盛大AI研究院实现虚拟人流式生成:1帧延迟动作丝滑如真人
文本驱动的人体动作生成技术,是赋予游戏NPC、虚拟数字人乃至智能机器人自然行为表现的关键。然而,现有方案在生成动作的流畅度与实时性上往往难以兼顾,效果不尽如人意。
当前,以MDM、MoMask为代表的非流式生成模型,在获得完整文本描述后能合成高质量动作序列。但其“一次性”生成的模式,无法满足实时交互场景中“边说边动”的连续需求。若简单拼接多段生成结果,则会导致动作僵硬、衔接延迟显著。
现有的流式生成方案同样面临瓶颈。一类如PRIMAL,采用分块扩散策略,需等待上下文窗口填满才能启动,首帧延迟问题突出;另一类如MotionStreamer,基于自回归模型加扩散头,难以有效利用长期历史信息。更关键的是,这些方法普遍存在训练与推理模式的不匹配问题,通常依赖手动检测提示词变化并刷新生成过程,引入了额外的不稳定性。
为攻克这些难题,盛大AI研究院(东京)与东京大学的研究团队创新性地提出了FloodDiffusion。这是首个基于定制化扩散强制框架的流式人体动作生成系统。其核心突破在于,能够根据连续输入的文本指令流,以近乎零延迟的方式,生成过渡平滑、与指令精准对齐、且理论上无限长的动作序列。此项重要研究成果已被CVPR 2026会议选为Highlight论文。


△FloodDiffusion流式生成效果演示:根据随时间变化的文本提示(如先“抬腿”后“深蹲”),实时生成平滑连续的人体动作
三大核心改进:定制化扩散强制框架
为使扩散模型适应流式生成,FloodDiffusion对原有扩散强制框架进行了三项关键性改造。
改进一:下三角噪声调度策略
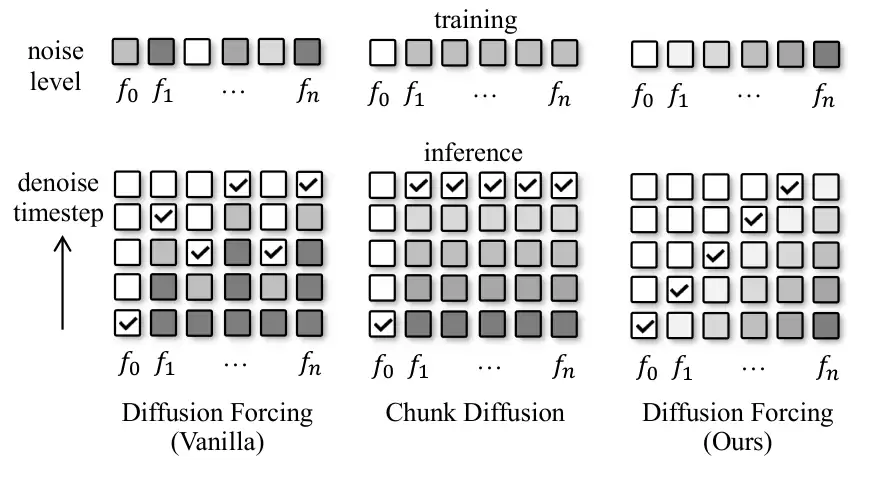
△噪声调度策略对比:原始扩散强制(随机调度)、分块扩散(均匀调度)与FloodDiffusion(下三角调度)
原始扩散强制方法为序列中每一帧随机分配噪声时间步,导致训练与推理噪声分布不一致。FloodDiffusion创新性地采用了一种确定性的“下三角”噪声调度。简言之,在任何时刻,序列中仅有一个固定大小的“活动窗口”处于活跃去噪状态:窗口前的帧已完成生成,窗口后的帧仍为纯噪声。
这一设计从数学上保证了关键特性:在流式推理时,每一帧的生成质量与使用完整序列的扩散模型完全一致。同时,模型计算仅局限于活动窗口内,实现了恒定的计算开销,并将流式延迟成功控制在仅1帧的水平。
改进二:滑动窗口内的双向注意力机制
区别于视频生成中常用的因果注意力,FloodDiffusion在滑动窗口内部启用了双向注意力。这是因为窗口内不同帧可能处于不同的去噪阶段,当前帧需要充分“看到”窗口内所有可用的上下文信息,才能依据最新文本提示进行精准去噪。若使用因果掩码,将丢弃这些宝贵信息,导致生成质量严重下降。
改进三:连续时变文本条件注入
传统流式系统依赖“显式刷新”机制:检测到新指令后,需中断生成、清空缓存再重启。FloodDiffusion摒弃了这种低效方式,采用逐帧注入文本条件的方法。它利用预训练的T5文本编码器提取特征,通过旋转位置编码与动作token对齐,并在注意力层中通过偏置掩码确保每一帧仅关注其对应时刻的文本提示。
这一设计使模型能够自适应地融合新指令,无需在推理时进行复杂优化,即可实现如“行走”到“奔跑”等动作间的自然无缝切换。值得注意的是,同一文本提示在不同时机输入,可产生不同的动作响应,这充分展现了模型对时序信息的精确理解能力。
网络架构设计
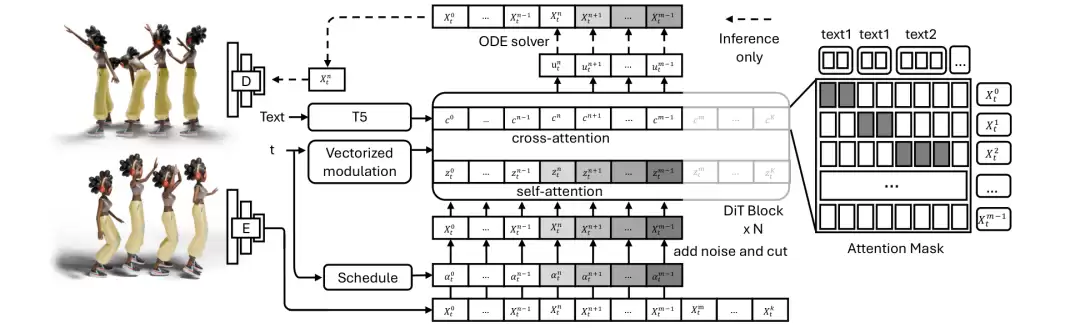
△FloodDiffusion整体框架:263维动作序列经因果VAE编码至4维隐空间,在活动窗口内进行扩散去噪,并逐帧解码输出
FloodDiffusion采用隐空间扩散框架。高维的原始动作序列(263维)首先通过一个因果VAE,被压缩编码为紧凑的4维隐空间表示。扩散过程仅在隐空间中进行,这大幅降低了计算负担和流式延迟,使去噪器能更专注于时序动态的建模。
模型在活动窗口[m(t), n(t))内预测隐变量的速度场,其条件依赖于上下文[0, n(t))内的历史帧及对应文本。推理时,窗口逐帧滑动,生成的隐变量被实时解码为动作输出,从而实现真正的端到端流式生成。
因果变分自编码器
与常见非流式方法使用的双向卷积VAE或VQ-VAE不同,FloodDiffusion采用严格因果设计的VAE:解码器在时刻t不依赖任何未来帧信息。其架构基于视频生成模型Wan2.1中的因果VAE,并将所有时空模块适配为适用于一维时序动作数据。训练时使用L2重建损失及标准承诺/码本损失,时间下采样因子为4,隐空间通道维度为4。
DiT去噪骨干网络
隐空间去噪器基于扩散Transformer架构,采用共享的时间嵌入路径。使用均匀时间步采样,并将流匹配时间偏移设置为1,以适配下三角调度策略。文本条件逐帧施加,由T5编码器(最大长度128)提取的token特征,通过旋转位置编码与当前时刻的动作token对齐,并在自注意力层中通过偏置掩码确保每帧仅关注当前激活的文本指令。
实验与分析
定量性能评估
在权威的HumanML3D基准测试中,FloodDiffusion取得了FID 0.057的卓越成绩。该指标不仅大幅领先现有流式模型PRIMAL(FID 0.511)和MotionStreamer(FID 0.092),甚至逼近了SOTA非流式模型MoMask(FID 0.045)的水平。在衡量文本-动作对齐度的关键指标上,其R-Precision@1/2/3分别达到0.523/0.717/0.810,MM-Dist为2.887,在所有对比方法中均位列第一。
在专为流式场景设计的BABEL数据集评估中,FloodDiffusion在过渡平滑度指标上同样全面领先:Peak Jerk为0.713(最接近真实数据的1.100),Area Under Jerk为14.05,显著优于PRIMAL(PJ 1.304, AUJ 19.36)和MotionStreamer(PJ 0.912, AUJ 16.57)。
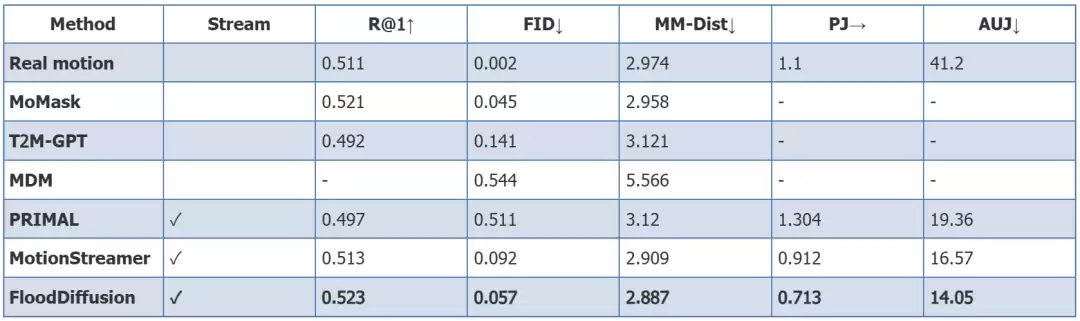
△HumanML3D与BABEL数据集上的定量评估结果(粗体为FloodDiffusion)
用户主观研究
一项包含100名参与者的盲测用户研究,采用Bradley-Terry模型对三个生成模型与真实动作进行偏好评分。结果显示,FloodDiffusion在“动作质量”、“过渡自然度”和“指令一致性”三个维度上,均显著优于PRIMAL和MotionStreamer。尤其在“过渡自然度”上,其得分(0.152)已非常接近真实动作数据(0.299)。
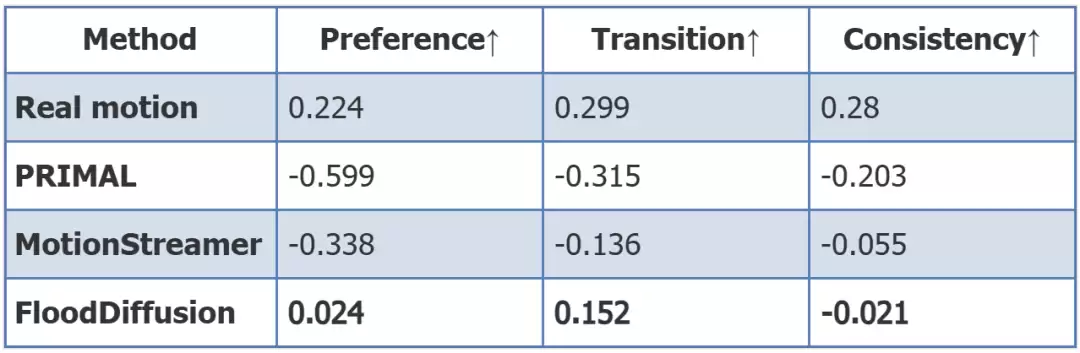
△基于Bradley-Terry模型的用户研究结果(100名参与者)
消融实验验证
消融实验有力证明了核心设计的不可或缺性:
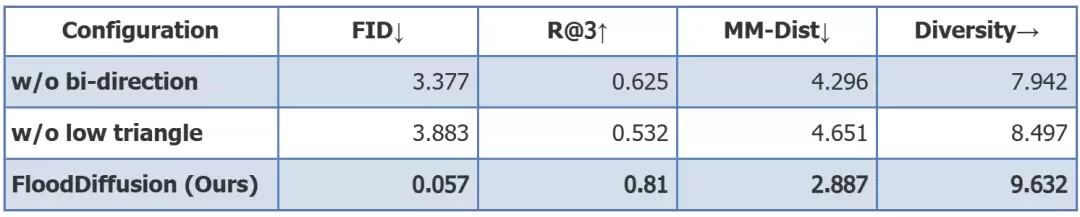
△核心设计消融实验:移除任一项改进均导致性能大幅下降
若移除双向注意力(仅用因果注意力),FID会从0.057飙升至3.377,R@3从0.810降至0.625;若移除下三角调度(改用随机调度),FID会从0.057飙升至3.883,R@3从0.810降至0.532。任何一项改进的缺失都会导致模型性能断崖式下滑,证明了这些定制化改造对于动作生成任务的决定性作用。
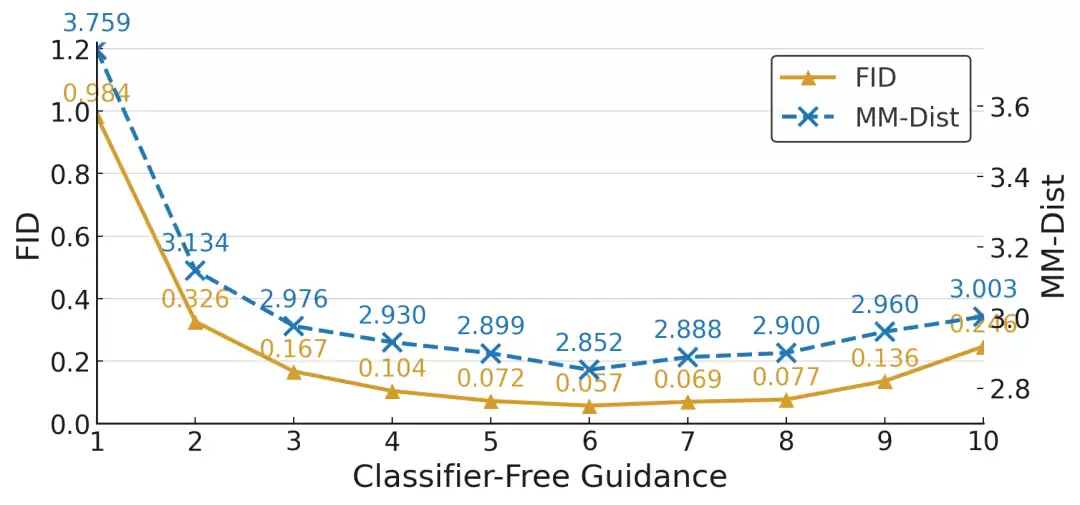
△无分类器引导强度对FID和MM-Dist指标的影响,最优CFG=6
生成效果展示
时变条件响应能力:

△时变条件对比:同一文本提示在不同时刻输入,模型生成不同的动作结果,体现其对时序信息的精确感知
FloodDiffusion能够根据文本提示输入的时机,生成差异化的动作结果。如上图所示:(左上)两个提示词在不同帧输入,模型依次响应生成对应动作;(右上)同样的提示词作为单一输入一次性给出,模型则生成一个融合动作;(左下)两个提示词在序列前期输入;(右下)同样的提示词在序列后期输入——模型对时序信息的精确感知,使其能在不同上下文下产生合理且多样的输出。
长序列生成与控制:

△长序列生成行为:无新指令时重复当前动作(左),可通过“站立”等指令主动停止(右)
在生成长序列时,FloodDiffusion展现出两种典型行为:(左)当没有新提示词输入时,模型会持续重复执行当前指令对应的动作;(右)在实际交互中,可通过显式给出静止类指令(如“stand”)来优雅地终止当前动作,实现灵活可控的交互体验。
总结与展望
FloodDiffusion首次成功将扩散强制框架应用于流式人体动作生成领域。通过下三角噪声调度、窗口内双向注意力以及连续时变文本调节这三项关键改造,它从根本上解决了原始框架在处理时序动作数据时易出现的分布坍塌问题。该框架实现了训练与推理的一致性,无需在推理时进行手动干预,具备恒定的计算开销与极低的响应延迟,为实时交互游戏、虚拟数字人驱动以及机器人运动控制等场景,提供了一个高性能的流式动作生成解决方案。
未来工作将探索如何融合音频、触觉力反馈、环境上下文等多模态时变条件,进一步拓展其应用边界与表现能力。
相关攻略

HermesAgent是一款开源自主AI智能体框架,定位为可持久运行、自我进化的“数字员工”。它以任务完成为导向,通过四层架构处理信息、操作文件、执行终端命令及自动化浏览器,支持六种部署方式,并通过统一网关接入微信等多平台。其关键特性在于能从任务经验中自动提炼并复用技能,实现持续进化,越用越。

近期,世界模型领域动态频频,竞争日趋白热化。 李飞飞教授创立的具身智能公司 World Labs 高调发布了「Spark 2 0」模型;几乎同时,阿里巴巴也推出了自家的世界模型「快乐生蚝」。此外,Physical Intelligence 公司发布了新模型 π 0 7,重点强调了其在未见任务上的组合

近日,2026北京亦庄机器人半程马拉松赛事现场,一款造型独特的机器人意外成为焦点,在网络上引发了广泛讨论。这款被网友昵称为“豆脚”的机器人,以其极具辨识度的外观和有趣的行走姿态,迅速走红。 “豆脚”机器人的创意来源于抖音平台的虚拟IP“豆包”。其创作者、抖音博主“同济子豪兄”基于高擎动力的小派机器人

“跑马拉松的机器人和我们,完全是两个领域。我们和做语言模型的公司,距离反而更近。” 就在不久前,一场机器人马拉松吸引了无数目光。那些拥有刀锋般双足的机器人,跑出了超越人类的速度。然而,在自变量科技CEO王潜看来,这更多是硬件能力的展示,而真正的战场,在于“大脑”。 “硬件在中国,从来都不是壁垒。今天

FigureAI三台人形机器人在物流仓库进行了超40小时全自主分拣直播,处理数千件包裹并自主充电交接。直播旨在回应对其实用性的质疑,展示其在工业场景中的稳定性与操作能力。尽管其自适应抓取与异常处理表现突出,完全自主性仍存争议。目前国内外多家公司已在物流领域部署类似机器人。
热门专题







热门推荐

今年三月,谷歌DeepMind高级科学家Alexander Lerchner发表了一篇重磅论文,其核心结论清晰而深刻:基于算法的符号操作在结构上注定无法产生真正的意识——无论未来模型规模如何庞大、架构如何精巧,甚至是否为其配备仿生身体,这一根本性限制或许都无法被跨越。 仔细审视这一论断,它并非一个关

研究针对AI助手难以执行复杂屏幕操作的问题,构建了CUActSpot评测基准,通过代码渲染自动生成含精确坐标的多样化训练数据,并训练了一个40亿参数模型。实验表明,提升训练数据多样性比单纯扩大数据规模更能有效增强模型通用操作能力,并展现出跨任务泛化潜力。


《迷你世界》于2026年5月15日发布全新激活码,玩家可凭兑换码领取酷炫角色装扮、迷你币及稀有道具,请及时复制有效激活码前往游戏内使用。

《我的世界》于2026年5月17日发布免费兑换码EMMMyxhjVHMApsb2,可兑换游戏道具与装饰。兑换码常有时间或次数限制,请尽快使用。更多兑换码可查看官方汇总页面。