对于追求数据自主与隐私安全的苹果用户而言,将Mac打造成一台完全本地化的私有AI服务器,正从理想变为触手可及的现实。借助M4芯片的强大算力,你现在可以在自己的设备上离线运行AI模型,彻底摆脱对互联网连接、月度订阅费用以及第三方数据窥探的依赖。无论是进行深度研究、复杂项目规划还是高效编程,直接在本地硬盘上处理任务,都代表了Mac用户体验的又一次飞跃,将数据控制权与计算自由真正交还到用户手中。

本地AI部署:平台与模型的选择挑战
然而,构建本地AI服务器的第一步,就面临着工具与平台选择的迷宫。是选择Ollama、llama.cpp还是LM Studio?每个运行框架都有其特定的优势、兼容性与学习曲线,且支持的模型库也各不相同。这仅仅是入门挑战。更核心的难题在于,如何为你的Mac设备(例如配备24GB统一内存的机型)筛选出合适的AI模型——它必须能在有限的内存中高效运行,同时为macOS系统及其他应用程序保留充足的资源,确保整体体验流畅无阻。
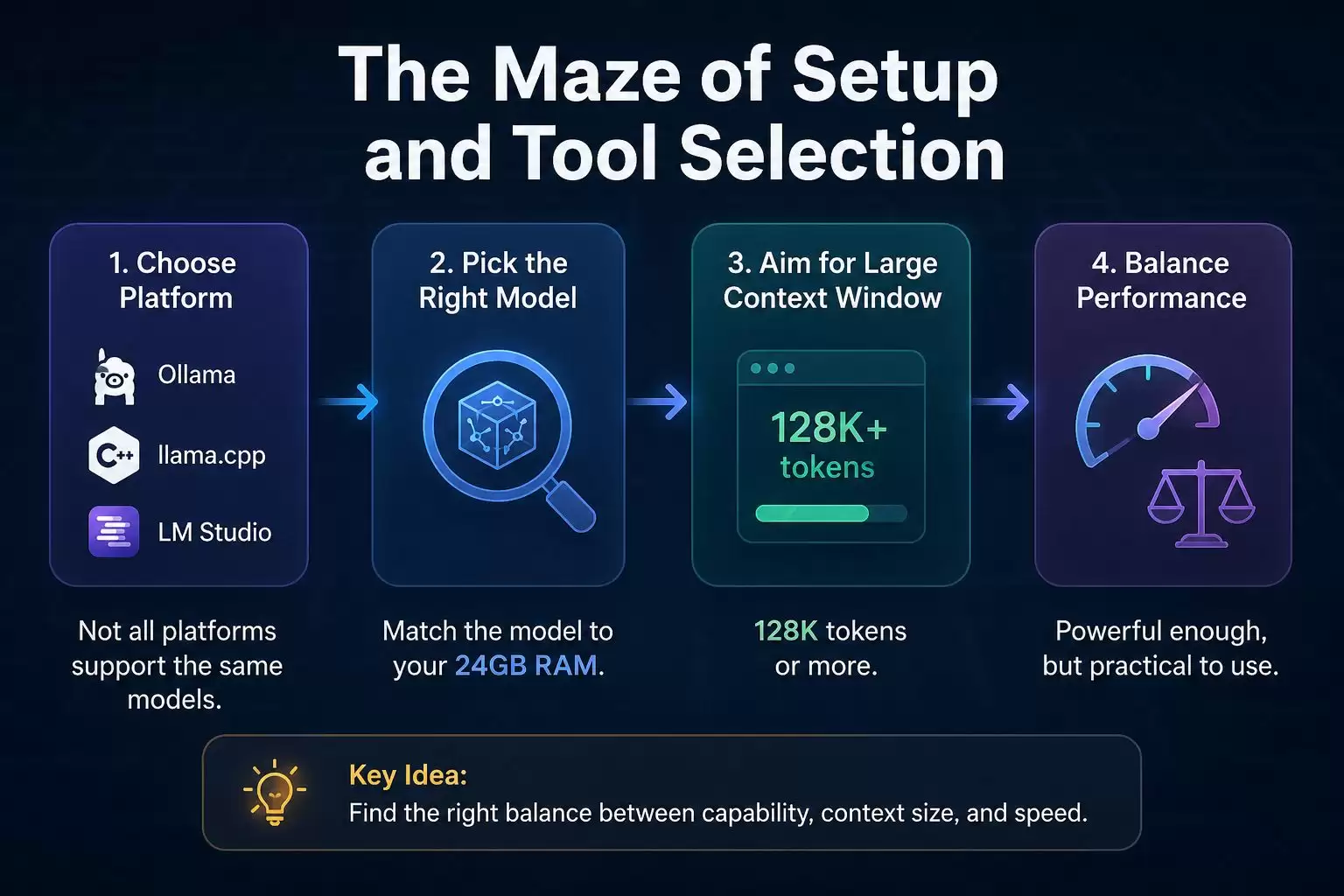
本次实践的核心目标,是寻找一个支持大上下文窗口(理想情况下达到128K词元)的本地模型。初步测试显示,像Qwen 3.6或GPT-OSS 20B这类较大模型,虽可在24GB内存中加载,但推理速度缓慢,实用性不足;而Gemma 4B等更轻量的模型,则在处理复杂工具调用和多步骤任务时能力有限。那么,在MacBook Pro上实现性能与效率的黄金平衡点究竟在哪里?
性能与效率的平衡点:Qwen 3.5-9B模型实测
经过多轮严格的性能测试与对比评估,qwen3.5-9b@q4_k_s模型脱颖而出,成为24GB内存MacBook Pro上本地AI部署的理想选择。在开启“思考模式”后,其推理速度可稳定在每秒40个令牌左右,并能流畅调用各类编程与工具使用API。尽管与参数规模庞大的云端大模型相比,它在某些创意发散任务上可能略有差距,但考虑到这是在完全离线、无网络延迟的笔记本电脑上实现的智能,其综合表现已足够出色,足以胜任大多数研究与开发辅助工作。

为了在代码生成、逻辑推理等要求精确度的任务中获得最佳效果,对模型参数进行针对性微调至关重要。例如,将温度参数(temperature)设置为0.6左右,并启用top_p=0.95等采样策略,可以有效平衡输出的创造性与一致性。这些关键参数的调整,往往直接决定了最终产出的是高质量、可用的代码解决方案,还是陷入逻辑混乱的循环。
构建人机协同的交互式AI工作流
需要明确的是,像Qwen 3.5-9B这样的本地大模型,目前尚无法像ChatGPT等顶尖云端模型那样,仅凭单一指令就生成完整的应用程序。它们更擅长扮演“增强智能”的角色,支持一种交互式、迭代式的工作流程。在这种模式下,用户始终是决策的主导者,将本地AI作为强大的实时研究助手、代码审查伙伴或复杂概念的即时解释器来使用。
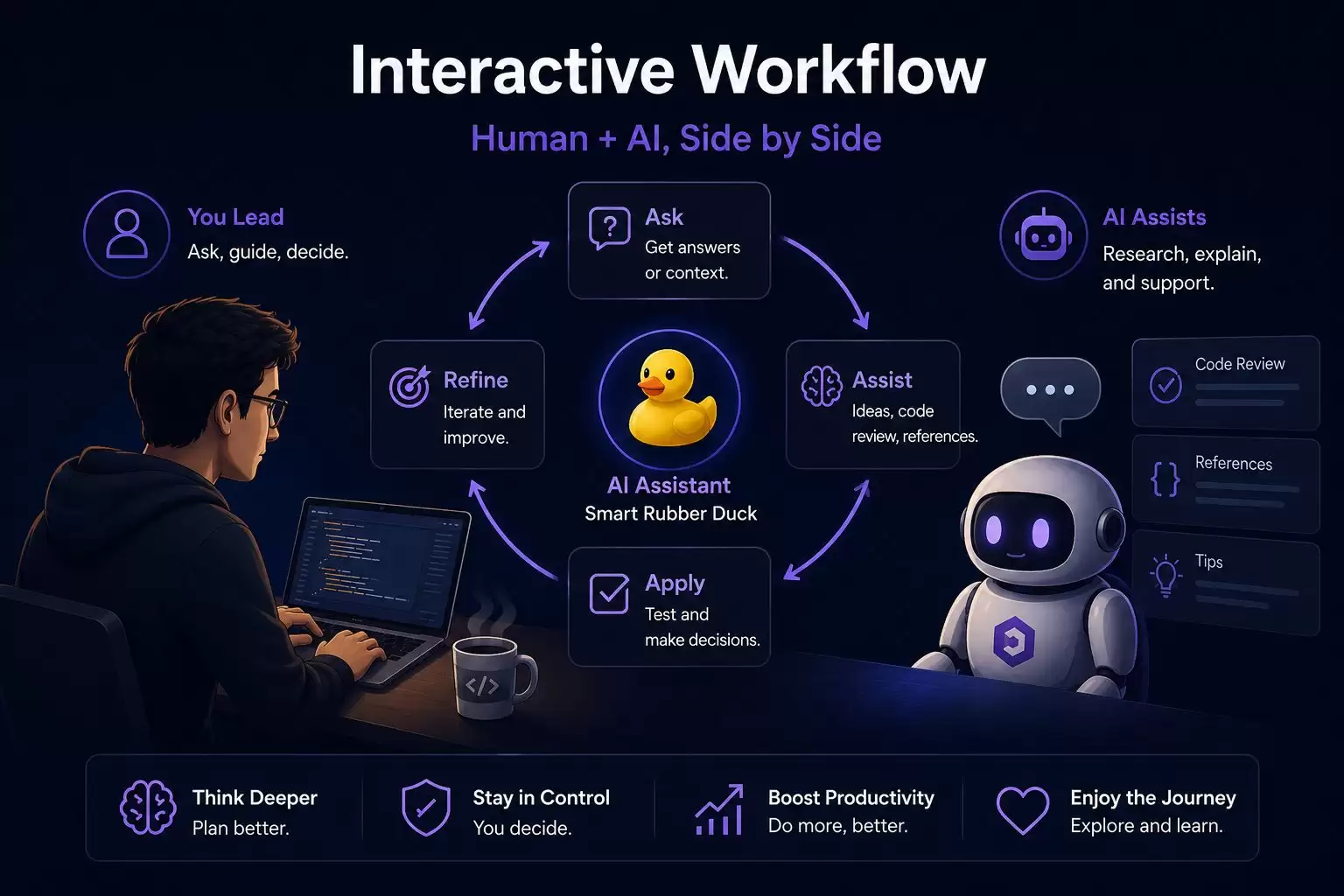
这种人机协同模式要求用户进行更主动的思考与任务规划,但反过来也促使你更深入地理解问题本质与技术细节。你不是将思考过程完全外包,而是借助一个本地的、私有的强大工具来拓展自身能力,同时全程掌控项目的每一个环节。这带来了一种更可持续、也更令人安心的技术使用体验,让我们重新找回驾驭工具、探索可能性的初心与乐趣。




