Kimi突破性进展:跨数据中心大模型推理,重塑长文本处理新范式
在长上下文处理技术领域持续引领创新的Kimi,近日于系统架构层面再次实现重要突破。研究团队聚焦于大模型推理服务中长期存在的核心挑战——跨机房资源调度效率问题,提出了一套开创性的解决方案。
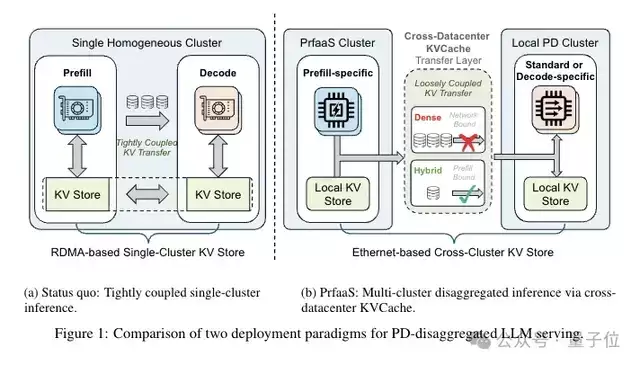
该方案被定义为Prefill-as-a-Service(预填充即服务,简称PrFaaS)。其关键性创新在于,首次实现了KV Cache(键值缓存)在跨数据中心环境下的可靠传输,从而将大模型推理流程中的Prefill(预填充)与Decode(解码)两个计算阶段,在硬件层面进行彻底解耦,允许它们部署于不同地域、不同架构的计算集群之上。
这一突破意味着什么?简而言之,Prefill与Decode任务从此能够实现“地理分离式”协同工作。该架构尤其适用于处理海量长文本场景,上下文长度越大,其展现出的性能增益与成本优化效益就越显著,堪称专为长上下文应用而生的系统级解决方案。
此项由月之暗面联合清华大学郑纬民院士、武永卫教授团队共同完成的研究,通过了严谨的内部生产环境验证。基于1T参数规模的混合注意力模型进行实测,PrFaaS-PD架构取得了卓越的性能数据:与传统同构部署方案相比,系统整体吞吐量提升了54%,P90延迟显著降低了64%;即便相较于未进行智能调度的基础异构方案,吞吐量仍能实现32%的有效提升。
更为重要的是,跨数据中心传输KV Cache所需的峰值网络带宽仅为13Gbps,远低于当前100Gbps商用以太网的普遍上限。这有力证明了,利用标准的商用网络即可稳定支撑此类跨域调度架构,极大地降低了工程化落地与大规模部署的技术门槛。
为何需要突破数据中心边界?
将Prefill与Decode阶段进行分离部署,现已成为优化大模型推理服务的行业共识与标准实践。然而,这种分离也引入了一项关键约束:KV Cache的高效传输严重依赖于高带宽、低延迟的RDMA网络,这导致两个阶段被强制绑定在同一个RDMA网络域内,无法实现真正意义上的物理分离与资源独立。
由此产生了一个现实的资源配置矛盾:最适合执行计算密集型Prefill任务的高性能算力芯片(如H200),与最优处理带宽密集型Decode任务的芯片(如H20),往往分布于不同的数据中心或可用区。若强行将它们部署于同一机房,将导致硬件资源配置僵化,难以灵活应对动态业务负载。
在线服务流量存在天然的波动性。固定的硬件配比极易引发资源利用率失衡——部分计算单元排队等待,而另一些则处于空闲状态,最终导致整体算力利用率低下,成本效益受损。
造成这一困境的根本原因在于KV Cache面临的“带宽墙”。研究团队提供了量化分析:以MiniMax-M2.5这类典型的密集GQA架构模型为例,在处理32K长度上下文时,单个推理实例生成KV Cache的速率高达60Gbps。而跨数据中心以太网的典型带宽仅在10-100Gbps范围,试图用常规网络承载如此高的数据流,无异于杯水车薪,难以维系。
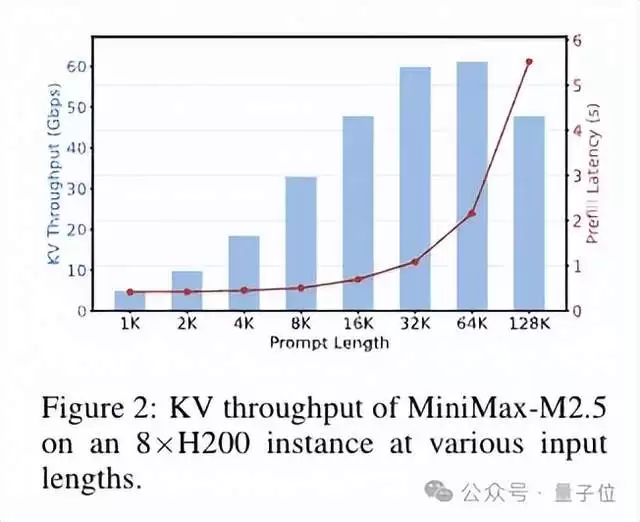
因此,为确保推理流程流畅、避免引入额外延迟,传统的PD分离架构只能依赖RDMA网络进行高速通信。这也构成了其无法突破单一数据中心部署模式的核心技术瓶颈。
转机源于新一代混合注意力架构的兴起。近期,包括Kimi Linear、Qwen 3.5、MiMo-V2-Flash、Ring-2.5在内的众多先进模型,均采用了“线性注意力+全注意力”的混合设计范式。在此架构下,线性注意力层仅生成固定大小的循环状态,其大小不随上下文长度增长而膨胀;仅有全注意力层会产生与长度成正比的KV Cache。
效果是显著的。在32K上下文长度下进行对比:
- MiMo-V2-Flash模型的KV吞吐量降至4.66Gbps,较MiniMax-M2.5降低了13倍;
- Qwen3.5-397B模型的KV吞吐量为8.25Gbps,相比同等规模密集模型的33.35Gbps,降低了4倍;
- Ring-2.5-1T模型通过MLA压缩技术与7:1的混合比例,整体KV内存节省了约36倍。
可以说,“线性注意力+全注意力”混合架构成功地将KV Cache的传输需求,从必须依赖RDMA的高带宽级别,降低至普通以太网即可满足的水平。实现跨数据中心的PD分离,已从理论构想转变为具备工程可行性的技术路径。
破局之道:深度解析PrFaaS系统架构
当然,仅有模型架构的创新是远远不够的。要将“技术可行”转化为“生产可用”,需要一套精密、鲁棒的系统设计。这正是清华大学与月之暗面团队提出PrFaaS架构的核心理念。
PrFaaS的核心设计思想直观而高效:将长上下文请求的Prefill计算任务,智能地卸载至由算力密集型芯片(如H200)构成的独立专用集群完成。随后,将生成的KV Cache通过标准以太网传输回离用户更近的本地PD集群,进行后续的Decode生成。此举使得两个阶段能够根据各自的计算特性,灵活选用最具性价比的硬件资源。
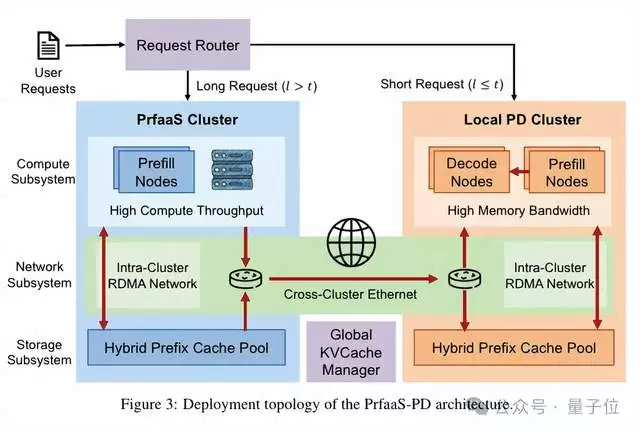
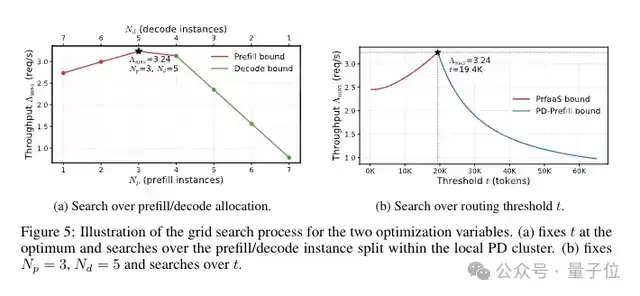
具体实现机制如下:系统设定一个动态调整的长度阈值t。对于短请求(未缓存的上下文长度≤t),整个推理流程仍在本地PD集群内完成。只有当请求的未缓存长度超过阈值t时,才会被路由至专用的PrFaaS集群进行Prefill处理。该阈值t并非静态值,而是根据实时网络带宽状况与请求长度分布进行动态优化,以实现系统整体效率最大化。
整个PrFaaS架构由三个协同工作的核心子系统构成:
第一,计算层。 实现硬件资源的“专精特新”。PrFaaS集群配置H200等高端算力芯片,专门攻克长上下文Prefill这一计算密集型任务;而本地PD集群则采用H20等带宽优化型芯片,专注于Decode及短请求的高并发处理。两类硬件集群可实现独立的弹性伸缩,彻底摆脱了强制配对的资源束缚。
第二,网络层。 采用分层网络设计。集群内部仍使用RDMA网络保证超低延迟通信;而跨数据中心之间,则通过VPC或专线,利用通用的商用以太网传输KV Cache。这种设计显著降低了跨机房、跨地域部署的复杂性与成本。实验数据表明,100Gbps的VPC带宽已完全满足传输需求。
第三,存储层。 这是架构设计中极具巧思的一环。团队设计了一套混合前缀缓存池,将KV Cache分为两类进行管理:一类是prefix-cache块,用于集群内部的高效复用,必须满足块对齐条件才能命中;另一类是transfer-cache块,专门用于跨集群传输,具有临时性,使用后即被释放,不占用宝贵的长期存储资源。
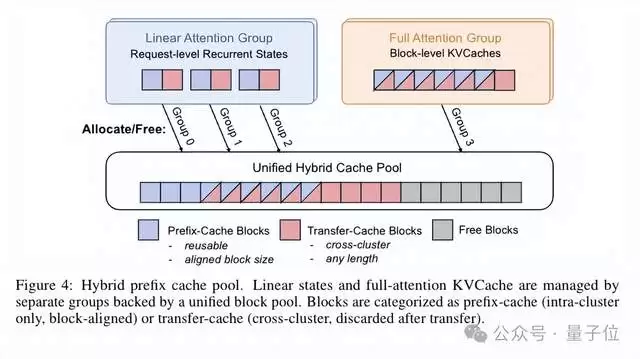
为何采用此种混合管理策略?根源在于混合注意力模型生成的KV Cache本身就是异构的。线性注意力层产生的循环状态是请求级别的,大小固定,必须完全匹配才能复用;而全注意力层产生的KV Cache是块级别的,支持部分前缀匹配。统一的混合池化管理机制,既能最大化本地缓存的复用效率,又能灵活支撑跨集群的传输需求。
此外,为保障生产级服务的稳定性与高可用性,PrFaaS还设计了一套双时间尺度的智能调度算法。简要来说,该系统在短时间尺度(毫秒级)进行基于实时带宽与缓存状态的动态路由决策;在长时间尺度(分钟级)则根据宏观流量模式的变化,动态地重新分配与调整计算资源。
短期调度器会持续监控PrFaaS集群的出口带宽利用率,一旦接近预设阈值,便自动调高长度阈值t,减少跨中心传输的请求数量。对于携带前缀缓存的请求,调度器会综合评估缓存命中位置与当前网络状况,做出最优的路由选择。
长期调度器则负责观测各处理阶段的队列深度与资源利用率。当监测到Prefill阶段成为性能瓶颈时,系统能够动态地将本地PD集群的部分节点从Decode角色切换为Prefill角色;反之亦然。这种弹性的资源重分配机制,使系统具备自适应性,能够平滑应对流量模式的缓慢变迁,始终保持高效率运行。
从蓝图到现实:工程可用性全面验证
任何卓越的架构设计,最终都需通过严苛的工程实验来验证其可行性。研究团队基于真实的生产环境配置,设计了一套完整的对照实验,精准复现了异构硬件、跨域网络与真实长上下文流量交织的复杂场景。
实验采用团队内部自研的1T参数混合注意力模型,其架构设计与Kimi Linear对齐,采用7:1的线性注意力与全注意力混合比例,在确保模型强大能力的同时,实现了对KV Cache的高效压缩。

硬件配置层面,采用了典型的异构组合:负责处理长上下文Prefill的PrFaaS集群部署了32张H200 GPU;本地PD集群则配备了64张H20 GPU,专注于Decode任务与短请求的快速响应。
网络环境层面,通过VPC对等连接模拟跨数据中心互联,提供了约100Gbps的跨集群带宽,这与主流云计算服务商的网络互联方案完全一致。
实验负载采用了截断对数正态分布来模拟真实世界的请求长度,均值约为27K tokens,高度贴近实际长上下文服务的流量特征。

实验结果充分验证了PrFaaS-PD架构的优越性。
在核心性能指标方面,与硬件规模相当的传统同构PD集群相比,PrFaaS架构将服务吞吐量提升了54%;即便与未引入智能调度的简单异构部署方案相比,吞吐量也实现了32%的提升。
在关乎用户体验的延迟指标上,优化效果更为突出,P90首词生成时延(TTFT)降低了64%。这主要归功于长请求被卸载至专用集群处理,避免了与短请求在本地争夺Prefill计算资源,从而极大地缓解了排队阻塞问题。
最令人鼓舞的,是工程可行性的关键数据。PrFaaS集群的平均出口带宽占用稳定在13Gbps左右,在100Gbps的总链路带宽中仅占13%,留下了充沛的带宽余量。这表明KV Cache传输过程完全不会引发网络拥塞或关键链路抢占。实验最终证实,在混合注意力模型与PrFaaS智能调度的协同作用下,KV Cache的跨域传输完全可以摆脱对RDMA网络的依赖,标准的商用以太网即可提供稳定、高效的支撑。
论文核心团队介绍
这项重量级研究由月之暗面与清华大学紧密合作完成。论文作者包括Ruoyu Qin、Weiran He、Yaoyu Wang、Zheming Li、Xinran Xu、Yongwei Wu、Weimin Zheng、Mingxing Zhang(通讯作者)。

其中,Ruoyu Qin(秦若愚)、Weiran He、Yaoyu Wang、Zheming Li、Xinran Xu(许欣然)五位作者来自月之暗面。值得关注的是,这五位研究者同时也是Mooncake分布式推理系统架构的核心贡献者。
本文第一作者秦若愚,是清华大学计算机系MADSys实验室的在读博士研究生,师从通讯作者章明星副教授。章明星副教授长期深耕于KV Cache架构与分布式推理系统领域的研究。同时,秦若愚也在月之暗面参与研发工作,并且是Mooncake系统的第一作者。
月之暗面工程副总裁许欣然也位列作者名单之中。
来自清华大学的作者还包括武永卫教授和郑纬民院士。郑纬民院士是中国工程院院士、清华大学计算机系教授,长期致力于并行与分布处理、大规模数据存储系统等领域的科研与教学工作。

武永卫教授是清华大学计算机科学与技术系副主任、博士生导师,同时担任AI基础设施公司趋境科技的首席科学家。此前,月之暗面与清华大学MADSys实验室联合主导开源的Mooncake项目,趋境科技正是其核心共建与深度贡献单位。
参考文献链接:
[1] https://arxiv.org/abs/2604.15039
[2] https://madsys.cs.tsinghua.edu.cn/people/