Gemini Omni实测:一句话生成视频,草图秒变电影大片

过去,AI视频生成的核心是“创造内容”。而谷歌最新发布的Gemini Omni,则将这一概念直接升级为“创造世界”。它不仅理解动能、重力与因果关系,还能将复杂概念瞬间可视化。人类距离“言出法随”的终极梦想,似乎又近了一大步。
在深夜的Google I/O大会上,酝酿已久的Gemini Omni终于登场,堪称视频生成领域的“Banana时刻”。
谷歌DeepMind宣称,Gemini Omni结合了Gemini系列强大的推理与生成能力,实现了对世界的深度理解、多模态交互以及视频编辑能力的重大飞跃。

这被视为谷歌迈向“万能生成模型”的关键第一步。其核心特点包括:
• 作为全新的世界模型,旨在模拟现实。
• 能够生成逼真的视频、图像和交互式模拟。
• 展现出对物理规律(如动能、重力)的直观理解。
• 可将抽象概念转化为生动的可视化讲解。
• 支持对话式的自然语言视频编辑。

业界普遍认为,Gemini Omni就是视频领域的“Nano Banana”,它的出现可能将重新定义内容创作的门槛。
一个“动动嘴就能剪视频”的时代或许正在开启,传统的“眼见为实”观念将面临挑战。

AI改变世界,动动嘴剪视频
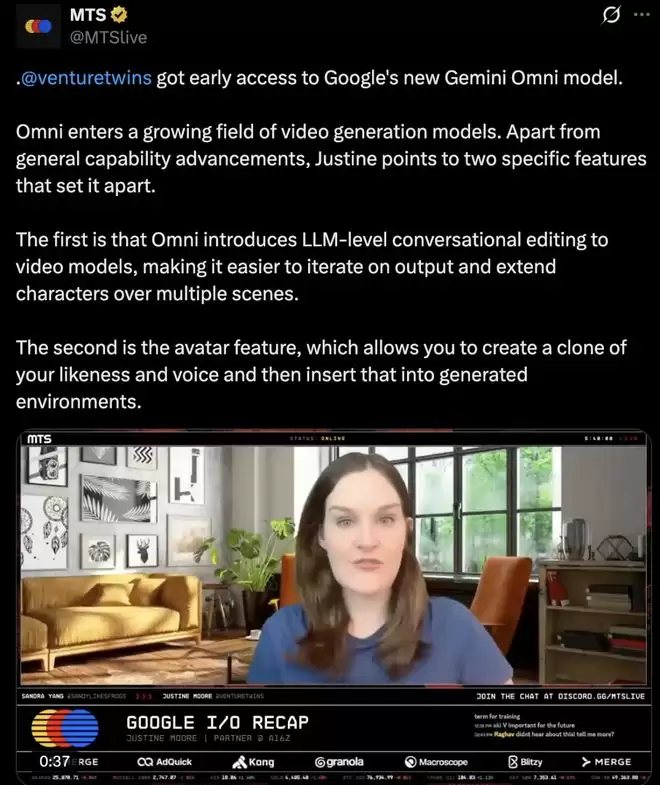
除了整体能力的跃升,硅谷风投a16z的合伙人Justine Moore指出了Gemini Omni两个尤为突出的特点:
第一,它将大语言模型级别的对话式交互能力引入了视频编辑,使得迭代修改生成结果、在多个场景中延展角色变得异常简单。
第二,其数字分身功能允许用户创建自己形象和声音的克隆,并直接植入生成的场景之中。
Gemini Omni真正实现了通过自然语言指令编辑视频。其轻量版本Gemini Omni Flash甚至能在编辑时保留视频原有的动作和连贯性,即便切换场景也游刃有余,展现出对输入视频的深刻理解。

更关键的是,Omni融合了更强的物理世界理解与Gemini模型的历史、生物、文化知识,实现了从“画得像”到“讲好故事”的跨越。它在处理人体特写、解释生物学概念方面表现卓越。
例如,Gemini Omni Flash能够展示蒙娜丽莎画像从宏观颜料到微观分子、原子的逐级缩放过程,文字渲染也极其精准。这已远远超越了简单的“内容生成”,迈入了“世界模拟”的范畴。
为什么是Omni,而非Veo 4?
回顾过去三年,谷歌的AI模型命名遵循着清晰的规律:Gemini 1.5、2.0、2.5;Veo 1、2、3;Nano Banana及其迭代版本。这种“数字+小数点”的工整模式,是典型工程师文化的体现,意味着技术路径是连续、可预期的。
然而,Gemini Omni彻底打破了这套体系。它是一个全新的词汇,不属于任何现有产品线。这本身就是一个强烈的信号。
在后续的发布访谈中,Google DeepMind的几位负责人与主持人探讨了Omni相比Veo的跨越式升级、多模态参考如何实现无缝编辑,以及谷歌在生成视频安全与透明方面的实践。

当被问及与Veo的区别时,产品负责人Nicole Brichtova的回答几乎不像一位产品经理:“这不是Veo的升级。我们必须从地基开始重新思考如何构建这个模型。”
她反复使用了一个词:step change(阶跃变化)。在45分钟的访谈里,这个词出现了五次。言下之意很明确:这不是一个新版本,而是一个新物种。
当一家以工程师文化为主导的公司,愿意打破沿用三年的命名体系来为一个产品命名时,这无异于一份公开的战略宣言。

Veo的训练目标是经典的“文本到视频”(text-to-video)。当团队后来希望它加入图像参考(例如根据照片生成视频)时,做法是在已训练好的模型上“叠加”一层条件输入。正如Nicole强调的,这是“layered into”(叠加进去)。Veo的许多能力是事后打上的补丁,而非与生俱来的骨架。
Omni则从第一天起就设定了截然不同的训练目标:“多模态进,多模态出”。图像、音频、视频、文本,这些并非训练时的“额外条件”,而是模型学习“世界是什么”的原始数据。谷歌联合创始人Demis Hassabis在现场也坦言:“我们必须重新思考训练目标本身。”
重做基础模型的代价是巨大的。联合负责人Dumitru Erhan透露,在评估阶段,他们需要同时运行视频生成、编辑、图像生成、文本对齐、音频同步等五条评估管线。

这些管线之间存在权衡:优化其中一条,可能导致另一条性能倒退。“判断在哪里取舍,需要极深的直觉。”Dumitru如是说。
但巨大的代价换来了更惊人的回报:涌现(Emergence)。
研究总监Shlomi Fruchter分享了两个连团队都未曾预料的故事。

视频的Nano Banana时刻
Omni真正惊人的能力,或许不在于从零生成,而在于编辑。访谈中有一句反直觉却信息量十足的话,来自Shlomi:
“我们发现,把不同模态放在一起训练,反而让每个模态都变得更好。”
举例来说,如果让模型学会“在视频里生成合适的音乐”,它必须先掌握“生成音乐”本身的能力——而这个能力,反过来会让它生成的视频在节奏和情感上更加连贯。
这句话值得反复品味。它揭示了一个核心逻辑:模态之间并非简单的叠加关系,而是互相滋养、协同进化的关系。
学会绘画的过程,能让模型更懂物理(因为绘画涉及光影和透视)。学会生成音乐的过程,能让模型更理解时间结构(因为音乐是结构化的时间序列)。学会编辑视频的过程,则能让模型更深刻地把握因果关系(因为编辑必须知道“改动此处会如何影响彼处”)。

这与过去十年AI行业主流的、相对割裂的单模态优化路径形成了鲜明对比。为了实现这种多模态共生,谷歌必须解决一个此前所有视频模型都未能妥善解决的问题:如何让模型同时理解图像、音频、视频、文本四种参考指令,并在编辑时精准改动目标,而不“把孩子和洗澡水一起倒掉”。
答案就是:让它们从一开始就一起学习。这也正是Demis Hassabis称Omni是“走向AGI的一步”的原因。并非因为它能拍电影,而是因为只有真正理解世界运作规律的模型,才能可信地编辑和模拟这个世界。
他们“要把猛虎关进笼子”
让Omni显得更加耐人寻味的是,谷歌在发布强大能力的同时,主动为它套上了几道“笼子”。
第一道笼子:A vatar Flow。用户若想将自己的形象植入Omni生成的视频,不能随意上传一张自拍照。必须一次性完成多角度面部采集和特定文本的录音,生成一个唯一的“数字分身”(A vatar)。此后所有涉及用户面容的生成,都必须调用这个A vatar,无法随意更换图像源。Nicole对此直言不讳:“你可能会觉得我们封锁了很多东西。”这是一种明知会增添用户麻烦,却依然坚持的审慎态度。
第二道笼子:强制水印。所有由Omni生成的视频,都会嵌入两层标识:谷歌自家的SynthID不可见水印,以及跨平台的C2PA元数据标准。即使视频被剪辑、搬运或压缩,水印依然可被追踪。用户可以将任何视频上传至Gemini应用,直接询问“这是AI生成的吗?”,系统便能进行查验。
通过Gemini Omni,谷歌不仅发布了一款产品,更向市场宣告:下一轮AI竞赛的焦点,将不再局限于聊天或搜索,而在于谁能生成、编辑并模拟整个物理世界。旧有的行业秩序,已然开始松动。
相关攻略

今天凌晨的谷歌I O开发者大会,带来了令人振奋的重磅发布。谷歌正式推出了名为Gemini Spark的个人AI智能体,这不仅仅是一个简单的聊天机器人,更是一个能够同时处理多项任务的智能副手,真正实现了“一句话让AI干几份活”的高效体验。 Gemini Spark的核心设计理念是极致的用户导向:一切听

谷歌与三星合作推出两款智能眼镜,整合GeminiAI,支持语音导航与实时翻译。眼镜设计分为时尚与经典两种风格,旨在提供免手持的信息服务,如路线指引、附近推荐与通知整理。产品预计秋季上市,具体售价待公布。

谷歌与三星在I O大会上展示了两款智能眼镜原型,由GentleMonster和WarbyParker分别设计。眼镜整合GeminiAI,作为手机伴侣提供免手持交互,支持语音导航、个性化推荐、订单下达及通知摘要。其实时翻译功能可处理对话与视觉文字,并贴近原声音质。两款设计风格各异,瞄准不同用户。价格未定,传闻约379至499美元,预计秋季上市。

谷歌于5月20日正式发布Gemini3 5Flash模型,定位为当前最快、最高效的模型,旨在满足需要即时响应的现实场景。该轻量级模型致力于帮助用户处理日常事务与多步骤创意项目,应对各种复杂性并快速将想法转化为行动。

谷歌发布Gemini3 5Flash模型,强调其是目前最快、最高效的AI模型,旨在应对现实场景中需要快速响应和多步骤处理的复杂任务。该模型注重轻量化与高性能的平衡,针对实时对话、内容摘要等高频率需求优化,以提升用户体验并控制成本。此举加剧了中端AI市场的竞争,推动AI工具向更高效、更易用的方向发展。
热门专题







热门推荐

灵兽品阶决定成长上限,需按职业选择走兽、飞禽或鳞甲类。养成应与角色境界同步,集中资源优先培养主力至高星。技能分先天与后天,后天技能可动态调整应对战局。属性差异有限,后期培养深度更为关键。新手建议从中品起步,非重氪玩家以上品灵兽作为中期主力性价比更高。长期养成需分。

马斯克起诉OpenAI违背非营利使命一案因超过诉讼时效被法院驳回。马斯克原承诺出资10亿美元实际仅投入3800万美元,后因控制权之争离开。此后OpenAI转型营利并估值飙升,本案虽凸显非营利初心与资本扩张的冲突,但法庭未就实质问题作出裁决。

《天下归心》新版本“风起官渡”开启预约。鲁肃、孟获两位新名将登场,其技能将改变阵容搭配逻辑。跨服官渡之战复刻历史多阶段阵营对抗,重现史诗战场。新增藏品阁系统,陈列藏品可提升全队战力。士兵系统革新,装配军旗与令箭可释放觉醒技能,深化战术策略。预约即可领取专属礼包。

长城汽车创始人魏建军以“怕”为引,强调敬畏造车规律、珍视用户信任。面对行业内卷与营销泡沫,长城坚持长期主义,投入巨资研发并延长验证周期,以归元平台及魏牌V9X展现技术实力与品质承诺。通过将个人声誉与品牌绑定,长城构建以信任为核心的持久竞争力,其探索对行业良性发展具有重。

深蓝S05轴距达2880毫米,搭载AI大模型与L2+级智驾,注重科技体验与纯电性能。皓瀚DH-i轴距2775毫米,配备L2级辅助驾驶与实用智能座舱,强调经济可靠与混动平衡。两者分别吸引追求前沿科技的年轻群体和重视实用性的家庭用户,体现了新能源市场技术路线多元化并存的趋势。