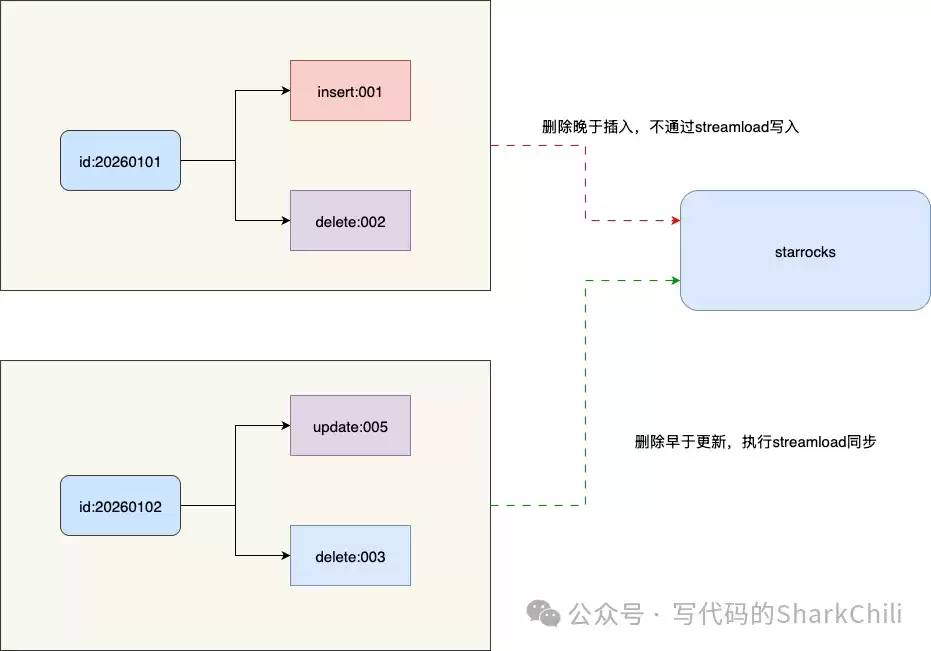
通过数据库离线比对,我们锁定了几条“多出来”的问题数据。接着,利用Kafka消息回放进行追踪,发现一个关键现象:这几条数据在源端(MySQL)都是在毫秒级时间内,先后完成了插入(INSERT)和立即删除(DELETE)操作。
结合Flink Job的数据流算子代码,问题的轮廓逐渐清晰。这里需要理解StarRocks在当时业务场景下的一个设计特点:对于非主键表,其Stream Load接口仅支持批量数据的Upsert(插入/更新)操作,而删除操作必须通过JDBC接口单独执行。因此,Flink算子在攒批同步时,实际上分成了两个动作:先执行JDBC批量删除,再执行Stream Load批量保存。
改造前的核心同步逻辑如下:
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
doExecuteData();
}
public void doExecuteData() throws SQLException, InterruptedException {
//jdbc删除
executeBatchDelete();
//stream load保存
executeBatch();
}正是这个“先删后插”的顺序,埋下了隐患。当MySQL端一个“插入后立刻删除”的事务,被Flink攒批后回放时,删除操作(executeBatchDelete)会先于插入操作(executeBatch)生效。结果就是,StarRocks端插入了一条源端早已删除的数据,导致两边数据不一致。

那么,为什么之前没有暴露这个问题呢?与相关数据流负责人沟通后,我们得到了全貌。原来,近期该业务上线了一个新功能,为了保证全局数据一致性,这条数据流被纳入了Seata AT模式的管控之下。在一次业务异常触发全局事务回滚时,Seata在二阶段根据Undo Log执行了反向补偿删除。这就导致同一条数据在极短时间内出现了“业务插入”和“补偿删除”两个动作。这种瞬时完成的“插删”模式,恰好击中了原有同步逻辑的弱点。
存量业务之所以安全,是因为其删除操作大多不是瞬时的,要么是插入后隔一段时间再删除,要么是通过标记位进行逻辑删除,从而避开了这个时序陷阱。
2. 快照合并方案的设计
根因明确了,解决方案的思路也就清晰了:核心目标是在同步窗口内,识别并过滤掉那些“插入后立即被删除”的数据。本质上,这是一个在内存中进行快照合并的过程。
具体思路分为三步:
- 缓存记录:在批攒期间,维护一个内存缓存。以数据ID为Key,Value是一个列表,用于记录这条数据所有的事件类型(INSERT/UPDATE/DELETE)及其对应的消息位点(Position)。位点值越大,代表该事件在事务序列中提交得越晚。
- 冲突检测:在真正执行同步前,遍历缓存。对于每个Key,如果其事件数量大于1,则说明在窗口期内对该数据有多次操作。
- 逻辑过滤:判断这些操作中,是否存在DELETE事件的位点晚于INSERT事件。如果存在,则意味着这条数据在本次窗口内被“插入后又删除”了,应该将其从待同步的数据集中移除。
3. 方案落地与验证
最终的改造方案,是在同步触发前(snapshotState方法中),增加一层快照合并的逻辑。其核心是比对删除集与插入/更新集中相同Key的位点关系,并将那些“后发生的删除”所对应的数据全部过滤掉。
关键实现代码如下:
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
/**
* 快照合并逻辑:
* 1. 遍历删除操作的快照集
* 2. 检查插入或更新操作集中是否存在相同Key
* 3. 如果存在,且删除操作的偏移量(位点)大于插入或更新操作
* 4. 则从所有待同步集合(删除、插入、更新)中移除该Key
*/
deleteOffsetMap.entrySet().stream()
.filter(e -> (insertOffsetMap.containsKey(e.getKey()) &&
e.getValue() > insertOffsetMap.get(e.getKey())) ||
(updateOffsetMap.containsKey(e.getKey()) &&
e.getValue() > updateOffsetMap.get(e.getKey())))
.map(Map.Entry::getKey)
.collect(Collectors.toSet())
.forEach(k -> {
deleteOffsetMap.remove(k);
updateOffsetMap.remove(k);
insertOffsetMap.remove(k);
});
doExecuteData();
}代码改造完成后,在测试环境进行了全面验收。我们特别关注了两个指标:
内存与GC影响:由于新增了内存级的批攒缓存,我们详细监控了堆内存使用和GC情况。所幸,目标业务表的数据量每分钟并不大,同步阈值也是动态调整的(通常不超过1万条),因此并未引起堆内存的异常飙升或频繁GC。
同步延迟:生产环境的观测数据显示,新增的过滤逻辑耗时几乎可以忽略不计。因为所有操作都在内存中完成,且数据集采用了高效的哈希结构进行存储和查找。更进一步说,由于过滤掉了一批无效的同步操作,反而减少了不必要的JDBC和Stream Load开销,整体同步效率甚至有所提升。
在确保业务一致性和性能压测都通过后,我们采取了稳妥的上线策略:先在从库运行观察一个月(期间主库通过离线订正保证数据正确),确认无误后,再升级主库并完成最终的业务验收,问题得以彻底解决。
三、常见问题
1. Flink Checkpoint 机制
Checkpoint是Flink实现容错和精确一次语义的基石。它会定期为所有算子状态创建全局一致的快照,并持久化到外部存储(如HDFS、S3)。其核心依赖于Chandy-Lamport分布式快照算法,通过在数据流中注入屏障(Barrier)来划分快照边界。当算子收到所有上游的Barrier后,会触发自身状态的快照。当所有Sink算子都完成快照,一次完整的Checkpoint才算成功。
Source → Operator1 → Operator2 → Sink
↓ ↓ ↓ ↓
状态 1 状态 2 状态 3 状态 4
└────────┴───────────┴─────────┘
↓
Checkpoint 快照
↓
持久化存储 (HDFS/S3)2. At-Least-Once 与 Exactly-Once 语义
At-least-once(至少一次):保证数据不会丢失,但可能被重复处理。在任务故障恢复时,它从上一个Checkpoint恢复状态并重放数据,这可能导致某些数据被处理多次。例如,一个计数任务在成功更新计数后故障,恢复后重放数据,会导致计数被重复累加。
时间线示例:
T1: 收到订单A,计数从0→1 ✓
T2: 更新成功后任务故障 ✗
T3: 任务恢复,从Checkpoint重放
T4: 重新处理订单A,计数从1→2(重复累加!)
最终结果可能错误。Exactly-once(精确一次):保证数据既不会丢失,也不会被重复处理。这通常需要Checkpoint机制与两阶段提交(2PC)协议配合。在故障恢复时,不仅能恢复状态,还能通过事务机制确保外部系统(如数据库)中的数据只被提交一次,从而得到精确的结果。
使用 checkpoint + 两阶段提交(2PC):
T1: Checkpoint开始,注入Barrier
T2: 收到订单A,预处理(未提交)
T3: 所有算子对齐Barrier,准备提交
T4: 两阶段提交确认,正式写入外部系统
T5: Checkpoint完成
故障恢复时,能跳过已提交的事务,确保数据精确处理一次。3. Flink GC 调优实践
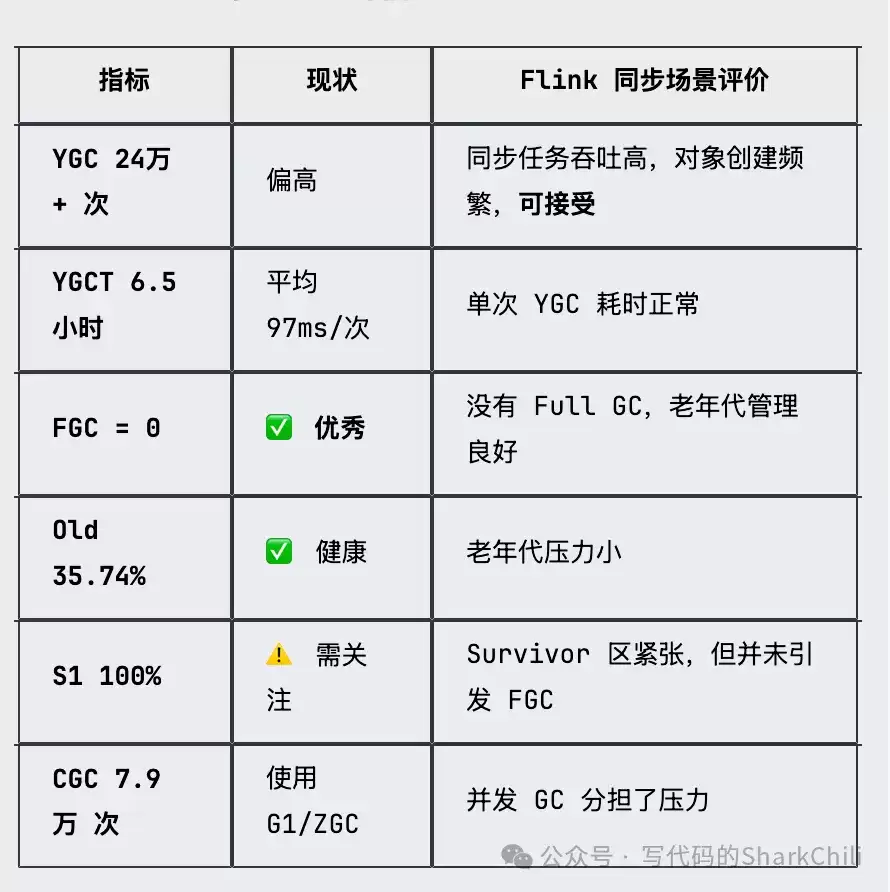
性能调优离不开对JVM GC日志的分析。以下是一份典型的GC日志摘要:
S0 S1 E O M CCS YGC YGCT FGC FGCT CGC CGCT GCT
0.00 100.00 71.28 35.74 85.20 75.08 243030 23660.875 0 0.000 79150 1719.807 25380.682从日志可以看出:FGC(Full GC)次数为0,说明没有发生Stop-The-World的完全垃圾回收,这是好事。老年代使用率(O)为35.74%,元空间使用率(M)为85.20%,都在可控范围内。
但Young GC次数较多(24万+次),虽然总耗时(YGCT)平均到每次只有约0.097毫秒,属于正常,但Survivor 1区(S1)使用率达到100%,这暗示着Survivor区空间可能偏小,导致部分本应在年轻代消化的对象过早晋升到了老年代。
针对这种情况,常见的优化方向是调整年轻代与老年代的比例(-XX:NewRatio),并增大Survivor区的容量(-XX:SurvivorRatio),让对象在年轻代经历更充分的GC,减少不必要的晋升,从而降低Full GC的风险。
四、小结
回顾这个案例,它涉及从监控告警、链路追踪、根因分析到方案设计、验证上线的完整闭环。处理这类跨组件的复杂问题,一个清晰的排查思路至关重要:
- 先定边界:从组件可靠性入手,排除底层基础设施的严重缺陷,明确问题域。
- 深入业务:聚焦业务逻辑与代码实现,通过数据比对和场景复现,定位问题根因。
- 协调闭环:联合相关方,厘清全链路上下文,确保对问题的理解没有盲区。
- 设计落地:基于根因设计解决方案,并在测试环境完成逻辑与性能的完整覆盖验证。
- 稳步上线:采用灰度、观察等策略,平稳推进方案落地,最终解决问题。
技术细节固然重要,但在分布式架构中,这种跨组件、跨领域的系统性思考和决策能力,往往才是解决复杂问题的关键。希望这个案例的分析思路,能为大家在应对类似架构挑战时提供一些参考。




