
AI浪潮席卷而来,这已是共识。市面上琳琅满目的文本生成工具和智能Copilot,都在反复证明着AI的强大。然而,一个更现实的问题摆在许多设计师面前:这些炫酷的能力,如何才能真正融入自己的项目,为团队提效,而不仅仅是个人玩具?
掌握一两个AI工具做端外提效,或许已经领先了多数人。但真正的价值,在于将能力“接入”产品内部,转化为实实在在的项目生产力。这背后,需要理解一些关键的底层逻辑。OpenAI的GPT模型作为当前自然语言处理的核心技术,其灵活性与强大功能为这种“接入”提供了可能。本文将带你穿透表象,理解GPT模型与OpenAI API的工作原理,让你感知到将技术转化为项目能力的清晰路径。
一、GPT 模型与关键概念
在动手之前,不妨先花点时间,搞懂几个核心概念。这能让你在后续的应用中,知其然更知其所以然。
1. GPT 模型概述
GPT,全称生成式预训练Transformer。顾名思义,它是一种基于Transformer架构、经过海量文本预训练的生成模型。它的工作方式很直观:你给它一段“提示”,它就能据此生成一段连贯的文本响应。从撰写文章、生成代码到创意对话,这种能力让它变得无比通用。
其背后的Transformer架构是关键。不同于过去主流的循环神经网络,Transformer依靠“自注意力”机制,能并行处理整个文本序列。这意味着它在处理长文本时效率更高,也能捕捉更复杂的语义关联。正是这些特性,让GPT在各类语言任务中表现卓越。
2. 嵌入与代币
要想玩转GPT,嵌入和代币是两个绕不开的基础概念。
嵌入,简单说就是让机器“读懂”文本的桥梁。它把文字转换成一系列数字向量,这些向量保留了词语的语义信息。OpenAI提供的文本嵌入模型,就能高质量地完成这种转换,其结果直接用于搜索、聚类等任务,效果的好坏很大程度上取决于嵌入的质量。
代币,则是文本被模型处理前的“最小语义单元”。你可以把它理解为模型眼中的“词语碎片”。比如,“Hello, world!”可能会被拆成[“Hello”, “,”, “world”, “!”]四个代币。这里有个关键点:模型每次能处理的输入和输出总代币数是有上限的,这就是“上下文长度”。因此,理解代币的消耗,对于控制成本、优化提示都至关重要。
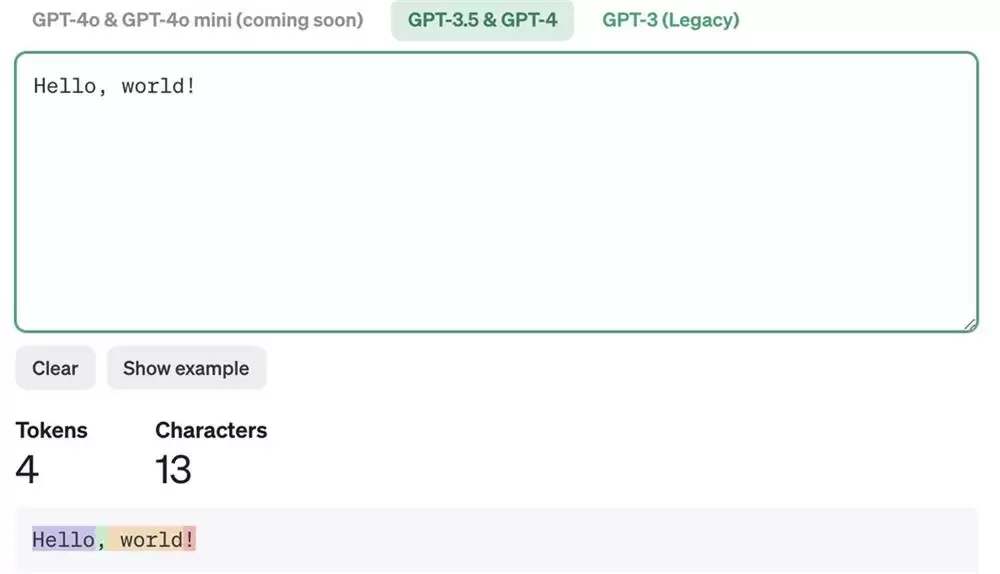
GPT模型采用字节对编码(BPE)进行代币化。它会将频繁共现的字符对合并,形成词汇表。一个词,尤其是长词或专业名词,很可能被拆成多个代币。了解这一点,就能明白为什么有时模型的响应会出乎意料。
另外,不同模型的API调用价格不同,这直接与代币消耗挂钩。选择模型时,除了能力,成本也是一个必须考量的因素。
3. OpenAI API 的工作原理
理解了模型本身,我们来看看如何调用它——这就是API的用武之地。
API基础,你可以把它想象成一个标准化的服务窗口。你无需知道厨房(模型)里如何炒菜,只需按格式点单(发送HTTP请求),就能拿到菜品(模型响应)。OpenAI API让你通过简单的网络请求,就能调用强大的GPT模型,这极大地降低了复杂AI功能的集成门槛。
模型选择与代币管理是实际调用时的两个核心决策。目前,GPT-3.5和GPT-4是主流选择。前者响应快、成本低,适合简单任务;后者在复杂逻辑、长文本连贯性上表现更优,但价格也更高。
代币管理则直接关系到调用能否成功以及成本高低。你需要确保提示词和预期回复的总长度不超过模型的上下文窗口。有几个实用技巧:精简提示词、设置`max_tokens`参数限制输出长度,以及将超长文本分段处理。
二、实际操作:与 OpenAI API 交互
理论说得再多,不如动手一试。下面我们从环境搭建开始,一步步走通调用流程。
1. 安装与验证
首先,你需要一个Python环境。安装OpenAI官方库只需一行命令:
pip install openai
接下来,获取并配置你的API密钥,这是你调用服务的通行证。
import openai # 设置 API 密钥 openai.api_key = 'your-api-key-here' # 发起一次简单请求 response = openai.Completion.create( model="gpt-4", prompt="用一句话解释机器学习。", max_tokens=50 ) # 打印结果 print(response['choices'][0]['text'].strip())
2. 发出请求与解析响应
一次成功的API调用会返回一个结构清晰的JSON响应。你需要关注这几个部分:
id: 本次调用的唯一标识。choices: 核心所在,生成的文本就在choices[0]['text']里。usage: 详细记录了本次调用消耗的提示代币、完成代币和总代币数,是成本核算的依据。
解析响应本质上就是从返回的JSON对象中提取出你需要的信息。
3. 提示工程:制作有效提示
同样的模型,不同质量的提示词,得到的结果可能天差地别。这就是提示工程的魅力。几个行之有效的策略包括:
- 指令明确:模糊的问题得到模糊的回答。将“写点关于巴黎的东西”改为“以旅行博主的身份,用三个短句介绍巴黎最值得去的三个地标”,效果立竿见影。
- 分步引导:对于复杂任务,拆解步骤。例如,先让模型列出文章大纲,再针对每部分生成内容。
- 提供上下文:在对话中,通过系统消息设定角色(如“你是一位资深架构师”),能让回复更专业、更贴合场景。
- 控制格式:明确要求输出格式,如“请以JSON格式返回”或“用项目符号列表展示”。
response = openai.Completion.create( model="gpt-4", prompt="请用三点总结人工智能的未来发展趋势,每点不超过20字:", max_tokens=100, temperature=0.7 # 控制创造性,越低越确定 ) print(response['choices'][0]['text'].strip())
三、实战示例:创建定制化 AI 袋里
掌握了基础调用,我们就可以尝试构建更有趣的东西——一个能集成到项目中的AI袋里。
1. 从简单到复杂的 AI 袋里
一切可以从一个基础的对话机器人开始。利用ChatCompletion接口,我们可以轻松维护一个带上下文记忆的对话袋里。
import openai
openai.api_key = 'your-api-key'
def initialize_agent():
return [{"role": "system", "content": "你是一个有帮助的AI助手。"}]
conversation_history = initialize_agent()
def send_message(history, user_msg):
history.append({"role": "user", "content": user_msg})
response = openai.ChatCompletion.create(
model="gpt-4",
messages=history
)
assistant_msg = response['choices'][0]['message']['content']
history.append({"role": "assistant", "content": assistant_msg})
return assistant_msg
# 测试对话
reply = send_message(conversation_history, "推荐几本设计相关的经典书籍?")
print(reply)
让这个袋里变得更强大的方法,是赋予它“手脚”——集成外部API。例如,增加查询天气的功能:
import requests
def get_weather(city):
# 这里假设调用一个天气API
api_key = "your_weather_api_key"
url = f"https://api.weatherapi.com/v1/current.json?key={api_key}&q={city}"
resp = requests.get(url).json()
condition = resp['current']['condition']['text']
temp = resp['current']['temp_c']
return f"{city}天气:{condition},气温{temp}摄氏度。"
def smart_agent(history, user_msg):
if "天气" in user_msg:
# 简单提取城市名(实际应用需更健壮的解析)
city = user_msg.replace("天气", "").strip()
weather_info = get_weather(city)
return weather_info
else:
return send_message(history, user_msg)
# 测试
print(smart_agent(conversation_history, "北京天气怎么样?"))
2. 使用工具和高级功能
OpenAI还提供了更强大的工具,如代码解释器和文件检索,能让你的袋里如虎添翼。
代码解释器模式允许模型在沙箱中运行代码并返回结果,非常适合进行数据计算或格式转换。
文件检索功能则能让模型基于你提供的文档内容进行回答,相当于为袋里装上了“专属知识库”。这在处理长文档、内部资料查询时非常有用。
结论
从理解GPT的核心概念,到掌握API的调用方法,再到亲手构建一个具备扩展能力的AI袋里,我们完成了一次从理论到实践的旅程。技术本身在快速迭代,但底层逻辑——如何将大模型的能力通过API标准化地集成到业务流中——是相对稳定的。
对于设计师而言,理解这些逻辑,甚至掌握一些基础的代码能力,绝非为了转行,而是为了能与技术团队更高效地对话,共同推动AI功能在项目中的落地。无论是开发者还是设计师,在当下,学习和应用OpenAI API已成为解锁新可能性的关键技能。希望本文提供的路径,能帮助你跨出从“使用AI工具”到“构建AI能力”的关键一步。未来的应用场景只会更加广阔,探索才刚刚开始。




